
Ref : https://ratsgo.github.io/nlpbook/docs/introduction/pipeline/
- 실습에서 ratsnlp 오픈소스 파이썬 패키지 사용
1. 각종 설정값 정하기
모델을 만들기 위해서는 먼저 각종 설정값을 정해야 한다.
이때 설정값이란, 어떤 프린트레인 모델을 사용할지, 학습에 사용할 데이터는 무엇인지, 학습 결과는 어디에 저장할지 등을 말한다.
이 설정값들은 본격적인 학습에 앞서 미리 선언해두어야 한다.
하이퍼파라미터 역시 미리 정해둬야하는 중요한 정보이며, 하이퍼파라미터란 모델 구조와 학습 등에 직접 관계된 설정값을 가리킨다. 예를 들어 러닝 레이트(learning rate), 배치 크기(batch size)등이 있다.
2. 데이터 내려받기
프리트레인을 마친 모델을 다운스트림 데이터로 파인튜닝하는 실습을 진행한다.
파인튜닝을 위해서는 다운스트림 데이터를 미리 내려받아 두어야 한다.
3. 프리트레인을 마친 모델 준비하기
대규모 말뭉치를 활용한 프리트레인에는 많은 리소스가 필요하다.
최근 많은 기업과 개인이 프리트레인을 마친 모델을 자유롭게 사용할 수 있도록 공개하고 있다.
특히 미국 자연어처리 기업 '허깅페이스(huggingface)'에서 만든 트랜스포머라는 오픈소스 파이썬 패키지가 있다.
4. 토크나이저 준비하기
자연어 처리 모델의 입력은 대개 토큰(token)이다. 여기서 토큰이란 문장보다 작은 단위로, 한 문장은 여러 개의 토큰으로 구성된다. 토큰 분리 기준은 문장 띄어쓰기로 나누거나 의미의 최소단위인 형태소 단위로 분리할 수도 있다.
문장을 토큰 시퀀스(token sequence)로 분석하는 과정을 토큰화(tokenization), 토큰화를 수행하는 프로그램을 토크나이저(tokenizer)라고 한다.
5. 데이터 로더 준비하기
파이토치(PyTorch)는 딥러닝 모델 학습을 지원하는 파이썬 라이브러리이다.
파이토치에서는 데이터 로더(DataLoader)라는 게 포함돼 있다.
파이토치로 딥러닝 모델을 만들고자 한다면 이 데이터 로더를 반드시 정의해야한다.
데이터 로더는 학습 때 데이터를 배치 단위로 모델에 밀어 넣어주는 역할을 한다.
전체 데이터 가운데 일부 인스턴스를 뽑아 배치를 구성한다.
데이터셋은 데이터 로더의 구성 요소 가운데 하나로, 여러 인스턴스(문서+레이블)를 보유하고 있다. 그림1과 그림2에서는 편의를 위해 인스턴스가 10개인 데이터셋을 상정했지만 대개 인스턴스 개수는 이보다 훨씬 많다.
데이터 로더가 배치를 만들때 인스턴스를 뽑는 방식은 파이토치 사용자가 자유롭게 정할 수 있다.
그림1과 그림2는 크기가 3인 배치를 구성하는 예시이다.
배치1은 0번, 3번, 6번 인스턴스, 배치2는 1번, 4번, 7번 인스턴스로 구성했음을 확인할 수 있다.
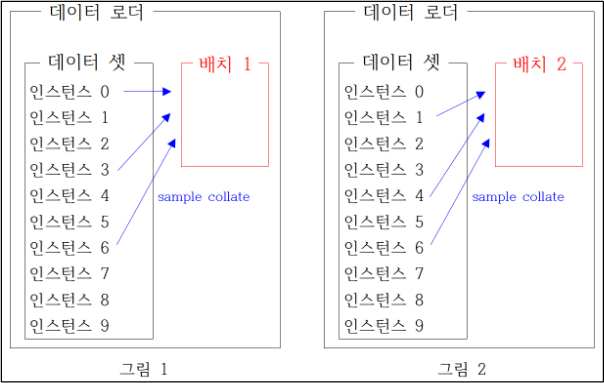
배치는 그 모양이 고정적이어야 할 때가 많다. 다시 말해 동일한 배치에 있는 문장들의 토큰 개수가 같아야 한다.
예를 들어 만들 배치가 데이터셋의 0번, 3번, 6번 인스턴스이고 각각의 토큰 개수가 5, 3, 4개라고 가정한다면 제일 긴 길이인 0번 인스턴스의 길이(5개)에 따라 3번과 6번 인스턴스의 길이를 늘려야 한다.

이 같이 배치의 모양 등을 정비해 모델의 최종 입력으로 만들어주는 과정을 컬레이트(collate)라고 한다.
컬레이트 과정에는 파이썬 리스트에서 파이토치 텐서로의 변환 등 자료형 변환도 포함된다. 컬레이트 수행 방식은 파이토치 사용자가 자유롭게 구성할 수 있다.
6. 태스크 정의하기
본 레퍼런스에서는 모델 학습을 할 때 파이토치 라이트닝(pythorch lightning)이라는 라이브러리를 사용한다. 파이토치 라이트닝은 딥러닝 모델을 학습할 때 반복적인 내용을 대신 수행해 사용자가 모델 구축에만 신경쓸 수 있도록 돕는 라이브러리이다.
파이토치 라이트닝이 제공하는 라이트닝 모듈을 상속받아 태스크를 정의한다. 이 태스크에는 앞서 준비한 모델과 최적화 방법, 학습과정 등이 정의되어 있다.

최적화(optimization)란 특정 조건에서 어떤 값이 최대나 최소가 되도록 하는 과정을 가리킨다. 모델의 출력과 정답 사이의 차이를 작게 만들기 위해서 옵티마이저 (optimizer), 러닝 레이트 스케줄러 (learning rate scheduler) 등을 정의한다.
모델 학습은 배치 단위로 이루어진다. 배치를 모델에 입력한 뒤 모델 출력을 정답과 비교해 차이를 계산한다. 이후 그 차이를 최소화하는 방향으로 모델을 업데이트한다. 이 일련의 순환 과정을 스텝이라고 하며, task의 학습 과정에는 1회 스텝에서 벌어지는 일들을 정의해둔다.
7. 모델 학습하기
트레이너는 파이토치 라이트닝에서 제공하는 객체로 실제 학습을 수행한다. 이 트레이너는 GPU등 하드웨어 설정, 학습 기록 로깅, 모델 체크포인트 저장 등 복잡한 설정을 알아서 해준다.
