
Apache Kafka
Apache Kafka의 기본적인 내용만 다루겠습니다.
문서에서 Kafka에 대한 정의는 다음과 같다.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
카프카는 기본적으로 메시징 서버로 동작한다. 따라서 카파카의 동작 방식을 설명하기 전에 메시징 시스템에 대해 좀 알아보자면 메시지라고 불리는 데이터 단위를 보내는 측 Producer에서 카프카에 토픽이라는 각각의 메시지 저장소에 데이터를 저장하면 가져가는 측 Consumer가 원하는 토픽에서 데이터를 가져가게 되어있다.
중앙에 메시징 시스템 서버를 두고 이렇게 메시지를 보내고 받는 형태의 통신을 Pub/Sub 모델이라고 한다.
Kafka Architecture
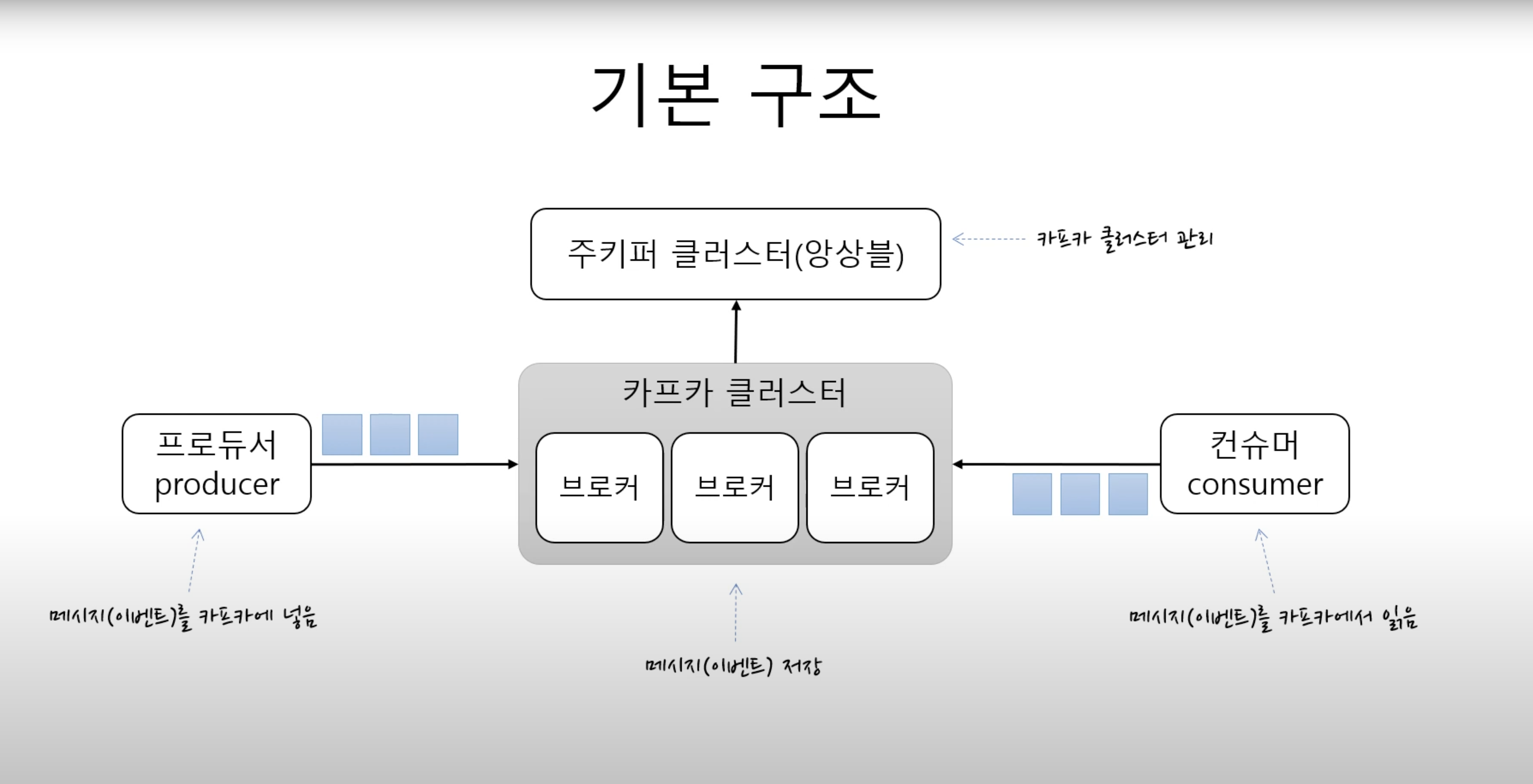
Kafka Cluster
Kafka 클러스터는 하나 이상의 Broker로 구성된다. 주로 하는 역할은 Broker의 Controller로서 역할을 한다.
Broker
Producer로 부터 들어온 메시지를 저장하고 Cosumer가 이 메시지를 topic 별로 각 patition에서 offset을 기준으로 fetch 할 수 있도록 한다.
이중화를 하고 장애에 대응하는 역할도 한다.
Zookeeper Cluster
Zookeeper는 분산 시스템에서 서비스 동기화와 naming registry를 위해서 사용한다.
주로 하는 일은 Apache Kafka Cluster의 상태를 추적하고 관리하는 역할과 Kafka topic 및 message, 파티션들을 관리한다.
이외에도 Zookeeper는 모든 파티션에서 리더 팔로우 관계를 유지해주는 역할을 하도록 컨트롤러를 선택해주는 역할을 하기도 한다.
Producer
데이터 스트림을 생산하는 역할을 producer가 합니다. 토큰 또는 메시지를 생성하고 이를 Kafka 클러스터의 하나 이상의 topic에 추가로 append 하기 위해 Apache Kafka Producer를 사용합니다
Consumer
Consumer는 Consumer Group에 속해서 topic을 subscribe 하고 해당 topic에 있는 partition에 데이터가 들어있다면 그 데이터를 가지고 오는 역할을 합니다.
Topic
토픽은 메시지를 구분하는 단위로 사용한다. 파일 시스템의 폴더와 같은 역할을 한다고 생각하면 좋다.
한 개의 토픽은 한 개 이상의 파티션으로 구성된다. 즉 A 브로커에 A 토픽과 P 파티션이 있을 수 있고 B 브로커에 같은 A 토픽과 P1 파티션이 있을 수 있다.
그러므로 Producer는 메시지를 저장할 때 어떤 토픽에 저장할지 결정해야하고 Consumer도 어떤 토픽에서 데이터를 읽어올건지 결정해야 한다.
Partition
파티션은 오로지 추가만 가능한 append-only 파일이다. 그러므로 Producer가 넣은 메시지는 파티션의 맨 뒤에 추가된다.
그리고 각 메시지가 저장된 위치가 offset이다. 그러므로 Consumer는 offset 기준으로 메시지를 순서대로 읽는다.
메시지는 삭제되지는 않는다. 컨슈머가 읽은거랑은 상관없다. 다만 설정을 통해 일정 시간 지나면 삭제가 가능하도록 할 수 있다.
하나의 토픽은 여러 파티션으로 구성될 수 있다고 했는데 Producer는 어떤 파티션을 정해서 저장할까?
라운드 로빈 방식으로 돌아가면서 파티션에 저장하는것도 가능하고 파티션을 명시적으로 지정해서 보내는것도 가능하다
그리고 Producer가 메시지를 보낼때 토픽 이름 뿐 아니라 키도 지정할 수 있다. 같은 키를 갖는 메시지는 같은 파티션에 저장된다.
이런식으로 같은 파티션에 메시지를 보내게되면 메시지 순서를 보장할 수 있다.
Consumer는 Consumer Group에 속해야 하며 한 개의 파티션은 한 개의 Consumer Group에 속한다. 다시 말하면 한 Consumer Group에서 토픽에 대한 파티션을 연결했다면 동일한 Consumer Group에 있는 Consumer는 동일한 토픽에 있는 다른 파티션을 사용할 수 없다.
한 Consumer Group 기준으로는 파티션의 메시지는 순서대로 처리해야한다.
Performance
Kafka는 성능이 매우 좋다고 한다. 그 이유를 알아보자.
Kafka는 Scale Out에 열려있다. 각각의 하는 일은 독립적으로 구분되어 있기 떄문에 성능의 한계가 온다면 브로커와 파티션을 늘린다던지 Consumer 개수들을 수평적으로 늘려서 해결할 수 있다. 주의할 점은 Consumer의 개수를 브로커보다 늘리면 놀고 있는 Consumer가 생길 수 있다는 점이다.
Kafka 파티션 파일은 OS에서 pagecache를 사용한다.
pagecache는 리눅스 커널에 의해서 사용되는 메인 디스크 캐시로 사용된다. 커널은 디스크에서 읽거나 쓸 때 이 페이지 캐시를 참조한다. user-mode 프로세서의 읽기 요청을 처리하기 위해서. 페이지가 캐시되어 있지 않다면 디스크로부터 새로운 Entity를 읽어와서 캐시에 더해준다 충분한 메모리가 있다면 이 페이지들은 계속 유지될거고 다른 프로세스에 접근할 수 있다. 이 방법을 통해서 데이터를 가져올 때 디스크에 접근하지 않아도 되므로 성능상에 우위가 있다.
Kafka는 메시지를 저장하고 캐싱하기 위해 파일 시스템에 의존하고 있다. 실제로 디스크는 사용하는 방법에 따라 훨씬 느려짏수도 빨라질수도 있다.
디스크 linear write 성능은 600MB/sec 로 random write 성능 100k/sec 보다 6000배 이상 차이를 낼 수 있다. 이러한 linear read and write 를 이용하면 최적화를 할 수 있다.
Kafka는 Producer에서 Broker로 데이터를 보낼때 순차적으로 그리고 데이터를 그룹 단위로 보내기 (Batch 작업을 하는) 떄문에 성능상에서 이점이 있다.
또 다른 비효율성을 해결하는 방법은 Byte copying을 해결하는 것인데 일반적인 어플리케이션의 데이터 전송 과정은 다음과 같다.
- The operating system reads data from the disk into pagecache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
이 과정은 4번의 카피와 2번의 시스템 콜을 필요로 하는데 비효율적이다. 리눅스에서는 sendfile이라는 시스템 콜을 통해서 pagecache로 부터 socket으로 바로 데이터를 전송하는 방법이 있다. 이 방법을 사용하면 한번의 byte copy만 하면 되니까 성능을 높일 수 있다.
이 방법은 zero-copy 라고 하머 하나의 토픽을 구독하고 있는 Consumer가 여러명 일때 유용하다. 데이터는 pagecache에 한번만 복사하면 데이터를 전송할때 user-space에 복사하지 않아도 되므로 성능을 높일 수 있다.
요약하자면 Kafka의 성능은 pagecache와 batch 기능 그리고 sendfile을 이용한 zero-copy를 통해서 성능을 높일 수 있다.
마지막으로 Broker는 메시지 필터와 메시지 재전송과 같은 일을 하지 않는다. Producer와 Consumer가 해야하므로 하는 일이 간단하기 때문에 더 나은 성능을 제공해줄 수 있다.
Replica
파티션의 복제본을 말한다. replication factor 만큼 파티션의 복제본이 각 브로커에 생기게 된다.
복제본이 있는 만큼 파티션은 리더와 팔로우로 파티션은 구성된다.
Producer와 Consumer는 리더를 통해서만 메시지를 처리하도록 하고 팔로우는 리더로부터 데이터를 복사하고 가지고 있다.
리더가 속한 브로커가 장애가 생기면 다른 팔로워가 리더가 되도록 구성되어 있다.
Producer 좀 더 자세하게
Basic Producer Example
public class BasicProducerExample {
public static void main(String[] args){
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka.example.com:6667");
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.RETRIES_CONFIG, 0);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
TestCallback callback = new TestCallback();
Random rnd = new Random();
for (long i = 0; i < 100 ; i++) {
ProducerRecord<String, String> data = new ProducerRecord<String, String>(
"test-topic", "key-" + i, "message-"+i );
producer.send(data, callback);
}
producer.close();
}Properties를 통해서 Kafka Producer 설정을 할 수 있다. 주요 설정은 다음과 같다.
Core Configuration: BOOTSTRAP_SERVERS_CONFIG 설정을 통해서 Producer는 연결할 Kafka 클러스터를 찾을 수 있다.
Message Durability: ACKS_CONFIG 설정을 통해 Kafka에 쓰여진 메시지의 Durability 설정을 할 수 있다. 디폴트 설정은 1로 파티션 리더가 메시지를 정상적으로 받았다는 신호를 받으면 성공적으로 마무리 된다. 받지 못하면 재전송을 하도록 한다.
0으로 설정한다면 메시지가 성공적으로 전송됐다는 신호를 받지 않는다. 그 만큼 성능상의 우위를 점할 수 있지만 Durability를 위해 추천되는 특징은 "all"로 파티션 리더 뿐 아니라 팔로워까지도 메시지를 성공적으로 복사했다는 신호를 받도록 한다.
Producer가 "all" 로 설정했다면 min.insync.replicas 을 설정할 수 있다. 예로 이 값을 2로 설정을 했다면 리더와 팔로워 합쳐서 2명이 메시지를 성공적으로 수집 했다면 저장에 성공했다고 응답을 받도록 한다.
Message Ordering: 일반적으로 브로커에 메시지가 쌓이는 순서는 Producer가 메시지 보내는 순서와 같다. 하지만 메시지가 네트워크상에 유실이되서 다시 재전송을 해야한다면 메시지 순서가 바뀔 수 있다. 만약 재전송을 하는데 데이터 순서를 보장하고싶다면 max.in.flight.request.per.connection 설정을 1로 하면 된다. 이 값은 블로킹 없이 한 커넥션에서 전송할 수 있는 최대 전송중인 요청 개수를 말한다.
Batching and Compression: Kafka Producer는 메시지를 모아서 한번에 전송하는 배치 방식을 사용해서 성능을 높인다.
batch.size 옵션을 통해서 메시지 배치 사이즈를 조절할 수 있다. batch.size가 작다면 i/o가 자주 발생하므로 성능에 좋진 않다. linger.ms 옵션으로 배치가 찰 때까지 충분한 시간을 제공해줄 수 있다 Producer는 linger.ms 값 만큼 기다렸다가 보내는 역할을 한다.
Compression은 compression.type에 따라 활성화 할 수 있다. 압축은 배치가 클수록 효율이 높다.
그리고 snappy 압축을 사용할려면 /tmp 디렉토리에 대한 쓰기 엑세스 권한이 필요하다.
batch.num.messages 를 사용하여 각 배치에 포함된 메시지 수에 대한 제한을 설정하는 것도 가능하다.
Queuing Limits: buffer.memory 를 이용해 아직 보내지 않는 메시지가 저장되어 있는 메모리를 제한할 수 있다.
이 제한이 적용되면 Producer는 max.block.ms만큼 추가 전송을 차단하게 된다.
또한 request.timeout.ms 를 설정해서 시간 초과를 설정할 수 있다. 메시지를 성공적으로 보내기 전에 이 시간 초과가 발생하면 대기열에서 해당 메시지가 제거되고 예외가 발생한다.
buffering.max.buffer는 주어진 시간 동안 큐에 쌓여있는 보낼 메시지 수를 제한할 수 있다. queue.buffering.max.ms는 브로커에게 메시지를 보내기 전 배치를 메시지로 채우는 시간을 설정한다.
Consumer 좀 더 자세하게
Consumer groups
Consumer Group은 일부 topic들에 대한 데이터를 사용하기 위해 협력하는 Consumer들의 그룹을 말한다.
모든 topic 들에 대한 파티션은 그룹 내 Consumer 들에게 분배된다.
새로운 Consumer가 들어오고 오래된 Consumer가 나갈 수 있는데 이때 파티션은 재할당된다. 이를 리밸런싱(rebalancing)이라고 한다.
Basic Consumer Exmaple
public class BasicConsumerExample {
public static Consumer<Long, String> BasicConsumerExample() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, IKafkaConstants.KAFKA_BROKERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, IKafkaConstants.GROUP_ID_CONFIG);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, IKafkaConstants.MAX_POLL_RECORDS);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, IKafkaConstants.OFFSET_RESET_EARLIER);
Consumer<Long, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(IKafkaConstants.TOPIC_NAME));
return consumer;
}
}Properties를 통해서 Kafka Consumer 설정을 할 수 있다. 주요 설정은 다음과 같다.
Core Configuration: BOOTSTRAP_SERVERS_CONFIG 설정을 통해서 Consumer는 연결할 Kafka 클러스터를 찾을 수 있다.
Group Configuration: 단순한 API를 사용할 것이고 offset을 Kafka에 저장할 필요가 없는 경우가 아니라면 GROUP_ID 를 지정해서 Consumer Group을 등록해야 한다.
session.timeout.ms 설정을 통해서 session timeout을 오버라이딩 할 수 있다. 이 값을 올림으로써 리밸런싱이 자주 일어나는 걸 막을 수 있다. 기본 값은 10초다. 뭐 예를 들면 네트워크 설정이 안좋거나 long GC Pause 때문에 잠시 끊기는 경우가 일어날 수 있다고 생각이 든다면 이 값을 올릴 수 있다.
session.timeout.ms 값을 올리는 단점은 Coordinator가 문제가 생긴 Consumer를 발견하는 상황이 더 늦어진다는 것이다. 그러므로 그 Consumer에게 할당되어 있는 파티션을 다른 Consumer에게 옮기는 시간도 늦어진다. 하지만 정상적인 종료의 경우 Consumer는 Coordinator에게 알려주고 Coordinator는 바로 리밸런싱을 할 수 있다.
리밸런싱에 또 다른 영향을 주는 세팅으로는 heartbeat.interval.ms가 있다. 이 설정은 Consumer가 Coordinator에게 나 살아있다고 얼마나 주기적으로 신호를 보내는 지를 결정해준다. 또 이 값은 리밸런싱시에 Consumer가 감지하는 시간이기도 해서 이 값이 낮으면 그만큼 리밸런싱이 빨라진다. 기본값은 3초로 설정되어 있으며 Consumer Group에 Consumer가 많다면 이 값을 올리는걸 추천한다.
마지막으로 리밸린성이 영향을 주는 요소로는 max.poll.interval.ms 가 있습니다. 이 값 시간 동안 Consumer가 poll 메소드를 호출하지 않으면 실패한 것으로 간주하고 리밸런싱을 진행합니다. 기본 값은 300초이며 프로그램에서 메시지를 처리하는데 더 긴 시간이 필요하다면 안전하게 늘릴 수 있습니다. Java에서 poll 메소드를 호출하는 루프에서 max.poll.records 값을 통해 루프에서 치리하는 레코드 수를 조절할 수 있습니다.
Offset Management: Offset Management에 영향을 주는 요소로 auto-commit의 활성화 여부와 offset reset 정책 이렇게 두 가지가 있다.
enable.auto.commit 값은 기본적으로 활성화 되어있는데 이 값을 사용하면 자동으로 offset을 주기적으로 commit 한다. 그 간격은 auto.commit.interval.ms으로 설정할 수 있다. 기본값은 5초이다.
두 번째로는 auto.offset.reset에 관한 정책인데 그룹이 첫번째로 초기화되거나 offset이 범위 밖으로 벗어난 경우에 offset의 position을 초기화 할 수 있다. offset을 reset할 때 어디로 초기화할 지 정할 수 있는데 기본적으로는 "latest"값을 기준으로 초기화하지만 "earliest"으로 설정할 수 있다.
Kafka 주요 설정
빠르게 카프카를 구성해서 장애 없이 잘 사용하고 싶은데 그렇다고 카프카를 모두 공부해서 사용할 시간은 부족하다.
이런 경우 일단 카프카의 기본 설정으로 사용하게 되는데 이런 경우 일정기간 사용하다보면 문제가 발생할 수 있다.
카프카의 기본 옵션 중 일부만 미리 변경해서 사용한다면 카프카 운영을 보다 안정적으로 사용할 수 있다. 이것들에 대해서 조금 알아보자.
log.retention.hours=72
retention 옵션을 기본값으로 사용한다면 나중에 디스크가 다차는 문제가 발생할 수 있다.
이 옵션이 가지는 의미는 카프카에서 토픽으로 저장되는 모든 메시지를 해당 시간만큼 보관하겠다는 의미다.
기본값이 168시간으로 7일을 의미하는데 예제를 위해 계산하기 쉽게 메시지 하나가 1KB라고 가정하고 10,000/sec의 메시지가 카프카로 유입된다고 가정하고 마지막으로 7일을 보관하겠다고 계산을 해보면 다음과 같다.
1KB * 10,000(초당 메시지 수) * 60(1분) * 60(1시간) * 24(1일) * 7(일) * N(레플리카 수) * T(토픽의 수)
여기서 레플리카 수를 3이라 하고 메시지 토픽이 10개 있다고 가정해서 계산을 해보면 168TB라는 숫자가 나오게 된다.
하지만 retention 숫자를 168이 아닌 72로 바꾼다면 즉 3일로 바꾼다면 168TB도 72TB로 바뀌게 된다. 필요로 하는 디스크 공간을 많이 줄일 수 있다.
대부분 많은 카프카에 있는 메시지를 실시간으로 가져가고 있기 때문에 7일이나 보관한다는 의미는 필수적이라고 생각하지는 않는다.
retention 시간 값을 정확히 72로 고정시킨 이유는 일의 라이프 스타일을 고려해서 결정된 값이다. 주말에 장애가 나더라도 이 로그는 월요일까지 살아있을 것이다.
그래서 72라는 값을 추천하는 것이니 카프카를 사용하기 전에 해당 옵션에 대해 한번 고민해보는 걸 추천한다.
delete.topic.enable=true
이 옵션은 카프카의 토픽 삭제와 관련된 옵션이다. 만약 허용하지 않는다면 삭제를 하더라도 삭제되지 않고 삭제 표시만 남아 있게 된다.
예를 들면 만약 위의 경우처럼 디스크가 가득 차서 토픽을 삭제해야 하는데 해당 옵션이 적용되어 있지 않다면 토픽을 삭제할 수 없는 상황이 발생하게 된다.
그러므로 해당 옵션을 확인해서 토픽을 삭제할 수 있도록 변경하는 걸 추천한다. 내가 필요할 때 언제든 토픽을 삭제할 수 있도록.
allow.auto.create.topics=false
이 옵션은 토픽 자동생성과 관련된 옵션이다. 토픽 메시지를 Producer가 보내기 전에 토픽을 미리 카프카에 만들어놔야 하는데 만약 관리자가 실수로 카프카에 토픽을 미리 생성하지 않은 상태라면 이 옵션이 true로 설정되어 있다면 자동으로 토픽을 생성해주는 기능이다.
되게 편리해 보이는 기능인데 경우에 따라선 매우 좋지 않은 기능이기도 하다.
분명 필요하지 않은 토픽이라 생각해 지웠는데 어디선가 자꾸 토픽이 생겨나기도 해서 관리자가 알지도 못하는 토픽이 자꾸 발생하는 문제가 일어나기도 한다.
그러므로 이 옵션은 false로 사용하기를 권장한다.
log.dirs=/data
해당 옵션은 각 토픽들의 메시지들이 저장되는 실제 경로를 말한다. 최근 서버들을 보면 OS 영역은 용량이 적은 정도의 디스크로 사용하고 데이터 디렉토리를 별도의 용량이 큰 디스크를 사용하기도 한다.
하지만 이 옵션을 통해 용량이 큰 별도의 디스크 경로로 설정해주지 않는다면 기본값이 /tmp/kafka-logs로 설정되어 있어서 OS 영역의 디스크를 사요하게 되고 결국 용량이 가득차는 경우가 발생할 수 있다.
해당 옵션을 확인해 미리 설정한다면 이런 장애 상황을 방지할 수 있다.
