문제출처 : https://www.hackerrank.com/challenges/sql-projects/problem?isFullScreen=true
Q)
You are given a table, Projects, containing three columns: Task_ID, Start_Date and End_Date. It is guaranteed that the difference between the End_Date and the Start_Date is equal to 1 day for each row in the table.

If the End_Date of the tasks are consecutive, then they are part of the same project. Samantha is interested in finding the total number of different projects completed.
Write a query to output the start and end dates of projects listed by the number of days it took to complete the project in ascending order. If there is more than one project that have the same number of completion days, then order by the start date of the project.
Sample Input
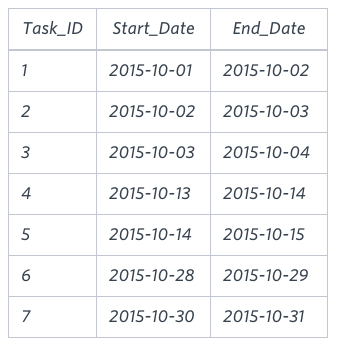
Sample Output
2015-10-28 2015-10-29
2015-10-30 2015-10-31
2015-10-13 2015-10-15
2015-10-01 2015-10-04A)
해당 문제는 다음과 같은 규칙과 요구조건을 가지고 있다.
- Start_Date 와 End_Date 는 1일 차이를 두고 하나의 레코드에 기록되어 있다.
- End_Date 가 연속적인 경우 동일한 프로젝트를 진행한 것, 예를들어 task1~3 은 연속된 End_Date 를 가지고 있어 동일한 프로젝트를 진행한 것을 표현한 것이다.
- 프로젝트를 완료한 건을 시작날짜,종료날짜 를 기준으로 오름차순 정렬하고, 완료일자가 같을경우 시작일자를 기준으로 정렬하여 조회한다.
나는 해당 문제를 보고 연속된 날짜를 어떻게 잡아내야 할 지 방법에 대해서 고민을 계속해봤지만 쉽게 방법에 다다르지 못했다. 그래서 Discussions 탭을 참고하고, 구글링을 통해서 다른분들의 답안을 보고 참고하여 해결했다.
대부분의 구글링 결과 해당 문제는 알고리즘(?) 성격의 문제였고 대략적으로 요약하면 다음과 같은 조건을 전제로 문제를 CROSS JOIN 하여 풀이를 하는 방법이였다.
- start_date 중 end_date 에 없는 start_date는 연속적이지 않고,개별적으로 시작하는 프로젝트의 시작된 날짜를 의미한다.
- end_date 중 start_date 에 없는 end_date는 연속적이지 않고, 개별적으로 시작하는 프로젝트의 종료날짜를 의미한다.
풀이 방법은 다른 블로그에 많기도 하고, 위 방법을 풀기보다 다른 방법으로 풀 수 없을까 하여 좀 찾아보다가 개인적으로 공부할 수 있는게 많은 것 같은 답안을 찾아서 해당 답안을 기준으로 하나씩 어떻게 풀이해나갔는지 알아보고자 한다.
우선 쿼리부터 살펴보자.
WITH ordered_dates AS(
-- List all dates by start date to start with, and compute the next start as well as the previous end date for each row
SELECT *,
LEAD(Start_Date) OVER(ORDER BY Start_Date) AS next_start_date,
LAG(End_Date) OVER(ORDER BY Start_Date) AS previous_end_date
FROM Projects
ORDER BY Start_Date
),start_dates AS (
-- Make a list of of all start dates that start a project. A row where there's more than 0 days between the current start date and the previous end date means there's a gap, therefore a new project.
SELECT Start_Date,
ROW_NUMBER() OVER (ORDER BY End_Date) AS RowNum,
DATEDIFF(Start_Date,previous_end_date)
FROM ordered_dates
WHERE DATEDIFF(Start_Date,previous_end_date) > 0 OR previous_end_date IS NULL
),end_dates AS (
-- Make a list of all end project end dates. An row that has a gap betwee the next start date and the current end date is the end of a project
SELECT
ROW_NUMBER() OVER (ORDER BY Start_Date) AS RowNum,
End_Date,
DATEDIFF(next_start_date,Start_Date)
FROM ordered_dates
WHERE DATEDIFF(next_start_date,End_Date) > 0 OR next_start_date IS NULL
)
-- Putting it all together
SELECT start_dates.Start_Date,end_dates.End_Date FROM
start_dates
INNER JOIN end_dates ON start_dates.RowNum = end_dates.RowNum
ORDER BY DATEDIFF(end_dates.End_Date,start_dates.Start_Date);앞 서 다룬 시작일,종료일 조건을 통한 CROSS JOIN 을 사용한 풀이보다 훨씬 길이가 길지만
개인적으로 잘 사용하지 않았던 명령어들에 대해 공부해볼만한 것 같다.
이제 하나씩 다뤄보자.
WITH AS 그리고 CTE
CTE( Common Table Expression ) 란 서브쿼리로 쓰이는 파생테이블과 비슷한 개념으로 대표적으로 CTE와의 비교대상은 VIEW가 있다.
VIEW는 만들기 위해 권한이 필요하고 사전에 정의를 해야한다. 반면, CTE는 권한이 필요 없고 하나의 쿼리문이 끝날때까지만 지속되는 일회성 테이블이다.
CTE는 주로 복잡한 쿼리문에서 코드의 가독성과 재사용성을 위해 파생테이블 대신 사용하기에 유용하다.
CTE에는 재귀적 CTE와 비재귀적 CTE가 있지만 여기서는 다루지 않는다.
이러한 CTE 방법을 사용하는 대표적인 방법 중 하나는 WITH 테이블_이름 AS ( SELECT ... ) 구문이다.
따라서 위 쿼리의 상단부분은 CTE 로 문제 풀이용 일회용 테이블을 만들어 활용하는 쿼리이다.
그렇다면 위에서 CTE 방식을 이용해 생성한 일회성 테이블들을 하나씩 알아보자.
WITH ordered_dates AS (
SELECT *,
LEAD(Start_Date) OVER(ORDER BY Start_Date) AS next_start_date,
LAG(End_Date) OVER(ORDER BY Start_Date) AS previous_end_date
FROM Projects
ORDER BY Start_Date
)ordered_dates CTE 는 다음과 같이 정의하였다.
여기서 사용된 두가지 함수에 대해서 간략하게 알아보자
LEAD() 그리고 LAG()
- LEAD() : 현재 행을 기준으로 이전 행의 값을 가져오는 함수
- LAG() : 현재 행을 기준으로 다음 행의 값을 가져오는 함수
따라서 여기서 사용된 명령어를 해석해보면 다음과 같이 해석할 수 있다.
- LEAD(Start_Date)는 현재 행의 Start_Date 다음 행의 Start_Date를 가져온다.
- LAG(End_Date)는 현재 행의 End_Date 이전 행의 End_Date를 가져온다.
해당 명령어에서도 보이듯이 LEAD,LAG 함수는 OVER 명령어와 같이 사용되는데 대략적인 명령어 구조는 다음과 같이 사용할 수 있다.
LEAD(<expression>[,offset[, default_value]]) OVER (
PARTITION BY (expr)
ORDER BY (expr)
)[] 부분은 생략이 가능하고, LAG 도 이와 같은 구조로 사용가능하다.
OVER 를 기준으로 어떤 컬럼을 기준으로 파티션을 나누고 순서는 어떤 컬럼을 기준으로 잡을지를 지정해주면 된다.
따라서 위에서 사용된 LEAD(),LAG() 의 경우 Start_date 를 기준으로 한줄밑, 한줄위 의 값들을 가져와 하나의 새로운 CTE 테이블을 만들어 시작날짜를 기준으로 연속된 레코드의 날짜를 추가한 임시 테이블을 생성하였다.
그럼 다음 두번째 CTE 를 살펴보자.
start_dates AS (
SELECT Start_Date,
ROW_NUMBER() OVER (ORDER BY End_Date) AS RowNum,
DATEDIFF(Start_Date, previous_end_date)
FROM ordered_dates
WHERE DATEDIFF(Start_Date, previous_end_date) > 0 OR previous_end_date IS NULL
)위 WITH 부분은 , 를 사용하여 여러개의 CTE 를 동시에 생성할 수 있고 위 테이블 역시 이렇게 생성하였지만 가독성을 위해 생략하였다.
start_dates CTE 는 어떤 테이블을 생성한 것 인지 알아보자.
ROW_NUMBER()
고유한 숫자를 붙이기 위해 사용할 수 있는 명령어이다.
여기서는 end_date 를 기준으로 숫자를 붙여나갔다 예를들어 22-10-01 은 1, 22-10-02 는 2 와 같은 순서로 숫자를 붙여줬다.
DATEDIFF()
DATEDIFF(col1,col2) 와 같이 사용할 수 있으며, col1 ~ col2 의 차이를 계산해주는 함수이다.
해당 쿼리를 살펴보면 orderd_dates 테이블 즉 앞서 생성한 임시테이블에서 조회를 하고 있다.
따라서 한 시작날짜에서 종료날짜의 차이를 구하고, 그 차이가 0 보다 크거나(프로젝트를 진행하였으니) 종료날짜가 NULL 인 값(첫번째 프로젝트 시작의 경우 종료날짜가 없음)만 가져온다
이렇게 보면 어떻게 동작하는지 쉽게 이해되지 않는다. 그럼 ordered_dates CTE 가 어떻게 생겨먹었는지 한번 살펴보자,
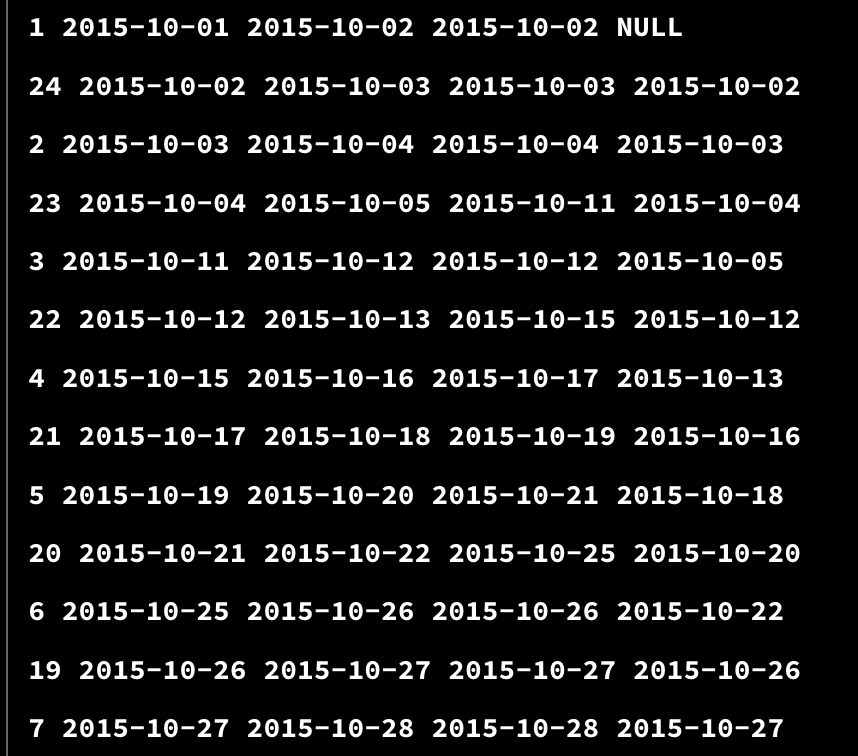
이러한 구조로 테이블이 구성되어 있다.
따라서 위에서 생성하는 start_dates 테이블을 생성하는 과정을 보면 다음과 같다 할 수 있다.
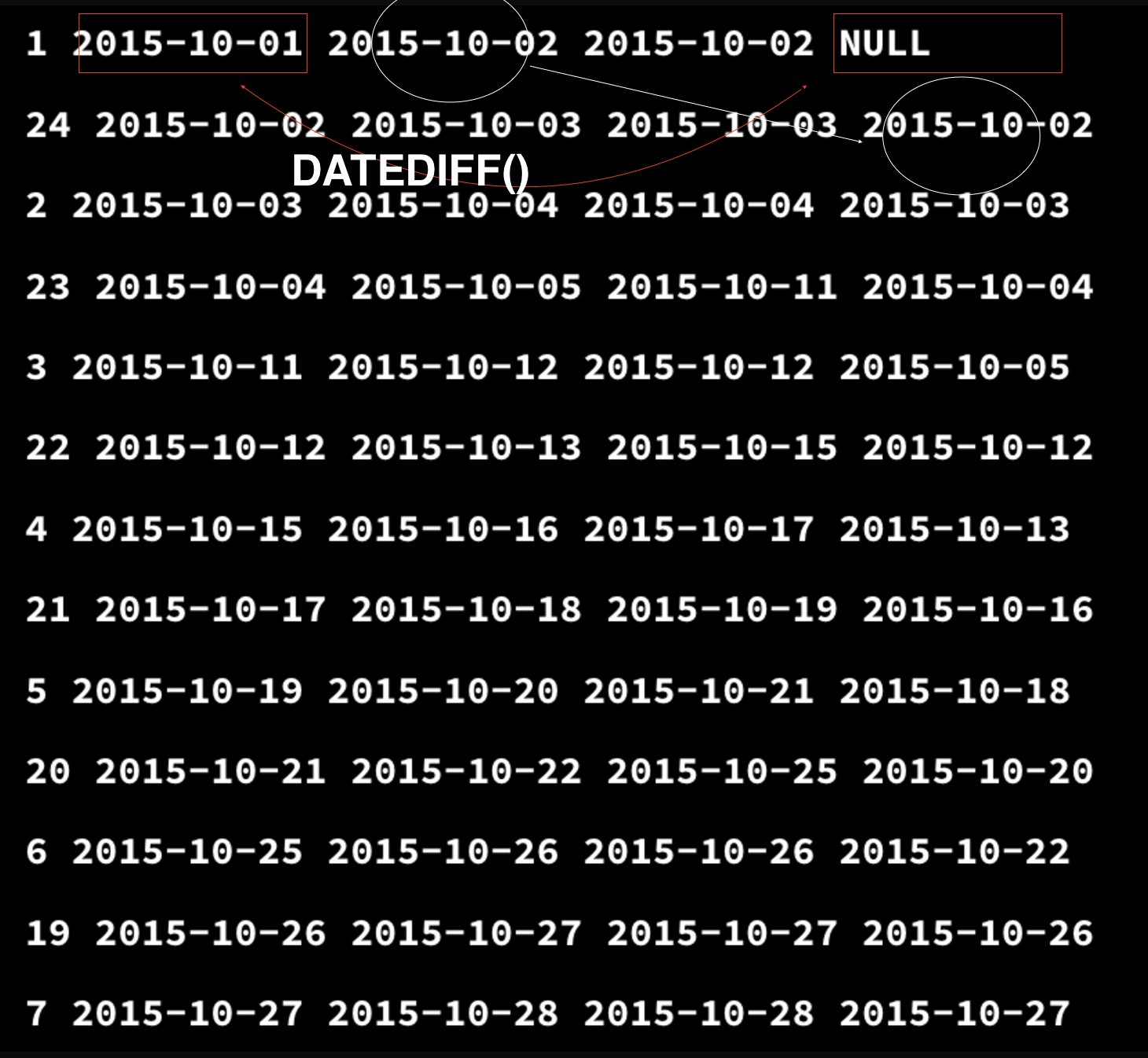
좀 지저분해보이지만 ... 각 레코드의 Previous_end_dates 값은 이전 레코드의 End_date 값으로 지정되어 있고, 각 레코드의 시작날짜와 종료날짜의 차이를 계산한 테이블을 생성한 것이라고 할 수 있다
결국 위 쿼리의 결과는 다음과 같은 결과를 볼 수 있다.
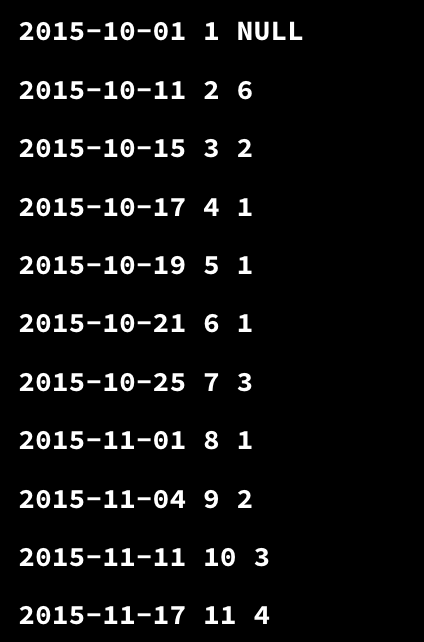
그렇다면 마지막으로 end_dates CTE 를 뜯어보자.
end_dates AS (
SELECT
ROW_NUMBER() OVER (ORDER BY Start_Date) AS RowNum,
End_Date,
DATEDIFF(next_start_date, Start_Date)
FROM ordered_dates
WHERE DATEDIFF(next_start_date, End_Date) > 0 OR next_start_date IS NULL
)다음과 같은 구조로 작성되어 있고 앞서 살펴본것과 비슷한 구조로 작성되어 있다.
해당 테이블은 결국 종료 날짜의 리스트를 만든 테이블이고, 다음 시작날짜와 현재 종료날짜와의 차이가 0 이상인 레코드와 다음 시작날짜가 NULL 인 즉, 마지막 프로젝트의 경우인 레코드들만 가져와 종료 날짜에 대한 테이블을 만들었다.
테이블은 다음과 같이 구성되어 있다.
최종적으로 이 모든 임시테이블을 이용하여 다음과 같이 최종적으로 쿼리를 작성하였다.
SELECT start_dates.Start_Date, end_dates.End_Date
FROM start_dates
INNER JOIN end_dates ON start_dates.RowNum = end_dates.RowNum
ORDER BY DATEDIFF(end_dates.End_Date, start_dates.Start_Date);시작날짜와 종료날짜를 JOIN 하여 각 프로젝트에 대한 시작,종료날짜에 대한 테이블을 만들고 문제에서 주어진 조건에 따라 순서를 지정하였다.
이번 문제를 통해 CTE 명령어를 통한 테이블 생성방법과 활용방법에 대해 알아보았고
Python Pandas 를 이용해 자주 계산했던 WINDOW 방식을 SQL로 구현해보고 사용해봄으로서 이해력과 응용력을 키울 수 있는 문제였다.
다시 한번 이와 유사한 문제가 나타난다면 이번 방법을 잘 기억해두었다가 활용하도록 연습해보자 !
