사실상 수업 시간 복습용으로 사용
기초 개념 x_86을 위한 컴파일러
전처리기, CPP
헤더파일 전처리기, 주석 --> 처리해줌.
컴파일러, gcc
C프로그래밍을 사람이 읽을 수 있는 Assembly code로 바꿔줌.
어셈블러, as
assembly code를 object code로 바꿔줌.
1대 1로 만들어줌.
object code
실행파일 하나하나 다 생기는 것
링커, ld
오브젝트, 코드와 라이브러리 모아서 링커로 실행파일 만들어줌.
나머지
executable, loader memory 실행에 관련한 부분
hex code가 메모리에 들어감.
예제
simple_sub
//전처리기 cpp
cpp simple_sub.c > simple_sub.i
// 컴파일 gcc
// 컴파일 진행하면 .s의 assembly코드가 나옴
gcc -S simple_sub.i
// 어셈블리 as .o의 object코드를 만들자
as simple_sub.s -o simple_sub.o
Assembly
as는 label 메모리에 적재가 되는건데
첫 번쨰 줄 주소
프로그램이 메모리에 적재하면 주소가 있을거임.
그 주소에 label이 붙어있다고 생각하면 될거같음.
오브젝트 코드 깨져있음 아스키코드에 해당해서
소스코드개수랑 오브젝트 1대1
오브젝트 코드나오면 링킹?을 진행
근데 ld쓰는게 아니라 옵션을 줘야함.
라이브러리를 끌어와야해서
dynamic lib을 끌어와야함.
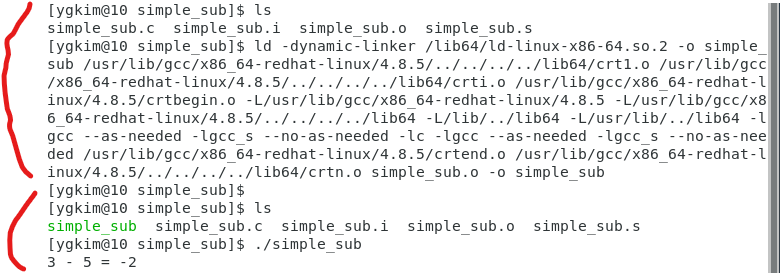
dynamic lib을 끌어오고 simple_sub을 사용한 파일
그래서 실행파일 생기고 실행을 하는 순간 메모리에 적재가 되는 것임.
메모리에 적재가 되는 동시에 프로그램 카운터가 첫줄부터 한 줄씩 읽어서 실행이 되는 것임.
RISC-V 실습 1
simple_sub
//전처리기 cpp
cpp simple_sub.c > simple_sub.i
// 컴파일 gcc
// 컴파일 진행하면 .s의 assembly코드가 나옴
gcc -S simple_sub.i
// 어셈블리 as .o의 object코드를 만들자
as simple_sub.s -o simple_sub.o
riscv도 비슷한 느낌으로
cpp -> gcc -> object -> linker를 지나가고
그중 compare.s파일에서의
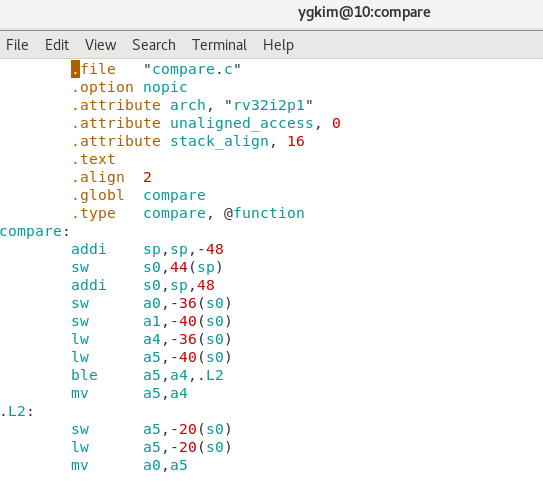
.text라는 건 프로그램을 의미
소스코드 compare.c가 assembler를 거쳐서 .text가 된다? 느낌인것 같다.
프로그램, data가 존재
.text 프로그램이 시작되는 부분
addi, sw, addi, lw, lw 등등 ble? 분기
jr은 점프 ]
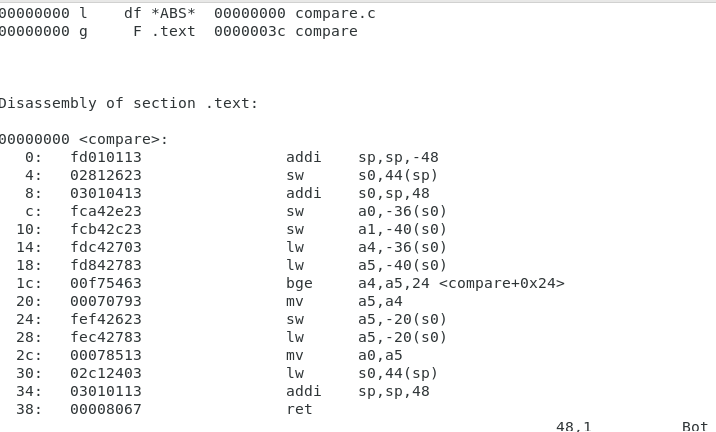
compare.o
깨져서 볼 수가 없음,
다시 사람이 읽을 수 있는 object dump로 바꾼다.
compare.dump
사람이 읽을 수 있는 32bit 명령어
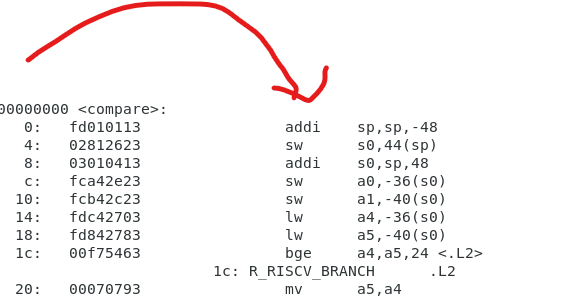
왼쪽이 32bit 명령어 --> 오른쪾으로 바꿀 수 잇음.
오른쪽의 숫자는 주소
왼쪽 명령어 1개에 32bit
0 -> 4 -> 8 -> c 4씩 올라가는 걸 볼 수 있음,
.text(프로그램) section에 있는 것들을 disassembly 해서 다시 풀어서 보여준 파일이 dump
symbol table 주소
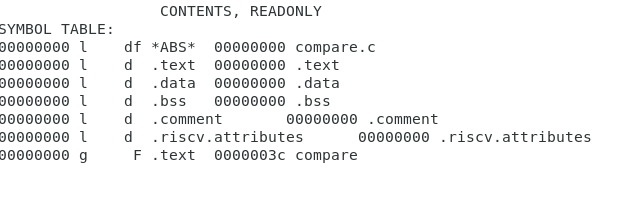
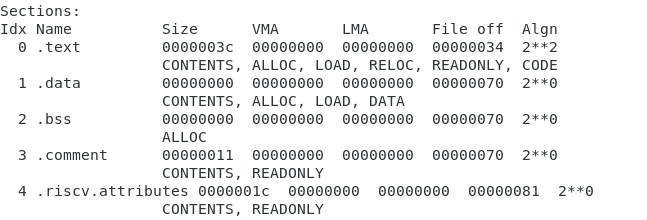
text는 프로그램
data는 data
bss도 data ----> data와 bss차이는 초기화가 되어있는가 안되어있는가
linker script
오브젝트 -> dump 까지하고 링킹을 한다.
링킹을 할 떄 외부 lib을 사용하는데
소스코드 적재를 어디에 하는지 링커의 script로 줄 수 있음.
링커를 따로 작성해서 커스터마이즈 ㄱㄴ
.lds가 확장자명
vi labcode.lds
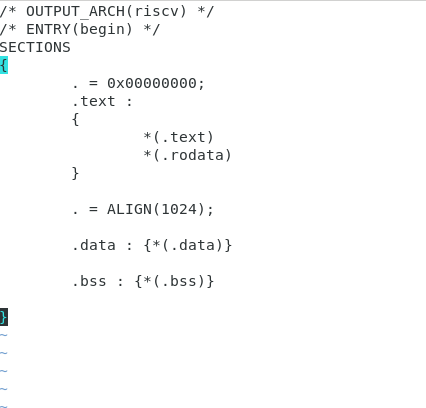
section이란
linker: 소스와 라이브러리를 통해서 실행파일을 만들때 내가 메모리를 어디에 적재하고 크기를 어떻게 잡을지
text라는 영역
0x0000000000; 0번지 부터 시작해라, 0번지에 text(프로그램)을 메모리에 쌓기 시작함.
*(.text)
각각의 오브젝트마다 프로그램이 있는데 그걸 통합한게 "*(.text)"
*(.rodata)
각각의 오브젝트에 다 상수가 있는데 그걸 text바로 아래 붙임.
붙여도 프로그램은 안 변함.
소스코드는 고정, 안바뀌는 데이터
ALIGN(1024)
아래로 대수에서 시작
ex) ALIGN(1024) 1024, 2048, 3072, 4096
1024까지 쓰고 공간 남기고 2048에서 시작, 3072에서 시작
data global한 data, 전역변수
bss 초기화되지 않은 영역의 data
1024에서 각각의 오브젝트 파일에서 데이터 영역에 해당되는 애들 끌어와서 붙이고 bss에 해당하는 애들 끌어와서 붙인다
결국 section이란
프로그램이랑 데이터랑 시작주소 그리고 어떻게 ALIGN할 것인지, 메모리 주소를 어디에 배치할지 지정해주는 것. data랑 bss가져와서 붙인다.
엔트리, 메모리, 헤더, 어서트 등 linker는 여러 파트로 나누어져있는데
일단 section만 해둠.
section: linker가 프로그램 코드와 데이터를 하나로 합쳐서 실행파일을 만들 때, 프로그램이랑 데이터를 메모리에 load할 위치와 크기를 정해준다.
여기서는 위치만
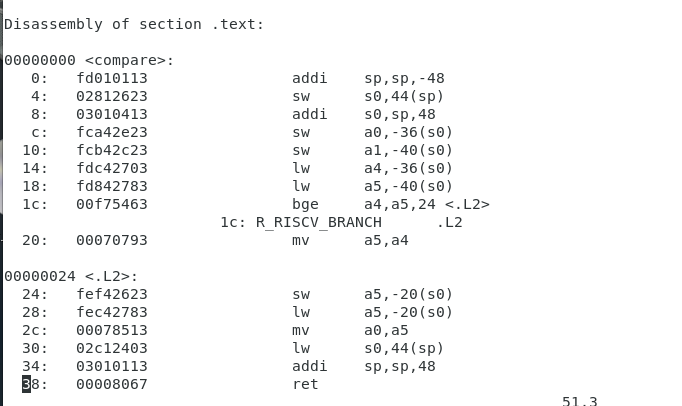
당연하게도 위의 명령어는 intel cpu는 못읽는다.
링커를 통해서 실행파일을 만들면 실행이 안됨.
disassemble해서 파일을 볼 수는 있음. dump로 만들어서
RISC-V를 만들어서 dump하기전의 실행파일을 읽을 수 있는 CPU를 제작하는 것이 수업 목표
symbol table 메모리 구조

review
프로그램이 프로그램, 데이터 크게 2개 있다고 하면
프로그램에 해당하는 부분 text에 data에 해당하는 부분 data
프로그램에서
int d[10] = {1,2,3,....};
10개 저장하면 이 데이터를 저장하는 메모리에 대한 부분이 있을 것임.
array 1~10까지의 영역이 rodata (상수들이 들어가는 영역)
linker scripts
메모리 상에서 내가 메모리의 위치를 지정해주는 것이
makefile만들기 실습
makefile이란
소스코드 만들때, 수정할때 컴파일하면 또 컴파일하고 의존성이 생김
makefile로 의존성을 정리
Design complier, ICC2 등에서 makefile은 자주 사용
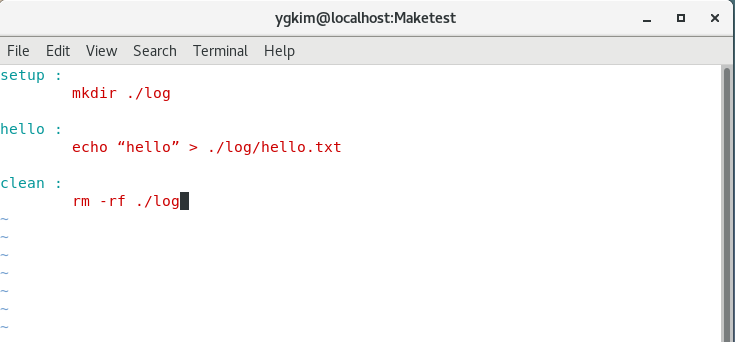
Tab으로 공간만들어 줘야함. 공간 주의
이걸로 의존성을 엮어서 사용하는 것 같음.
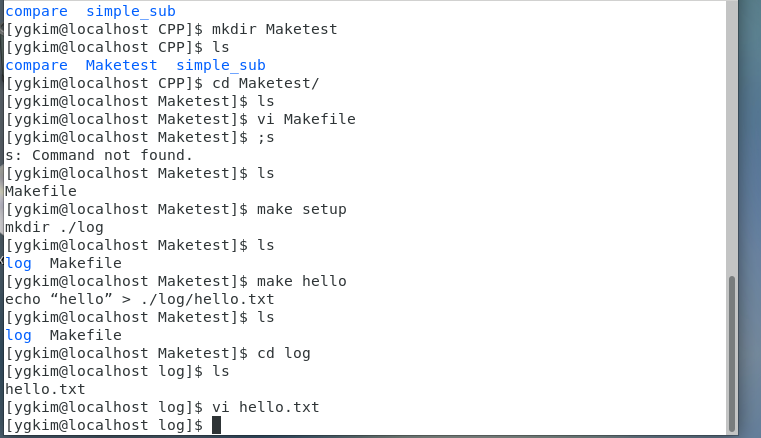
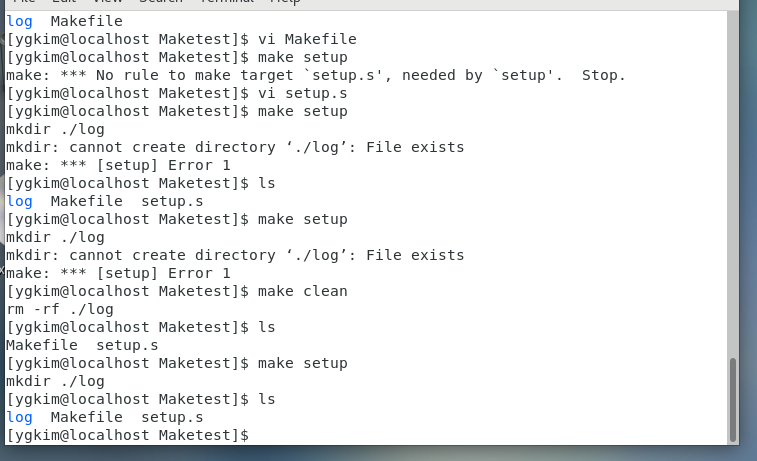
Target이란 make setup하면 mkdir ./log가 만들어짐
make hello 하면 echo 들어가는 코드 사용됨.
make clean 하면 rm -rf ./log가 실행됨.
hello 옆에 setup 의존성 엮기
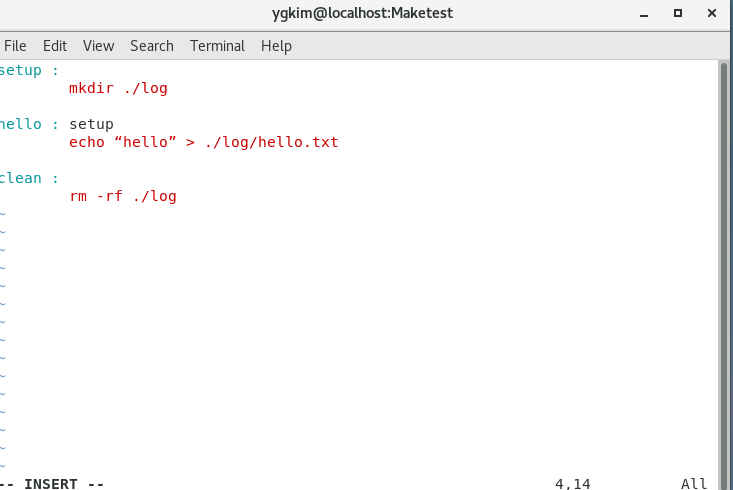
일단 make setup을 하고 make hello를 써야하는데
setup을 넣어줘서
hello라는 타겟은 setup이라는 타겟이 선행되어야 진행이 되는 코드임.
그래서 hello 앞에 setup을 넣어서 바로 hello를 쓸 수있게 만들어 주는 함수.
의존성에 타겟명, 파일명을 넣을 수 있음.
변수를 makefile안에 지정할 수 있음.
$(변수) 이렇게 사용해야댐.
실습
만들어놓은 소스코드에 makefile을 만들어서 사용해보자.

AS
LS
CC
CPP
OBDUMP :
OBCOPY :
긴 명령어를 옵션도 다 바꿀 수 있음. 지정해서
타겟에 의존성 파일명으로 했따.
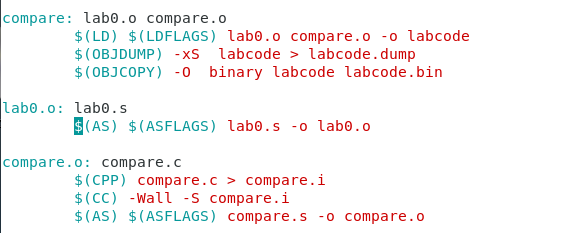
의존성에 따라사 순서대로 작동하게 되겠다라는 것을 알 수 있음.
compare.c를 바꾸면 make를 통해서 1->2->3 comepare.o, compare.dump도 확인 ㄱㄴ
lab0.s 는 어셈블러에서 시작해서 lab0.o가 바뀌는
Makefile을 만들때 가장 중요한 것은 의존성을 따지는 것
rodata는 붙일게 없음.
data영역에는 10240아래로 붙고

align 4, 4번지에 붙음.
stack 메모리 영역, 라벨 , 메모리 주소임.
stack의 시작 주소가 label 그 영역의 메모리 시작주소
la에 stack의 시작주소 label을 넣음.
space stack이라는 공간의 크기를 1024로 잡아라
다시 설명
소스코드 2개를 모아서 실행파일을 만들고
labcode.lds라는 (LD, linker scripts)를 만들고 make를 잘 지정해서 돌리면 아래와 같이 나옴.
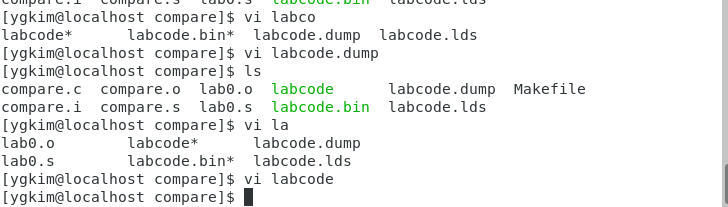
flow가 대략 c -> RISC V용 명령어만들고 -> .dump는 RISCV용을 다시 intel계열로 읽을 수 있게 해주는 파일.
labcode라는 실행파일 , labcode.bin은 binary로 바꿔준 파일
labcode를 메모리에 올려서 RISCV를 설계하면 그 프로세서가 프로그램을 한줄씩읽어서 실행하게 만드는 것이 목표임.

맨 처음에 stack의 label주소를 la에 저장하고
0 -> 4로 증가시키고 점프 j해서 14번지로 가고 또 4를 증가시켜서 실행하고
한줄을 실행할떄 패치,디코더,실행, 메모리, WB 가 다 필요함.
- memory에 있는걸 프로세서가 가지고 오는게 패치
- 해석하는게 디코더 디코더 해서 어떤 연산을 할지가 결정되면
- ALU가 실행을 하는게 exe
4.메모리 -> reg, reg -> 메모리 이런 연산 메모리 단계에서 실행
5.Write back or store back을 통해서 결과 값을 다시 레지스터에 씀.
5cycle 걸리는데 pipeling을 통해서 RISCV cpu만드는게 목표...!
