
🚖 2차 미니 프로젝트
미션: 장애인 이동권 개선을 위한 장애인 콜택시 대기시간 예측
활용 데이터셋
1.장애인 콜택시 운행정보
2.날씨 정보
도메인 이해
장애인 외출 시 자주 이용하는 교통수단 1위 → 장애인 콜택시
콜접수 - 배차 - 운행
이용 고객 만족도가 낮음
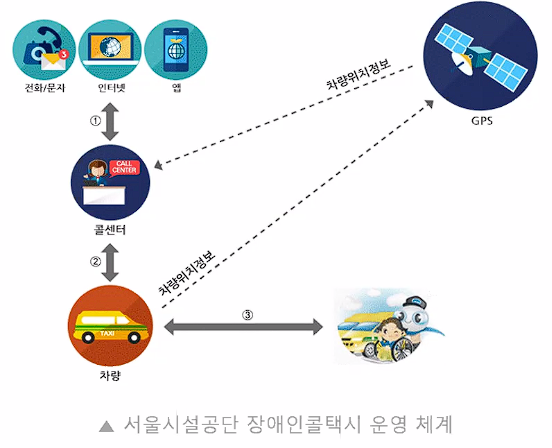
📌이용 고객들에게 정확한 대기 시간을 제공해주자!
데이터 전처리 및 분석
# 시각화 (lineplot 사용)
plt.figure(figsize=(10, 6))
plt.plot(daily_car_count.index, daily_car_count.values, marker='o', linestyle='-', color='b')
plt.title('일별 차량 운행수')
plt.xlabel('날짜')
plt.ylabel('차량 운행수')
plt.xticks(rotation=45) # x축 라벨 회전
plt.grid(True)
plt.show()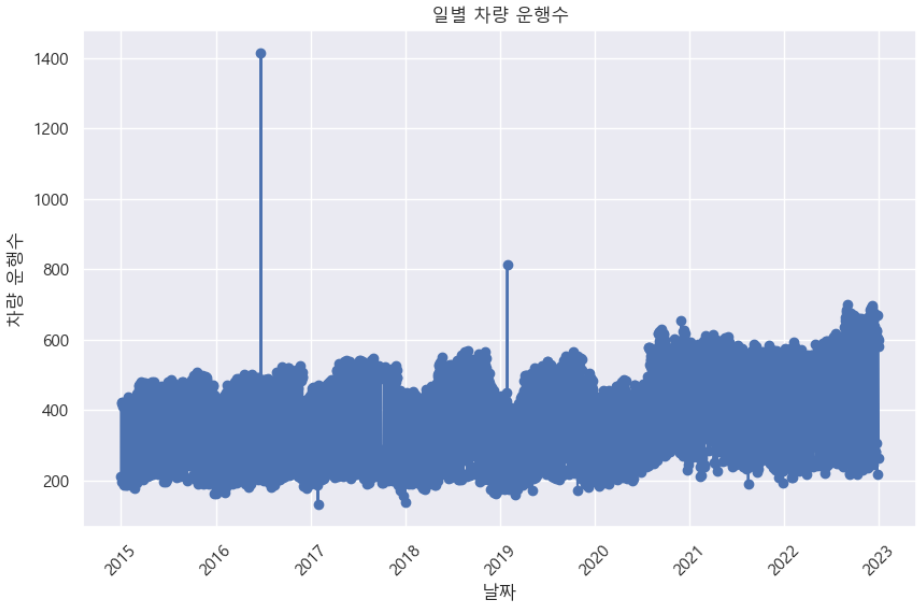
# 시각화 (lineplot 사용)
plt.figure(figsize=(10, 6))
plt.plot(daily_request_count.index, daily_request_count.values, marker='o', linestyle='-', color='b', label='접수건')
plt.plot(daily_ride_count.index, daily_ride_count.values, marker='o', linestyle='-', color='g', label='탑승건')
plt.title('일별 접수건 및 탑승건')
plt.xlabel('날짜')
plt.ylabel('건 수')
plt.xticks(rotation=45) # x축 라벨 회전
plt.legend() # 범례 표시
plt.grid(True)
plt.show()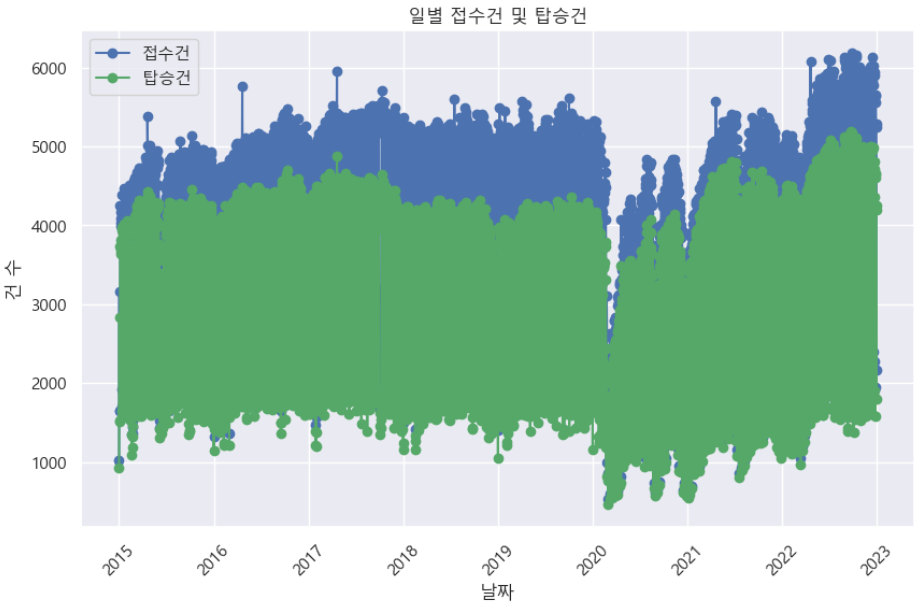
# 시각화 (boxplot 사용)
plt.figure(figsize=(10, 6))
plt.boxplot(weekday_car_counts, labels=['월', '화', '수', '목', '금', '토', '일'])
plt.title('요일별 차량 운행수')
plt.xlabel('요일')
plt.ylabel('차량 운행수')
plt.grid(True)
plt.show()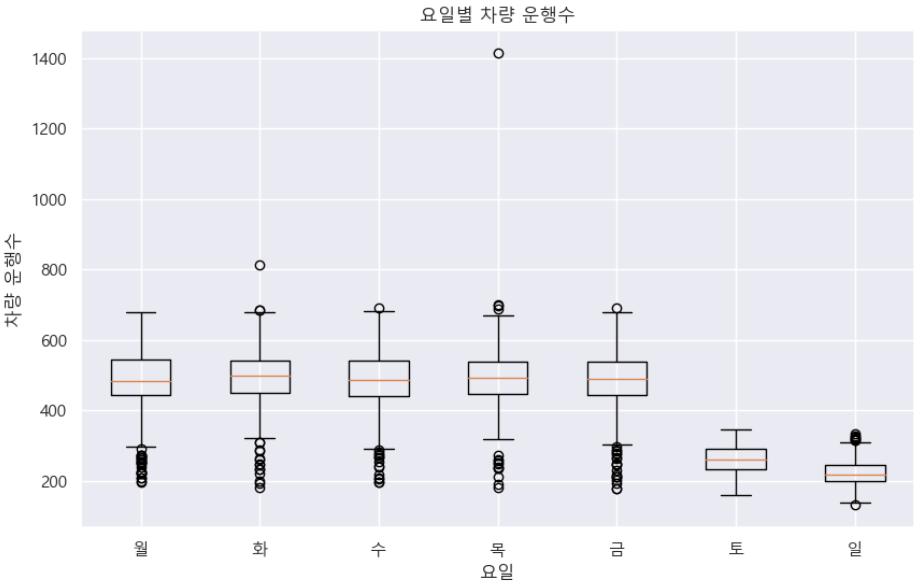
# 시각화 (boxplot 사용)
plt.figure(figsize=(10, 6))
plt.boxplot(month_waiting_time, labels=['1월', '2월', '3월', '4월', '5월', '6월', '7월','8월', '9월', '10월', '11월','12월'])
plt.title('월별 차량운행수')
plt.xlabel('월')
plt.ylabel('차량운행수')
plt.grid(True)
plt.show()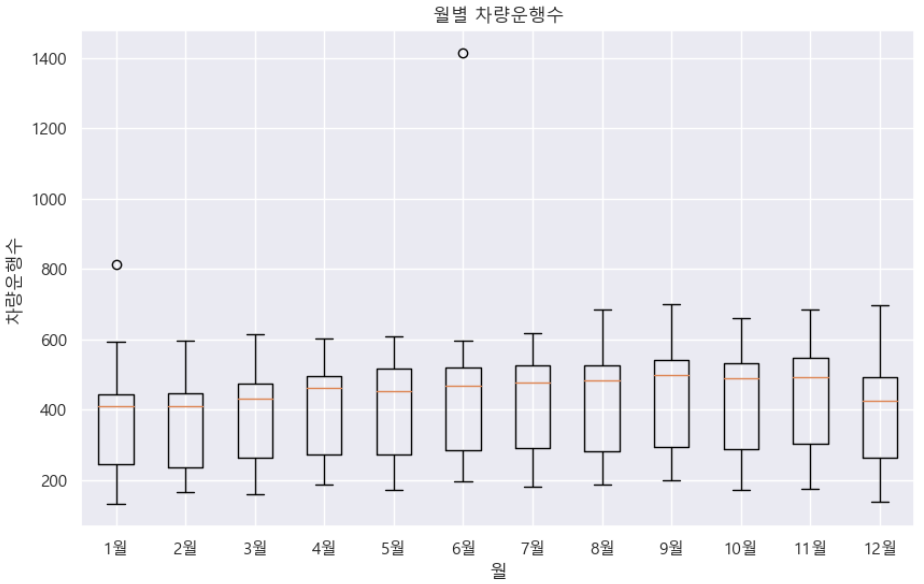
데이터 구조 만들기
# 날짜를 하루씩 미루어서 다음날 예보 데이터로 사용
weather['Date'] = pd.to_datetime(weather['Date']) - pd.DateOffset(days=1)
weather['Date'] = pd.to_datetime(weather['Date'])
# 장애인 이동 데이터와 날씨 데이터를 날짜를 기준으로 병합
combined_data = pd.merge(open_data, weather,on='Date',how='inner')
# 결과 데이터를 저장하거나 분석에 활용할 수 있습니다.
combined_data.to_csv("merge.csv", index=False) # 저장 파일 경로에 맞게 변경
# 익일의 대기시간(waiting time)을 오늘의 데이터를 활용하여 예측 해야하는 대상(target)으로 설정
# waiting_time 열을 시프트하여 익일 대기시간을 예측 대상으로 만듭니다.
merged_data['target'] = merged_data['Waiting_Time'].shift(-1)
# 마지막 행을 제거하여 NaN 값을 제거합니다. (마지막 행은 익일 대기시간이 없으므로)
merged_data = merged_data.dropna(subset=['target'])
# 예측 대상인 next_day_waiting_time을 설정합니다.
target = merged_data['target']# 숫자형 feature와 Target 간의 상관계수 계산
correlation_matrix = data1.corr()
# 상관계수 히트맵 그리기
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f", linewidths=0.5)
plt.title("숫자 feature와 Target 간의 상관계수 히트맵")
plt.show()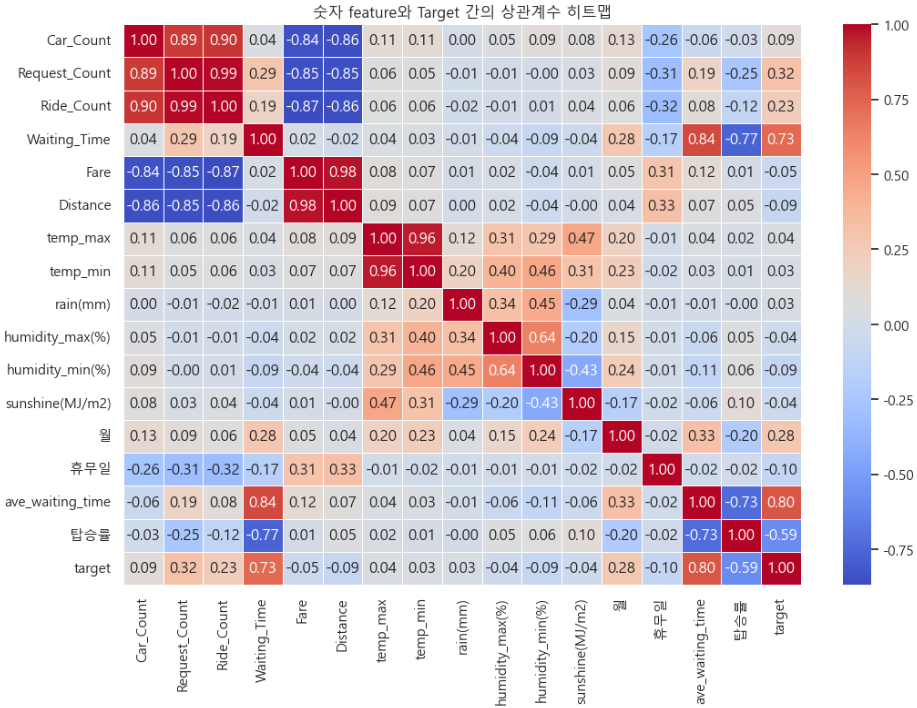
모델링
- 가변수화
# 범주형 변수 리스트
categorical_columns = ['weekday', 'month', 'year', 'season','holiday_yn','rain_yn']
# 범주형 변수를 가변수로 변환
data2 = pd.get_dummies(data2, columns=categorical_columns)
# 결과 확인
print(data2.head())- 데이터 분할
# 데이터프레임을 날짜(Date) 열을 기준으로 정렬합니다.
data2.sort_values(by='Date', inplace=True)
# 2022-10-01부터 마지막 날짜까지의 데이터를 검증 셋으로 분리합니다.
validation_start_date = '2022-10-01'
validation_set = data2[data2['Date'] >= validation_start_date]
# 검증 셋을 저장할 때 사용할 날짜 리스트를 추출합니다.
validation_dates = validation_set['Date'].unique()
# 검증 셋을 저장할 파일 경로를 지정합니다. 필요에 따라 수정하세요.
validation_set.to_csv('validation_set.csv', index=False)
# 결과 확인
print(f"검증 셋 크기: {len(validation_set)}")
print(f"검증 셋 날짜 리스트: {validation_dates}")
# x와 y를 나누기
x = train_test_data.drop(columns=['target']) # 'target' 열을 제외한 모든 열을 x로 선택
y = train_test_data['target'] # 'target' 열을 y로 선택
from sklearn.model_selection import train_test_split
# 데이터를 훈련 세트와 검증 세트로 나누기
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, shuffle=False)- 머신러닝 모델1
# 1단계: 불러오기
from sklearn.linear_model import LinearRegression
from sklearn.metrics import *
model=LinearRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
y_pred
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_test, y_pred)
print("MAE:", mae)
print('MAPE: ', mean_absolute_percentage_error(y_test, y_pred))
#MAE: 5.146222160026497
#MAPE: 0.18669192807780016
# 시각화를 위해 데이터프레임 생성
result_df = pd.DataFrame({'Actual': y_test, 'Predicted': y_pred})
# 라인 차트로 실제값과 예측값 시각화
plt.figure(figsize=(12, 6))
plt.plot(result_df.index, result_df['Actual'], label='Actual', marker='o')
plt.plot(result_df.index, result_df['Predicted'], label='Predicted', marker='x')
plt.title('Actual vs. Predicted')
plt.xlabel('Sample Index')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
plt.show()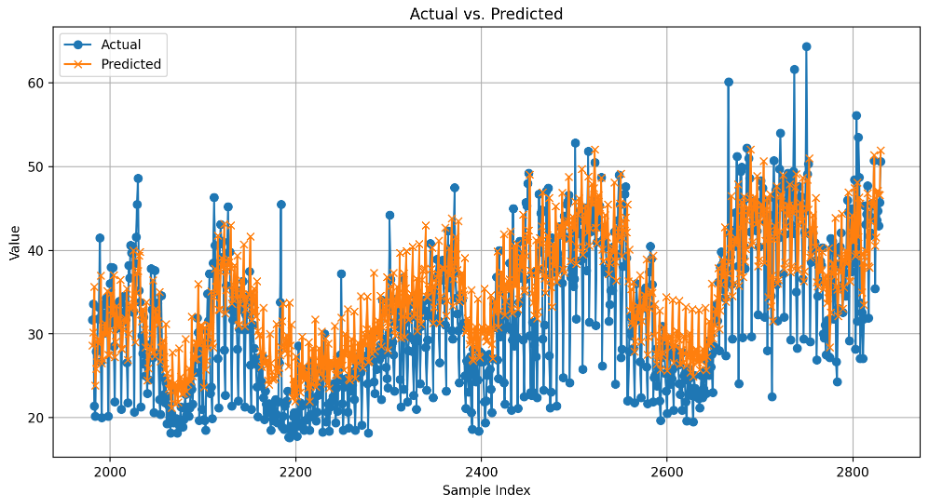
- 머신러닝 모델2
# 1단계: 불러오기
from sklearn.neighbors import KNeighborsRegressor
# 2단계: 선언하기
model = KNeighborsRegressor()
# 3단계: 학습하기
model.fit(x_train_scaler, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test_scaler)
# 5단계: 평가하기
# MAE 계산
mae = mean_absolute_error(y_test, y_pred)
print("MAE:", mae)
# MAPE 계산
print('MAPE: ', mean_absolute_percentage_error(y_test, y_pred))
#MAE: 13.559294117647058
#MAPE: 0.4844556722610472
# 시각화를 위해 데이터프레임 생성
result_df = pd.DataFrame({'Actual': y_test, 'Predicted': y_pred})
# 라인 차트로 실제값과 예측값 시각화
plt.figure(figsize=(12, 6))
plt.plot(result_df.index, result_df['Actual'], label='Actual', marker='o')
plt.plot(result_df.index, result_df['Predicted'], label='Predicted', marker='x')
plt.title('Actual vs. Predicted')
plt.xlabel('Sample Index')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
plt.show()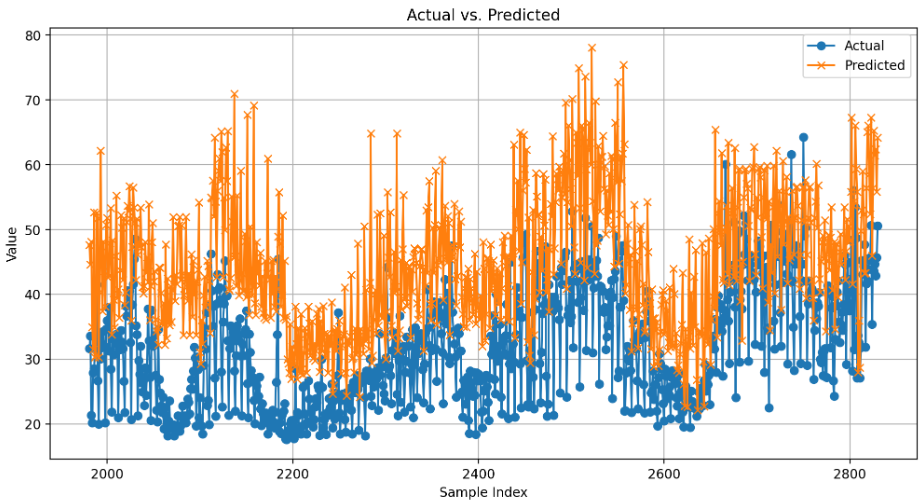
- 딥러닝 모델
import tensorflow as tf
X = tf.keras.Input(shape=x_train.shape[1])
H = tf.keras.layers.Flatten()(X)
H = tf.keras.layers.Dense(64)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
for i in range(16):
H1 = tf.keras.layers.Dense(64)(H)
H1 = tf.keras.layers.BatchNormalization()(H1)
H1 = tf.keras.layers.Activation('swish')(H1)
H = tf.keras.layers.Add()([H, H1])
Y = tf.keras.layers.Dense(1)(H)
model2 = tf.keras.Model(X, Y)
model2.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='mae')
# model.summary()
early = tf.keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
result = model2.fit(x_train, y_train, epochs=10000000, batch_size=128,
validation_split=0.2, # validation_data=(x_val, y_val)
callbacks=[early])
model2.evaluate(x_test, y_test)
#4.886806011199951# 모델 1번 시각화
final_model = model1
y_pred = final_model.predict(x_test)
plt.plot(y_test.values, label='Actual')
plt.plot(y_pred, label='Predicted')
plt.legend()
plt.title('Waiting Time')
plt.show()
mae = mean_absolute_error(y_test, y_pred)
print(f'MAE : {round(mae,3)}')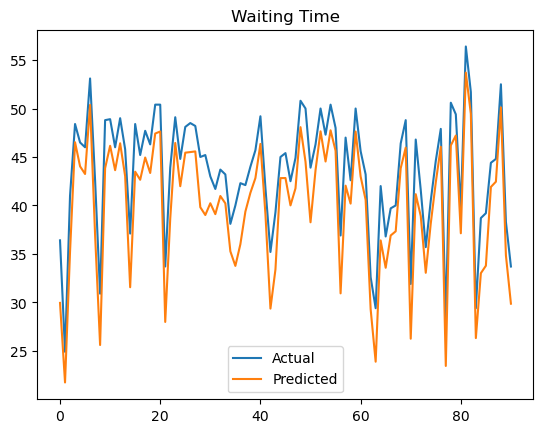
🚩2차 미니 프로젝트를 마치며
- 모델링에서 어떤 변수를 이용하냐에 따라 성능이 달라지는 것을 확인하고 어떤 변수를 제거할지 고민을 많이 해야한다. 조별 회의 때 변수를 어떻게 선정했는지 이야기를 많이 했는데 대부분 팀원들이 상관 분석을 통해 상관계수가 작은 변수를 제거하는 쪽을 택했다. 하지만 여기서도 나뉜 것이 계수로만 보고 판단해서 과감하게 다 제거하거나 아니면 계수는 작지만 개인적으로 생각했는데 필요하다고 생각하는 변수는 넣자와 머신 러닝 자체가 학습을 하면서 관계가 적은 변수의 가중치를 줄여 학습을 하는데 굳이 생각하지 않고 모든 변수를 다 이용한 팀원 분도 계셨다.
- 2020년에 콜택시 이용자 수가 크게 감소했다. 그 이유는? 코로나일 것이다. 데이터를 분석하며 그저 보이는대로 분석하기 보단 이상치 혹은 이벤트도 고려하여 분석해야한다.

느려도 내 것으로 만드는게 좋잖아?