문제출처 : https://www.hackerrank.com/challenges/challenges/problem?isFullScreen=true
Q)
Julia asked her students to create some coding challenges. Write a query to print the hacker_id, name, and the total number of challenges created by each student. Sort your results by the total number of challenges in descending order. If more than one student created the same number of challenges, then sort the result by hacker_id. If more than one student created the same number of challenges and the count is less than the maximum number of challenges created, then exclude those students from the result.
줄리아는 학생들에게 코딩 문제를 만들도록 요청했습니다. 쿼리를 작성하여 각 학생이 만든 챌린지의 총 개수, 이름 및 해커 아이디를 출력합니다. 총 챌린지 수를 기준으로 결과를 내림차순으로 정렬합니다. 두 명 이상의 학생이 같은 수의 도전을 생성한 경우, 결과를 hacker_id로 정렬합니다. 두 명 이상의 학생이 같은 수의 챌린지를 생성했고 그 수가 생성된 최대 챌린지 수보다 적은 경우 해당 학생을 결과에서 제외합니다.
Input Format
The following tables contain challenge data:
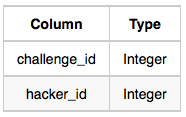
Hackers: The hacker_id is the id of the hacker, and name is the name of the hacker.

Challenges: The challenge_id is the id of the challenge, and hacker_id is the id of the student who created the challenge.
A)
문제자체를 읽고 한번에 이해하기가 힘들어 샘플로 주어진 예시를 참고해서 이해해보는게 좋은것 같다 ( hackerrank 문제자체가 나로썬 이해가 어려운 문제가 좀 많은듯 .. )
우선 예시를 살펴보면 다음과 같다.
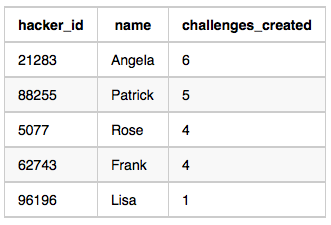
Students 5077 and 62743 both created challenges, but the maximum number of challenges created is so these students are excluded from the result.
예시의 상황을 따르면 challenges_created 의 수가 최대수 보다 작은 경우 중복은 제거하고, 여기선 예시를 생략했지만 문제에 따르면 최대수인 경우는 제거하지 않고 그대로 출력하는 문제이다.
자 그럼 이제 challenges_created 의 개수를 구하고, 그 개수가 중복이면서 최대수가 아닌경우 제거하고, 중복이면서 최대수라면 조회하도록 하는 문제임을 알았다.
문제를 알았으니 가장 먼저 해야하는 일은 challenges_created 가 중복되지 않고 1개만 존재하는 레코드들을 조회하여 중복이 없는 문제를 조회해보자.
SELECT SUB2.CHALLENGES_CREATED
FROM
(
SELECT HACKER_ID, COUNT(*) CHALLENGES_CREATED
FROM CHALLENGES
GROUP BY HACKER_ID
) SUB2
GROUP BY SUB2.CHALLENGES_CREATED
HAVING CHALLENGES_CREATED = 1 해당 쿼리를 살펴보면 서브 쿼리는 한 학생이 제작한 문제의 개수를 구하는 쿼리이다.
외부 쿼리는 서브 쿼리의 결과에서 제작문제의 수를 그룹으로 하여 동일한 문제의 수를 제작한 학생의 수를 구하고, 동일한 문제의 수를 제작하지 않은 경우만 가져오는 쿼리이다.
예시와 함께 살펴보자 우선 서브쿼리의 결과를 살펴보면 다음과 같은 결과가 나올거다.
| hacker_id | challenges_created |
|---|---|
| 1 | 8 |
| 2 | 12 |
| 3 | 20 |
| 4 | 20 |
| 5 | 24 |
그렇다면 이러한 결과에서 외부쿼리는 다음과 같은 결과를 얻을 수 있다.
| challenges_created | count(*) --여기는 실제로는 생략되는 부분 |
|---|---|
| 8 | 1 |
| 12 | 1 |
| 24 | 1 |
이처럼 위 쿼리를 통해 동일한 개수만큼 문제를 생성한 경우 결과에서 제외하는 방법은 이러한 방법으로 확인,제거할 수 있다.
그렇다면 다음으론 가장 많이 제작된 문제의 개수를 구하는 과정이다.
SELECT MAX(SUB1.CHALLENGES_COUNT)
FROM
(
SELECT COUNT(*) AS CHALLENGES_COUNT
FROM HACKERS H
INNER JOIN CHALLENGES C ON H.HACKER_ID = C.HACKER_ID
GROUP BY H.HACKER_ID
)SUB1이제 그렇다면 최종적으로 위에서 다룬 쿼리의 조건을 만족시키는 challenges_created를 갖는 hacker_id, name 을 출력하고, challenges_created 기준으로 내림차순, 동일한 수를 가진다면 hacker_id 를 기준으로 오름차순 해줌으로써 문제를 해결할 수 있다.
전체적인 답안은 다음과 같이 작성될 수 있다.
SELECT H.HACKER_ID, H.NAME, COUNT(*) AS CHALLENGES_CREATED
FROM HACKERS H
JOIN CHALLENGES C ON H.HACKER_ID = C.HACKER_ID
GROUP BY H.HACKER_ID, H.NAME
HAVING CHALLENGES_CREATED
IN
(
SELECT SUB2.CHALLENGES_CREATED
FROM
(
SELECT HACKER_ID, COUNT(*) AS CHALLENGES_CREATED
FROM CHALLENGES
GROUP BY HACKER_ID
)SUB2
GROUP BY SUB2.CHALLENGES_CREATED
HAVING COUNT(*) = 1
)
OR CHALLENGES_CREATED =
(
SELECT MAX(SUB1.CHALLENGES_CREATED)
FROM
(
SELECT COUNT(*) AS CHALLENGES_CREATED
FROM CHALLENGES
GROUP BY HACKER_ID
)SUB1
)
ORDER BY CHALLENGES_CREATED DESC, HACKER_ID;문제 자체가 쉽다고 생각하여 풀이를 시작했는데 생각보다 풀이에 오랜시간이 걸렸고, 결국 다른 사람들이 풀이한 문제를 여럿 참고하고 내가 가장 읽기 쉽고 이해하기 쉬운 해답을 사용하여 문제를 해결하였다. WINDOW FUNCTION 을 사용하여 문제를 해결한 경우도 있었고 쿼리도 훨씬 간결하여 해당 쿼리가 가장 눈에 띄었지만 아직 WINDOW FUNCTION을 사용해본 경험이 없어 바로 이해하기란 쉽지 않았다
서브 쿼리에도 익숙해질겸 위 답안을 통해 문제를 해결하고, 서브쿼리 사용방법도 익힐 수 있는 좋은 문제였다.
내가 답안을 참조한 글은 다음 블로그이다.
