
자바의 Input과 Output에 대해 정리합니다.
학습할 내용은 다음과 같습니다.
- 스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O
- InputStream과 OutputStream
- Byte와 Character 스트림
- 표준 스트림 (System.in, System.out, System.err)
- 파일 읽고 쓰기
References
- Oracle Java Document
- Oracle Java InputStream (Java SE 11 & JDK 11)
- Oracle Java OutputStream (Java SE 11 & JDK 11)
1. 스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O
Stream
I/O Stream은 input source 와 output destination으로 표현됩니다.
스트림은 디스크 파일, 장치, 기타 프로그램 및 메모리 어레이를 포함하여 다양한 종류의 Source 및 Destination이 될 수 있습니다.
스트림은 단순히 바이트 전달, primitive data, localized characters 및 objects를 포함한 다양한 종류의 데이터를 보내고 받을 수 있도록 지원합니다.
일부 스트림은 단순히 데이터를 전달하며, 다른 스트림은 데이터를 유용한 방식으로 조작하고 변환하기도 합니다.
이런 스트림은 내부적으로 어떻게 작동하든, 모든 스트림은 사용하는 프로그램에 동일한 간단한 모델을 제공합니다.
스트림은 데이터의 시퀀스입니다. 프로그램은 Input Stream을 사용하여 소스에서 한 번에 한 항목씩 데이터를 읽습니다.
프로그램은 Output Stream을 사용하여 한 번에 한 항목씩 대상에 데이터를 씁니다.
Input Stream과 Output Stream을 사용하는 곳은 데이터를 저장, 생성 또는 사용하는 모든 대상일 수 있습니다.
디스크 파일을 포함해 다른 프로그램, 주변 장치들, 네트워크 소켓 또는 배열에서 사용할 수 있습니다.
Buffered Streams
지금까지 살펴본 예제의 대부분은 unbuffered I/O를 사용합니다.
즉, 각 읽기 또는 쓰기 요청은 기본 OS에서 직접 처리됩니다.
이러한 각 I/O 요청은 디스크 액세스, 네트워크 작업 또는 상대적으로 비용이 많이 드는 다른 작업을 트리거하는 경우가 많기 때문에 프로그램의 효율성이 훨씬 떨어질 수 있습니다.
이러한 오버헤드를 줄이기 위해 Java 플랫폼은 버퍼링된 I/O 스트림을 구현합니다.
버퍼링된 입력은 버퍼로 알려진 메모리 영역에서 데이터를 읽습니다. 네이티브 입력 API는 버퍼가 비어 있을 때만 호출됩니다.
마찬가지로 버퍼링된 출력 스트림은 버퍼에 데이터를 쓰고, 네이티브 출력 API는 버퍼가 가득 찰 때만 호출됩니다.
프로그램은 unbuffered stream을 buffered stream 클래스 생성자에 전달해서 변환시킬 수 있습니다.
다음과 같이 unbuffered Stream인 FileReader와 FileWriter를 BufferedReader와 BufferedWriter로 바꿀 수 있습니다.
inputStream = new BufferedReader(new FileReader("xanadu.txt"));
outputStream = new BufferedWriter(new FileWriter("characteroutput.txt"));unbuffered streams을 wrapping 하는데 사용되는 buffered stream 클래스는 4가지가 있습니다.
-
BufferedInputStream
-
BufferedOutputStream
-
BufferedReader
-
BufferedWriter
버퍼가 채워질 때까지 기다리지 않고 critical points 때 버퍼를 출력하는 것이 좋을때가 있습니다. 이를 flushing이라고 합니다.
buffered stream 중 일부 출력 클래스는 생성자에 Optional한 Argument로 자동 플러시를 지원하기도 합니다.
자동 플러시가 활성화되면 특정 키 이벤트로 인해 버퍼가 플러시됩니다.
예를 들어, 자동 플러시 PrintWriter는 println 또는 format을 호출할 때마다 버퍼를 플러쉬합니다.
스트림을 수동으로 플러시 하기 위해서는 flush() 메소드를 호출하면 됩니다.
Channel
채널은 하드웨어 장치, 파일, 네트워크 소켓 또는 프로그램 구성요소와 같은 하나 이상의 고유한 I/O 작업을 수행할 수 있는 엔티티에 대한 열린 연결을 나타냅니다.
채널은 열려 있거나 닫혀 있을 수 있습니다.
채널은 생성 시 열려 있으며 닫히면 닫힌 상태로 유지됩니다.
채널이 닫히면 해당 채널에서 I/O 작업을 호출하려고 하면 닫힌 채널 예외가 발생합니다.
채널이 열려 있는지 여부는 isOpen 메서드를 호출하여 테스트할 수 있습니다.
일반적으로 채널은 인터페이스를 확장하고 구현하는 인터페이스 및 클래스의 사양에 설명된 대로 다중 스레드 접근을 위해 안전하도록 고안되었습니다.
자바에서 채널 클래스는 다음과 같이 있습니다.
| Channels | Description |
|---|---|
| Channel | A nexus for I/O operations |
| ReadableByteChannel | Can read into a buffer |
| ScatteringByteChannel | Can read into a sequence of buffers |
| WritableByteChannel | Can write from a buffer |
| GatheringByteChannel | Can write from a sequence of buffers |
| ByteChannel | Can read/write to/from a buffer |
| SeekableByteChannel | A ByteChannel connected to an entity that contains a variable-length sequence of bytes |
| AsynchronousChannel | Supports asynchronous I/O operations. |
| AsynchronousByteChannel | Can read and write bytes asynchronously |
| NetworkChannel | A channel to a network socket |
| MulticastChannel | Can join Internet Protocol (IP) multicast groups |
| Channels | Utility methods for channel/stream interoperation |
Channel 인터페이스에 지정된 대로 채널은 개방되거나 폐쇄될 수 있으며 비동기식으로 닫히거나 인터럽트할 수 있습니다.
Channel 인터페이스는 여러 다른 인터페이스에 의해 확장됩니다.
ReadableByteChannel 인터페이스는 채널에서 버퍼로 바이트를 읽는 읽기 방법을 지정합니다.
마찬가지로 WritableByteChannel 인터페이스도 버퍼에서 채널에 바이트를 쓰는 쓰기 방법을 지정합니다.
ByteChannel 인터페이스는 바이트를 읽고 쓸 수 있는 채널의 일반적인 경우에 대해 이 두 인터페이스를 통합합니다.
SeekableByteChannel 인터페이스는 채널의 현재 위치 및 크기를 쿼리하고 수정하는 방법을 사용하여 ByteChannel 인터페이스를 확장합니다.
ScatteringByteChannel 인터페이스와 GatheringByteChannel 인터페이스는 각각 ReadableByte Channel 및 WritableByteChannel 인터페이스를 확장하여 단일 버퍼가 아닌 일련의 버퍼를 사용하는 읽기 및 쓰기 방법을 추가합니다.
NetworkChannel 인터페이스는 채널의 소켓을 바인딩하는 방법, 소켓이 바인딩되는 주소, 소켓 옵션을 가져오고 설정하는 방법을 지정합니다.
MulticastChannel 인터페이스는 인터넷 프로토콜(IP) 멀티캐스트 그룹에 가입하는 방법을 지정합니다.
Channels utility 클래스는 java.io 패키지의 Stream 클래스와 Channel 클래스의 상호 작용을 지원하는 정적 메소드를 정의합니다.
적절한 채널은 InputStream 또는 OutputStream에서 구성될 수 있으며, 반대로 InputStream 또는 OutputStream은 채널에서 구성할 수 있습니다.
주어진 문자 집합을 사용하여 읽을 수 있는 바이트 채널에서 바이트를 디코딩하는 Reader를 구성할 수 있으며, 반대로 주어진 문자 집합을 사용하여 문자를 바이트로 인코딩하고 지정된 쓰기 가능한 바이트 채널에 쓰는 Writer를 구성할 수 있습니다.
2. InputStream과 OutputStream
InputStream (Java Platform SE 11 & JDK 11)
Java InputStream Class는 모든 InputStream Class의 최상위 추상 클래스입니다.
InputStream의 하위 클래스들은 항상 다음 입력 바이트를 반환하는 메소드를 제공해야 합니다.
InputStream에서 사용되는 메소드들을 살펴보겠습니다.
1. public static InputStream nullInputStream()
읽을 바이트가 없는 새 InputStream을 반환합니다. 반환된 스트림이 처음에는 열려 있습니다.
그러므로 close() 메소드를 통해 닫을 수 있습니다. 연속적으로 close() 메소드를 호출해도 아무 효과는 없습니다.
스트림이 열려있는 동안에는 available(), read(), read(byte[]), read(byte[], int, int), readAllBytes(), readNBytes(byte[], int, int), readNBytes(int), skip(long), and transferTo() 같은 메소드들을 정상적으로 사용할 수 있습니다.
스트림이 닫힌 후에 이런 메소드들을 사용하면 IOException을 발생시킬 수 있습니다.
markSupported() 메소드는 false를 반환할 것이며 mark() 메소드는 아무런 작업을 하지 않을것입니다.
그리고 reset() 메소드를 사용하면 IOException이 발생할 것입니다.
2. public boolean markSupported()
이 InputStream이 mark()와 reset() 메소드를 지원하는지 테스트합니다.
만약 지원한다면 true를 리턴하고 그렇지 않다면 false를 리턴합니다.
3. public void mark (int readlimit)
이 입력 스트림의 현재 위치를 표시합니다.
이 메소드 호출 후 reset() 메소드를 호출하면 이 스트림의 마지막 위치로 재이동해서 동일한 바이트를 다시 읽을 수 있습니다.
readlimit Argument는 이 입력 스트림에서 mark 위치가 잘못되기 전에 읽을 수 있는 최대 바이트 수입니다.
4. public void reset() throws IOException
InputStream에서 마지막으로 mark된 위치로 스트림을 이동시킵니다.
reset() 메소드의 일반적인 동작은 다음과 같습니다.
// test.txt
ABCDEFG
public class InputStreamDemo {
public static void main(String[] args) throws Exception {
InputStream is = null;
try {
Path path = FileSystems.getDefault().getPath("").toAbsolutePath();
is = new FileInputStream(path.toString() + "/" + "test.txt");
BufferedInputStream bufferedInputStream = new BufferedInputStream(is);
System.out.println("Char : "+(char)bufferedInputStream.read());
System.out.println("Char : "+(char)bufferedInputStream.read());
System.out.println("Char : "+(char)bufferedInputStream.read());
System.out.println("Char : "+(char)bufferedInputStream.read());
System.out.println("Char : "+(char)bufferedInputStream.read());
bufferedInputStream.mark(0);
System.out.println("Char : "+(char)bufferedInputStream.read());
System.out.println("Char : "+(char)bufferedInputStream.read());
bufferedInputStream.reset();
System.out.println("Char : "+(char)bufferedInputStream.read());
System.out.println("Char : "+(char)bufferedInputStream.read());
} catch(Exception e) {
e.printStackTrace();
} finally {
if(is!=null)
is.close();
}
}
}
// expected output
Char : A
Char : B
Char : C
Char : D
Char : E
Char : F
Char : G
Char : F
Char : G5. public int available() throws IOException
skip 없이 읽을 수 있는 바이트의 수를 리턴합니다. Stream의 끝에 도달한 경우에는 0을 리턴합니다.
6. public void close() throws IOException
이 입력 스트림을 닫고 스트림과 연결된 모든 시스템 리소스를 해제합니다.
7. public long transferTo(OutputStream out) throws IOException
이 입력 스트림의 모든 바이트를 읽고 해당 바이트를 읽은 순서대로 지정된 출력 스트림에 씁니다.
반환 시 이 입력 스트림은 스트림 끝에 있게 됩니다.
그리고 이 메소드를 호출한다고 스트림을 close 하지 않습니다.
이 메소드는 입력 스트림에서 읽고 출력 스트림에서 쓰는 동안 무기한으로 블로킹 될 수 있습니다.
입력 스트림에서 읽거나 출력 스트림에 쓸 때 일부 바이트를 읽거나 쓴 후에 I/O 오류가 발생할 수 있습니다.
결과적으로 입력 스트림은 스트림의 끝에 있지 않을 수 있으며, 하나 또는 둘 다 스트림의 상태가 일관되지 않을 수 있습니다.
I/O 오류가 발생할 경우 두 스트림을 즉시 닫는 것이 좋습니다.
8. public abstract int read() throws IOException
입력 스트림에서 다음 데이터 바이트를 읽습니다. 값 바이트는 0 ~ 255 범위의 int로 반환됩니다.
만약 스트림 끝에 도달해 읽을 바이트가 없다면 -1을 리턴합니다.
하위 클래스는 이 메소드의 구현을 제공해야 합니다.
9. public int read (byte[] b) throws IOException
입력 스트림에서 일부 바이트를 읽고 Argument인 Array b에 저장합니다. 실제로 읽은 바이트 수는 정수로 반환됩니다
b의 길이가 0이면 바이트가 읽히지 않고 0이 반환됩니다. 그렇지 않으면 하나 이상의 바이트를 읽습니다.
스트림이 파일 끝에 있다면 사용 가능한 바이트가 없으므로 값 -1이 반환되고, 그렇지 않으면 적어도 하나의 바이트가 b에 읽혀 저장됩니다.
10. public int read (byte[] b, int off, int len) throws IOException
입력 스트림에서 바이트 배열로 최대 10바이트의 데이터를 읽습니다.
바이트 수만큼 읽으려고 시도했지만 더 적은 수의 바이트를 읽을 수 있습니다. 실제로 읽은 바이트 수는 정수로 반환됩니다.
이 메소드는 나머지 바이트가 모두 읽혀지고 스트림의 끝이 탐지되거나 예외를 발생시킬때까지 blocking 됩니다.
len이 0이면 바이트가 읽히지 않고 0이 반환됩니다. 그렇지 않으면 하나 이상의 바이트를 읽을려고 합니다.
스트림이 파일의 끝에 있어 읽을 바이트가 없으면 값 -1이 반환되고, 그렇지 않으면 적어도 하나의 바이트가 b에 읽혀 저장됩니다.
11. public byte[] readAllBytes() throws IOException
입력 스트림의 나머지 바이트를 모두 읽습니다.
이 메소드는 나머지 바이트가 모두 읽혀지고 스트림의 끝이 탐지되거나 예외를 발생시킬때까지 blocking 됩니다.
이 메소드는 입력 스트림을 닫지 않습니다.
이 스트림이 스트림 끝에 도달하면 이 메소드를 추가로 호출하면 빈 바이트 배열이 반환됩니다.
12. public byte[] readNBytes (int len) throws IOException
입력 스트림에서 지정된 바이트 수까지 읽습니다.
반환된 어레이의 길이는 스트림에서 읽은 바이트 수와 같습니다. len이 0이면 바이트가 읽히지 않고 빈 바이트 배열이 반환됩니다. 그렇지 않으면 스트림에서 최대 10바이트가 읽힙니다.
스트림의 끝에 도달하는 경우라면 그보다 더 작은 바이트가 반환될 수 있습니다.
13. public int readNBytes (byte[] b, int off, int len) throws IOException
입력 스트림에서 지정된 바이트 배열로 요청된 바이트 수를 읽습니다.
Argument로 주어진 len 길이 만큼의 바이트를 읽을 때까지 blocking 됩니다.
리턴하는 값은 읽은 바이트의 수 만큼 리턴합니다.
14. public long skip (long n) throws IOException
이 매소드는 입력 스트림에서 데이터 바이트를 건너뛰고 삭제합니다. 반환 값은 건너 뛴 바이트의 개수입니다.
만약 Argument인 n이 음수인 경우라면 InputStream 클래스의 건너뛰기 메소드는 항상 0을 반환하며 건너뛴 바이트는 없습니다.
이 클래스의 하위 클래스는 음수 값을 다르게 처리할 수 있습니다.
이 클래스의 skip() 메소드 구현은 바이트 배열을 만든 후 n바이트가 읽히거나 스트림 끝에 도달할 때까지 반복해서 읽습니다.
하위 클래스는 이 보다 효율적인 구현을 제공하도록 권장됩니다.
OutputStream (Java Platform SE 11 & JDK 11)
1. public static OutputStream nullOutputStream()
모든 바이트를 버리고 새 OutputStream을 반환합니다.
반환된 스트림이 처음에 열려 있습니다. close() 메소드를 호출하면 스트림이 닫힙니다.
스트림이 열려 있는 동안에는 write(int), write(byte[]), and write(byte[], int, int) 메소드는 아무 작업도 수행하지 않습니다.
스트림이 닫힌 후 이러한 방법은 모두 IO 예외를 발생시킵니다.
flush() 메소드는 아무 것도 하지 않습니다.
2. public void flush() throws IOException
출력 스트림을 플러시합니다. 플러시는 버퍼에 저장된 바이트를 해당 바이트가 즉시 목적지에 보냅니다.
이 스트림의 대상이 기본 운영 체제에서 제공하는 추상화(예: 파일)인 경우, 스트림을 플러시하면 이전에 스트림에 쓴 바이트만 운영 체제에 전달되고 실제로 Disk drive와 같은 물리적 디바이스에 기록되는 것을 보장하지 않습니다.
3. public abstract void write (int b) throws IOException
지정한 바이트를 이 출력 스트림에 씁니다. 일반적으로 1바이트가 출력 스트림에 씁니다.
OutputStream의 하위 클래스는 이 메서드에 대한 구현을 제공해야 합니다.
4. public void write (byte[] b) throws IOException
지정한 바이트 배열의 b.length 바이트를 이 출력 스트림에 씁니다.
5. public void write(byte[] b, int off, int len) throws IOException
오프셋 off에서 시작하여 이 출력 스트림에 지정한 바이트 배열의 len 바이트를 씁니다.
byte[] b의 바이트 중 일부가 출력 스트림에 순서대로 기록됩니다. b[off]는 처음 쓴 바이트이고 b[off+len-1]은 이 작업에 의해 쓰여진 마지막 바이트입니다.
b가 null인 경우 NullPointer예외가 발생합니다.
off가 음수이거나 len이 음수이거나 off+len이 배열 b의 길이보다 크면 IndexOutOfBoundsException이 발생합니다.
6. public void close() throws IOException
이 출력 스트림을 닫고 스트림과 연결된 모든 시스템 리소스를 해제합니다.
3. Byte와 Character 스트림
Byte Streams
프로그램은 바이트 스트림을 사용하여 8비트 바이트의 입력과 출력을 수행합니다. 모든 Byte Stream 클래스는 InputStream 및 OutputStream의 하위 클래스입니다.
자바에는 많은 바이트 스트림 클래스가 있습니다.
바이트 스트림의 동작하는 방식은 거의 같으므로 그 중 예시인 FileInputStream FileOutputStream을 살펴보겠습니다.
바이트 스트림을 사용하여 xanadu.txt를 복사하는 CopyBytes라는 예제를 보겠습니다.
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("xanadu.txt");
out = new FileOutputStream("outagain.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
}CopyBytes는 다음 그림과 같이 입력 스트림을 읽고 한 번에 한 바이트씩 출력 스트림을 쓰는 작업을 합니다.
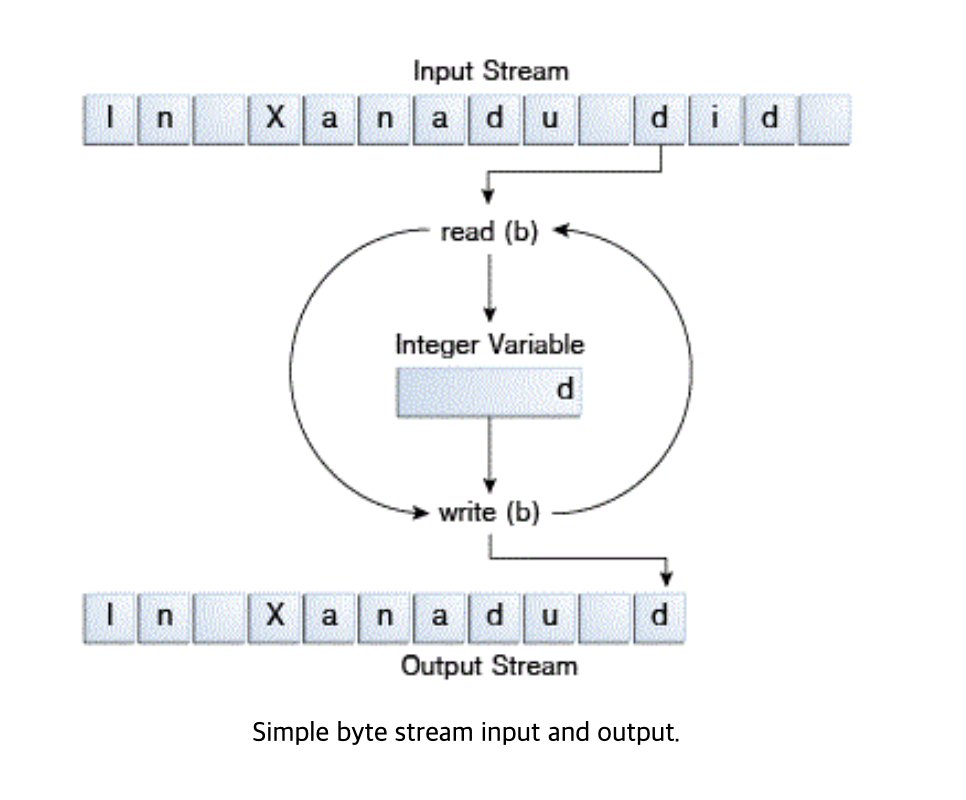
CopyBytes는 일반 프로그램처럼 보이지만 실제로는 피해야 할 성능이 낮은 수준의 I/O를 나타냅니다.
Xanadu.txt에는 문자 데이터가 포함되어 있으므로 문자 스트림을 사용하는 것이 가장 좋습니다. 그리고 더 복잡한 데이터 유형에 대한 스트림도 있습니다.
바이트 스트림은 가장 원시적인 I/O에만 사용해야 합니다. 바이트 스트림을 배우는 이유는 다른 유형의 스트림이 다 바이트 스트림을 기반으로 두고 있기 때문입니다.
Character Streams
자바에서는 Unicode 규칙을 사용해서 문자를 저장합니다.
Character stream I/O은 자동적으로 내부 형식을 로컬 문자 집합과 변환합니다. Western locales에서 로컬 문자 집합은 일반적으로 ASCII의 8비트 상위 집합입니다.
대부분의 애플리케이션에서 문자 스트림을 사용하는 I/O는 바이트 스트림을 사용하는 I/O보다 복잡하지 않습니다.
스트림 클래스로 수행된 입력 및 출력은 로컬 문자 집합으로 자동 변환됩니다.
바이트 스트림 대신 문자 스트림을 사용하는 프로그램은 자동으로 로컬 문자 집합에 적응하고 국제화를 위해 사용됩니다. 이 모든 프로그램은 프로그래머의 추가 노력 없이 가능합니다.
모든 문자 스트림 클래스는 Reader 및 Writer의 하위 클래스입니다.
바이트 스트림과 마찬가지로 File I/O: FileReader 및 FileWriter인 문자 스트림 클래스가 있습니다.
아래는 문자 스트림을 사용해 xanadu.txt를 복사하는 CopyCharacters 예제입니다.
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class CopyCharacters {
public static void main(String[] args) throws IOException {
FileReader inputStream = null;
FileWriter outputStream = null;
try {
inputStream = new FileReader("xanadu.txt");
outputStream = new FileWriter("characteroutput.txt");
int c;
while ((c = inputStream.read()) != -1) {
outputStream.write(c);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}CopyCharacters 예제는 바이트 스트림 예제인 CopyBytes와 매우 유사합니다.
차이점은 FileInputStream 및 FileOutputStream 대신 FileReader 및 FileWriter를 사용하여 입출력 작업을 수행한다는 것입니다.
CopyBytes 및 CopyCharacters 모두 int 변수를 사용하여 읽고 쓸 수 있습니다.
하지만 CopyCharacters에서 int 변수는 마지막 16비트(2 바이트)로 문자 값을 유지하며, CopyBytes에서 int 변수는 마지막 8비트(1 바이트)로 바이트 값을 유지합니다.
문자 스트림은 종종 바이트 스트림의 "Wrapper"입니다.
문자 스트림은 바이트 스트림을 사용하여 물리적 I/O를 수행하면서도 문자 스트림은 Character와 Byte 간의 변환을 처리합니다.
즉 FileReader는 FileInputStream을 사용하는 반면 FileWriter는 FileOutputStream을 사용합니다.
Byte와 Character를 이어주는 스트림인 InputStreamReader와 OutputStreamWriter가 있습니다. 이것들을 이용하면 문자 스트림을 만들 수 있습니다.
Line-Oriented I/O
Character I/O는 일반적으로 단일 문자보다 큰 단위로 발생합니다. 즉 하나의 일반적인 단위는 줄입니다.
줄 끝에는 줄 터미네이터가 있는 문자열이 있습니다. 이 문자열은 다음과 같습니다.
-
carriage-return/line-feed sequence ("\r\n")
-
a single carriage-return ("\r")
-
a single line-feed ("\n")
가능한 모든 줄 터미네이터를 지원하면 프로그램이 여러 운영 체제에서 만들어진 텍스트 파일을 읽을 수 있습니다.
CopyCharacters 예제를 line-oriented I/O로 바꿔보겠습니다.
이렇게 하려면 BufferedReader와 PrintWriter라는 두 가지 클래스를 사용해야 합니다.
Buffered I/O 및 Formating에서 이러한 클래스를 자세히 살펴보겠습니다.
지금은 단지 line-oriented I/O에 대해 알아보겠습니다. 예제는 다음과 같습니다.
import java.io.FileReader;
import java.io.FileWriter;
import java.io.BufferedReader;
import java.io.PrintWriter;
import java.io.IOException;
public class CopyLines {
public static void main(String[] args) throws IOException {
BufferedReader inputStream = null;
PrintWriter outputStream = null;
try {
inputStream = new BufferedReader(new FileReader("xanadu.txt"));
outputStream = new PrintWriter(new FileWriter("characteroutput.txt"));
String l;
while ((l = inputStream.readLine()) != null) {
outputStream.println(l);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}readLine 메소드를 호출하면 줄이 있는 텍스트 줄이 반환됩니다.
CopyLines 예제는 현재 운영 체제의 line terminator를 추가하는 println을 사용하여 각 라인을 출력합니다.
입력 파일에 사용된 것과 같은 line terminator가 아닐 수 있습니다.
4. 표준 스트림 (System.in, System.out, System.err)
Scanning and Formatting
프로그래밍 I/O는 종종 인간이 작업하기 좋아하는 깔끔한 형식의 데이터를 변환하거나 변환해야 합니다.
이러한 작업을 지원하기 위해 Java 플랫폼은 두 가지 API를 제공합니다.
Scanner API는 입력을 데이터 비트와 관련된 개별 토큰으로 나눕니다.
Format API는 데이터를 사람이 읽을 수 있는 훌륭한 포맷으로 조립하는 역할을 합니다.
Scanning
Scanner 객체는 형식화된 입력을 토큰으로 분류하고 데이터 유형에 따라 개별 토큰을 변환하는 데 유용합니다.
기본적으로 스캐너는 공백을 사용하여 토큰을 분리합니다.
공백 문자에는 White space, tabs 및 line terminators가 포함됩니다.
scanning의 작동 방식을 보기위해 다음 예제를 보겠습니다.
import java.io.*;
import java.util.Scanner;
public class ScanXan {
public static void main(String[] args) throws IOException {
Scanner s = null;
try {
s = new Scanner(new BufferedReader(new FileReader("xanadu.txt")));
while (s.hasNext()) {
System.out.println(s.next());
}
} finally {
if (s != null) {
s.close();
}
}
}
}
// expected output
In
Xanadu
did
Kubla
Khan
A
stately
pleasure-domeScanXan은 스캐너 객체가 완료되면 close() 메소드를 호출합니다. 스캐너가 스트림이 아니더라도 기본 스트림을 완료했음을 나타내려면 스캐너를 닫아야 합니다.
다른 토큰 구분 기호를 사용하려면 정규식을 지정하는 useDelimiter()를 호출하면 됩니다.
ScanXan 예제에서는 모든 입력 토큰을 단순 문자열 값으로 처리합니다.
하지만 스캐너는 또한 자바 언어의 모든 원시 유형에 대한 토큰과 빅 정수(BigInteger)를 지원합니다.
숫자 값은 수천 개의 구분자를 사용할 수 있습니다. 따라서 미국 로케일에 기준으로 스캐너는 "32,767" 문자열을 정수 값으로 올바르게 읽습니다.
수천 개의 구분 기호와 십진 기호는 로케일에 따라 다르므로 로케일에 대해 언급해야 합니다.
따라서 스캐너가 미국 로케일을 사용하도록 지정하지 않으면 다음 예제는 다른 로케일에서 올바르게 작동하지 않습니다.
import java.io.FileReader;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.Scanner;
import java.util.Locale;
public class ScanSum {
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
try {
s = new Scanner(new BufferedReader(new FileReader("usnumbers.txt")));
s.useLocale(Locale.US);
while (s.hasNext()) {
if (s.hasNextDouble()) {
sum += s.nextDouble();
} else {
s.next();
}
}
} finally {
s.close();
}
System.out.println(sum);
}
}
// usnumbers.txt
8.5
32,767
3.14159
1,000,000.1
// expected output
1032778.74159Formatting
Format을 구현하는 스트림은 character stream 클래스인 PrintWriter 또는 byte stream 클래스인 PrintStream의 인스턴스입니다.
PrintStream 오브젝트는 System.out과 System.err가 있습니다.
formatted된 출력 스트림을 만들어야 하는 경우네는 PrintStream이 아니라 PrintWriter를 인스턴스화 해야합니다.
모든 바이트 및 문자 스트림 객체와 마찬가지로 PrintStream 및 PrintWriter 인스턴스는 단순 바이트 및 문자 출력을 위한 표준 쓰기 방법 세트를 구현합니다.
Standard Streams
표준 스트림은 많은 운영 체제의 기능입니다.
기본적으로 키보드에서 입력을 읽고 디스플레이에 출력을 씁니다.
파일 및 프로그램 간 I/O도 지원하지만 이 기능은 프로그램이 아닌 명령줄 인터프리터에 의해 제어됩니다.
Java 플랫폼은 세 가지 표준 스트림을 지원합니다.
-
System.out (Standard Output)
-
System.err (Standard Error)
-
System.in (Standard Input)
System.out과 System.err는 둘 다 출력용입니다.
오류 출력을 별도로 사용하면 사용자가 일반 출력을 파일로 전환해도 오류 메시지를 읽을 수 있습니다.
표준 스트림이 문자 스트림일 것으로 예상할 수 있지만 여러가지 이유들로 인해 해당 스트림은 바이트 스트림입니다.
System.out이나 System.err는 바이트 스트림의 일종인 PrintStream 객체입니다.
기술적으로는 바이트 스트림이지만, PrintStream은 내부 문자 스트림 객체를 사용하여 문자 스트림의 많은 기능을 모방합니다.
하지만 System.in은 문자 스트림 기능이 없는 바이트 스트림입니다.
표준 입력을 문자 스트림으로 사용하려면 다음과 같이 InputStreamReader에서 System.in을 감싸야합니다.
InputStreamReader cin = new InputStreamReader(System.in);5. 파일 읽고 쓰기
Commonly Used Methods for Small Files
Reading All Bytes or Lines from a File
작은 크기의 파일이 있는 경우 전체 내용을 한 번에 읽으려면 모든 readAllBytes(Path) 또는 readAllLines(Path, Charset) 메소드를 통해 가능합니다.
Path file = ...;
byte[] fileArray;
fileArray = Files.readAllBytes(file);Writing All Bytes or Lines to a File
다음과 같은 write 메소드를 이용해 파일에 바이트 또는 줄을 쓸 수 있습니다.
-
write(Path, byte[], OpenOption...)
-
write(Path, Iterable< extends CharSequence>, Charset, OpenOption...)
예시는 다음과 같습니다.
Path file = ...;
byte[] buf = ...;
Files.write(file, buf);Buffered I/O Methods for Text Files
Reading a File by Using Buffered Stream I/O
newBufferedReader 메소드는 읽기 위해 파일을 열고 파일의 텍스트를 효율적으로 읽는 데 사용할 수 있는 BufferedReader를 반환합니다.
다음 예제는 파일에서 읽기 위해 새 BufferedReader 메소드를 사용하는 방법을 보여 줍니다. 이 파일은 "US-ASPIR"로 인코딩되어 있습니다.
Charset charset = Charset.forName("US-ASCII");
try (BufferedReader reader = Files.newBufferedReader(file, charset)) {
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}Writing a File by Using Buffered Stream I/O
newBufferedWriter 메소드를 사용하면 BufferedWriter를 이용해 파일에 쓸 수 있습니다.
다음 예제는 이 메소드을 사용하여 "US-ASCR"로 인코딩된 파일을 만드는 방법을 보여 줍니다.
Charset charset = Charset.forName("US-ASCII");
String s = ...;
try (BufferedWriter writer = Files.newBufferedWriter(file, charset)) {
writer.write(s, 0, s.length());
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}Methods for Unbuffered Streams and Interoperable with java.io APIs
Reading a File by Using Stream I/O
읽기 위해 파일을 열려면 newInputStream 메소드를 사용할 수 있습니다.
이 메소드는 파일에서 바이트를 읽기 위해 버퍼링되지 않은 입력 스트림을 반환합니다.
예제는 다음과 같습니다.
Path file = ...;
try (InputStream in = Files.newInputStream(file);
BufferedReader reader =
new BufferedReader(new InputStreamReader(in))) {
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException x) {
System.err.println(x);
}Creating and Writing a File by Using Stream I/O
newOutputStream 메소드를 사용해 파일을 만들거나 파일에 추가하거나 파일에 쓸 수 있습니다.
이 메서드는 바이트를 쓰기 위한 파일을 열거나 만들고 버퍼링되지 않은 출력 스트림을 반환합니다.
메소드는 Optional로 OpenOption 매개 변수를 사용합니다.
open option이 지정되지 않으면 파일이 없으면 새 파일이 생성됩니다. 파일이 있으면 잘립니다.
이 옵션은 CREATE 및 TRUCKATE_EXISTING 옵션을 사용하여 메서드를 호출하는 것과 같습니다.
다음 예에서는 로그 파일을 엽니다. 파일이 없으면 파일이 생성됩니다. 파일이 있는 경우 첨부용으로 열립니다.
import static java.nio.file.StandardOpenOption.*;
import java.nio.file.*;
import java.io.*;
public class LogFileTest {
public static void main(String[] args) {
// Convert the string to a
// byte array.
String s = "Hello World! ";
byte data[] = s.getBytes();
Path p = Paths.get("./logfile.txt");
try (OutputStream out = new BufferedOutputStream(
Files.newOutputStream(p, CREATE, APPEND))) {
out.write(data, 0, data.length);
} catch (IOException x) {
System.err.println(x);
}
}
}Methods for Channels and ByteBuffers
Reading and Writing Files by Using Channel I/O
스트림 I/O가 한 번에 문자를 읽는 동안 채널 I/O는 한 번에 버퍼를 읽습니다.
ByteChannel 인터페이스는 기본적인 읽기 및 쓰기 기능을 제공합니다.
SeekableByteChannel 인터페이스는 채널의 위치를 유지하고 해당 위치를 변경할 수 있는 기능을 가진 바이트 채널입니다.
채널 I/O를 읽고 쓰는 방법은 두 가지가 있습니다.
-
newByteChannel(Path, OpenOption...)
-
newByteChannel(Path, Set, FileAttribute...)
newByteChannel 메소드는 SeekableByteChannel 인스턴스를 반환합니다.
기본 파일 시스템을 사용하여 파일 채널에 이 검색 가능한 바이트 채널을 캐스팅하여 파일 영역을 메모리에 직접 매핑하거나, 다른 프로세스에서 액세스할 수 없도록 파일의 영역을 잠그거나, 절대 위치에서 해당 채널에 영향을 주지 않고 바이트를 읽고 쓰는 등의 고급 기능을 사용할 수 있습니다.
newByteChannel 메소드는 OpenOption 옵션 목록을 지정할 수 있습니다.
newOutputStream 메소드에서 사용하는 동일한 열린 옵션이 지원됩니다. 그리고 읽기 및 쓰기를 모두 지원하기 때문에 READ 옵션이 지원됩니다.
READ를 지정하면 읽을 채널이 열립니다. WRITE 또는 APPEND를 지정하면 쓸 수 있는 채널이 열립니다.
다음 예제는 채널을 이용해 파일을 읽고 출력합니다.
// Defaults to READ
try (SeekableByteChannel sbc = Files.newByteChannel(file)) {
ByteBuffer buf = ByteBuffer.allocate(10);
// Read the bytes with the proper encoding for this platform. If
// you skip this step, you might see something that looks like
// Chinese characters when you expect Latin-style characters.
String encoding = System.getProperty("file.encoding");
while (sbc.read(buf) > 0) {
buf.rewind();
System.out.print(Charset.forName(encoding).decode(buf));
buf.flip();
}
} catch (IOException x) {
System.out.println("caught exception: " + x);다음 에제는 로그 파일이 이미 있는 경우 로그 파일을 만들거나 로그 파일에 추가합니다. 로그 파일은 소유자에 대한 읽기/쓰기 권한과 그룹에 대한 읽기 전용 권한으로 생성됩니다.
import static java.nio.file.StandardOpenOption.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.file.*;
import java.nio.file.attribute.*;
import java.io.*;
import java.util.*;
public class LogFilePermissionsTest {
public static void main(String[] args) {
// Create the set of options for appending to the file.
Set<OpenOption> options = new HashSet<OpenOption>();
options.add(APPEND);
options.add(CREATE);
// Create the custom permissions attribute.
Set<PosixFilePermission> perms =
PosixFilePermissions.fromString("rw-r-----");
FileAttribute<Set<PosixFilePermission>> attr =
PosixFilePermissions.asFileAttribute(perms);
// Convert the string to a ByteBuffer.
String s = "Hello World! ";
byte data[] = s.getBytes();
ByteBuffer bb = ByteBuffer.wrap(data);
Path file = Paths.get("./permissions.log");
try (SeekableByteChannel sbc =
Files.newByteChannel(file, options, attr)) {
sbc.write(bb);
} catch (IOException x) {
System.out.println("Exception thrown: " + x);
}
}
}
