TIME_WAIT 소켓이 서비스에 미치는 영향
여기서는 TCP 소켓의 TIME_WAIT 상태가 무엇을 의미하고 왜 발생하는지, 어떤 문제를 일으킬 수 있는지 알아보겠다.
TCP 통신 과정
TIME_WAIT 에 대해서 이야기 하기 전에 먼저 TCP 통신 과정을 살펴보자.
다음 그림은 TCP 에서 통신을 하기 위해서 처음 연결을 맺는 3-way handshake 과정이다.
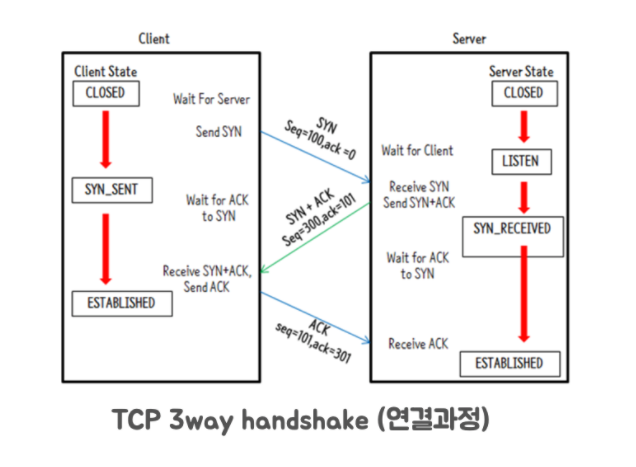
- 연결을 시도하는 쪽은 먼저 SYN 패킷을 받는다.
- 연결 시도를 받는 쪽은 응답으로 SYN + ACK 패킷을 보낸다.
- 그 다음 연결을 시도하는 쪽에서 ACK 패킷을 보내면서 연결이 설립 (Established) 된다.
다음은 통신을 모두 마친 후 연결을 종료하는 4-way handshake 과정이다.
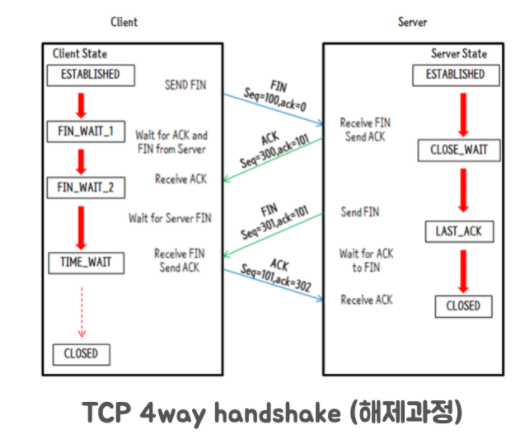
- 먼저 연결을 끊으려는 쪽이 FIN 패킷을 보낸다.
- 연결 끊음을 당한 쪽은 CLOSE_WAIT 상태가 되고 응답으로 ACK 패킷을 보낸다.
- 이후 연결 끊음 당한 쪽이 연결 끊을 준비가 되면 FIN 패킷을 보내고 LAST_ACK 상태가 된다.
- FIN 패킷을 받으면 TIME_WAIT 상태가 되고 응답으로 ACK 패킷을 보내고 MSL (Double Maximum Segment Life) 동안 기다리고 종료한다. 여기서 MSL 은 2 분정도 된다.
TIME_WAIT 상태는 먼저 연결을 끊으려는 쪽에서 일어나는 상태이며 주요 문제점은 완전히 연결을 종료할 때까지 2 분정도 대기한다는 문제다. 이로인해 소켓 고갈이 날 수 있다.
- 예로 서버측에서 DB 와 통신할 때 데이터를 전달 받은 후 연결을 종료하는 경우가 많은데 이 경우 소켓 고갈이 발생한다.
- 소켓 고갈은 포트 고갈로 인해서 외부와 통신을 할 수 없다. 이로인해 어플리케이션에서 타임 아웃이 발생한다.
이런 문제 뿐 아니라 TCP 커넥션을 자주 맺고 끊는 행동은 불필요한 3-way handshake 와 4-way handshake 를 반복하는 것이다.
그리고 잦은 TCP 연결 맺기/끊기는 서비스의 응답 속도 저하를 일으킬 수도 있다. 이 문제를 막기 위해서 Client 측에서 Connection pool 을 사용하거나 Keepalive 설정을 해서 소켓을 재사용하도록 하면 된다.
TIME_WAIT 소켓이 얼마나 있는지 확인하기 위해서는 netstat -napo | grep -i time_wait 를 통해서 볼 수 있다.
TIME_WAIT 의 상태와 존재 이유
TIME_WAIT 의 상태는 왜 존재할까? 이 이유는 연결을 끊으려고 시도했던 쪽이 마지막으로 ACK 패킷을 보내게 되는데 이 패킷이 유실될 가능성이 있기 때문이다.
위의 과정을 보면 연결 끊음을 당하는 쪽에서 FIN 패킷을 보내게 되면 연결 끊음을 시도했던 쪽이 TIME_WAIT 상태가 되면서 ACK 패킷을 보내게 된다.
여기서 ACK 패킷이 유실되었다면 연결 끊음을 당한 쪽은 자신이 보낸 요청에 응답이 안와서 다시 FIN 패킷을 보내게 된다.
근데 TIME_WAIT 상태가 없거나, 너무 짧은 경우라면 이 FIN 패킷에 응답을 할 수 없어서 정상적인 종료가 불가능하다.****
Case Study - nginx upstream 에서 발생하는 TIME_WAIT
다수의 TIME_WAIT 가 발생하게 되는 실제 경우를 보자.
보통 Java 기반의 어플리케이션을 개발하게 되면 웹 서버로 톰캣 (tomcat), 네티 (netty) 를 이용하게 되는데 이를 앱 서버라고 하겠다.
그리고 이런 앱 서버 앞단에 요청을 처음 맞는 nginx 같은 서버를 두게 된다. 이를 웹 서버라고 두겠다.
앱 서버의 keep-alive 없이 서비스를 운영하게 되면 웹 서버에서 들어온 요청을 앱 서버로 전달해야 하는데 이때 TCP 연결 맺음/끊기 가 반복되게 되면서 웹서버의 TIME_WAIT 상태의 소켓이 많아져서 문제가 된다.
TCP Keepalive 를 이용한 세션 유지
여기서는 TCP Keepalive 옵션을 이용해서 TCP 기반의 통신에서 세션을 유지하는 방법에 대해서 알아보려고 한다.
이전에도 말했지만 keep-alive 는 두 종단 간 맺은 세션을 이용해서 통신이 일어날 때마다 3-way-handshake 와 4-way-handshake 를 하지 않고 유지중인 세션을 이용하는 방식이다.
여기서는 이를 통해 시스템이 얻는 것은 뭐고, 주의해야 할 점이 뭔지 알아보자.****
TCP Keepalive 란?
TCP Keepalive 가 세션을 유지하는 방식은 일정 시간이 지나면 연결된 세션에서 두 종단이 살아있는지 확인하는 아주 작은 양의 패킷을 보내고 수신하는 걸 통해서 일어난다.
양쪽 모두 이 패킷을 보낼 필요는 없고 한 쪽 에서만 보내도 된다. 즉 클라이언트 서버 둘 중 하나라도 이 기능을 사용한다면 세션은 유지된다.
서로 Keepalive 를 확인하기 위한 패킷을 주고 받은 후 다시 타이머는 돌아가는 식으로 주기를 가지면서 확인을 한다.
현재 사용하고 있는 네트워크 소켓이 Keepalive 를 사용하고 있는지 확인하고 싶다면 netstat 명령을 통해서 보면 된다.
ubuntu@ip-192-168-111-182:~$ netstat -napo
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN - off (0.00/0/0)
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN - off (0.00/0/0)
tcp 0 0 192.168.111.182:22 61.177.173.12:27908 SYN_RECV - on (2.15/5/0)
tcp 0 404 192.168.111.182:22 223.62.174.78:34873 ESTABLISHED - keepalive (70.54/0)
tcp 0 0 192.168.111.182:36638 52.78.32.75:80 TIME_WAIT - timewait (37.96/0/0)
tcp6 0 0 :::22 :::* LISTEN - off (0.00/0/0)
udp 0 0 127.0.0.53:53 0.0.0.0:* - off (0.00/0/0)
udp 0 0 192.168.111.182:68 0.0.0.0:* - off (0.00/0/0)
raw6 0 0 :::58 :::* 7 - off (0.00/0/0)- 여기 TIMER 항목에 keepalive 가 있으면 소켓이 Keepalive 를 사용하고 있다는 뜻이다.
TCP Keepalive 를 사용하고 싶다면 소켓을 생성할 때 소켓 옵션을 주면 된다. 소켓 옵션은 setsockopt() 라는 함수를 통해서 소켓 옵션을 설정하는데 이 옵션에서 SO_KEEPALIVE 를 선택하면 TCP Keepalive 를 사용하는게 가능하다.
이건 소켓을 직접 생성하는 경우면 이렇고 대부분의 어플리케이션에서는 TCP Keepalive 를 지원하는 별도의 옵션이 있을 것이다.
TCP Keepalive 의 파라미터들
TCP Keepalive 를 유지하는 데 필요한 커널 파라미터들은 총 3 개가 있다.
net.ipv4.tcp_keepalive_time: 가장 중요한 값인 tcp_keepalive_time 을 보자. 이름이 의미하는 것처럼 소켓의 유지 시간을 말한다. 타이머는 이 시간을 기준으로 동작하며 이 시간이 지나면 keepalive 확인 패킷을 보낸다. 이 값을 직접 지정하는게 가능하고 기본 값은 240 초이다.net.ipv4.tcp_keepalive_probes: tcp_keepalive_probe 는 keepalive 패킷을 보낼 최대 전송 횟수를 말한다. keepalive 패킷에 한번 응답하지 않았다고 해서 바로 연결을 종료하는 건 아니다. 네트워크 상의 패킷은 언제든지 다양한 원인으로 유실될 수 있다는 걸 알아야한다. 그렇다고 무한정 재전송하는 건 아니니 tcp_keepalive_probes 로 최대 재전송 횟수를 정해야 한다. 기본 값은 3 으로 최초의 keepalive 패킷을 포함해서 총 3 번의 패킷을 보내고 그 후에도 응답이 없으면 연결을 끊는다.net.ipv4.tcp_keepalive_intvl: tcp_keepalive_intvl 은 재전송 패킷을 보내는 주기를 말한다.
원래는 소켓이 종료할 때 FIN 패킷을 보내면서 종료를 한다. keepalive 를 사용할 땐 재전송을 한 후에도 응답이 없는 경우에는 FIN 패킷에 대한 응답을 보낼 수 없는 상태일 것이니 커널에서 알아서 끊어진 세션으로 판단하고 소켓을 종료한다.****
TCP Keepalive 와 HTTP Keepalive
흔히 TCP Keepalive 와 HTTP Keepalive 를 혼동하는 경우가 많다. 여기서는 이 두 Keepalive 의 차이점에 대해서 알아보자.
아파치와 nginx 와 같은 웹 어플리케이션에서도 keepalive timeout 이라는 것이 존재한다. HTTP/1.1 에서 지원하는 keepalive 를 위한 설정 항목이다. 용어가 비슷해서 헷갈릴 수 있지만 두 항목은 큰 차이가 있다.
TCP Keepalive 는 두 종단 간의 연결을 유지하기 위함이지만, HTTP Keepalive 는 최대한 연결을 유지하는 것이 목적이다. 만약 두 값 모두 60 초라면 TCP Keepalive 는 60 초 간격으로 연결이 유지되었는지를 확인한다면 HTTP Keepalive 는 60 초 후에도 연결이 안오면 요청을 끊는다.
두 값이 다르면 어떤 일이 벌어질지 걱정할 수 있지만 TCP Keepalive 의 연결을 확인하려는 패킷이 HTTP Keepalive 의 연결 유지에 영향을 주지 않는다. 즉 TCP Keepalive 를 HTTP Keepalive 보다 높게 설정하던 낮게 설정하던 HTTP Keepalive 에서 설정한 시간동안 HTTP 요청이 오지 않는다면 소켓은 종료된다.
TCP 재전송과 타임아웃
TCP 는 특성상 자신이 보낸 데이터를 상대방이 받았다는 응답의 패킷을 보내야 자신이 제대로 보냈다는 걸 확인할 수 있다.
즉 응답 패킷을 받지 못하면 상대방이 받지 않았다고 생각해서 다시 패킷을 보내도록 한다. 이런 과정이 네트워크 성능 저하를 가지고 올 수 있지만 TCP 특성상 필요한 일이다.
그래서 이번에는 TCP 재전송이 일어나는 과정을 보고 이로인해 발생할 수 있는 애플리케이션 타임아웃에 대해서 알아보자.
TCP 재전송은 생각보다 자주 일어날 수 있는 일이며, 이를 대비할 수 있는 예외 처리는 서비스 품질 유지에 도움이 된다.
TCP 재전송과 RTO
TCP 는 패킷을 보낸 쪽이 받았다는 ACK 를 받지 못하면 재전송을 하게 된다. 여기서 ACK 를 얼마나 기다려야 하는지에 대한 값을 RTO (Retransmission Timeout) 이라고 부른다.
즉 RTO 안에 ACK 를 받지 못하면 보내는 쪽에서 재전송을 진행한다.
RTO 에는 일반적인 RTO 과 InitRTO 두 가지가 있다. 일반적인 RTO 는 RTT (RoundTripTime, 두 종단 패킷 전송에 필요한 시간) 을 기준으로 설정된다. 예로 두 종단 간 패킷이 전송되는 시간이 1 초라면 이게 RTT 이다.
InitRTO 는 두 종단 간 최초 연결을 시작할 때, TCP 3_way_handshake 에서 SYN 패킷에 대한 RTO 를 의미한다. SYN 패킷을 보낼 당시에는 RTT 와 같은 정보가 없으니 임의로 설정한 값으로 RTO 를 계산하는데 리눅스에서는 소스 코드에 1 초로 구현해 놓았다.
리눅스에서는 ss -i 명령을 통해서 현재 세션에 설정되어있는 RTO 값을 볼 수 있다.
- 여기서 나오는 값은 ms 단위이다.****
재전송을 결정하는 커널 파라미터
재전송과 관련된 커널 파라미터는 총 5 개의 값이 있다. 이건 sysctl -a | grep -i retries 명령을 통해서 조회가 가능하다.
- net.ipv4.tcp_syn_retries = 5
- net.ipv4.tcp_synack_retries = 5
- net.ipv4.tcp_retries1 = 3
- net.ipv4.tcp_retries2 = 15
- net.ipv4.tcp_orphan_retries = 0
먼저 net.ipv4.tcp_syn_retries 부터 살펴보자. TCP 재전송은 이미 연결되어 있는 세션에서도 일어나지만 연결을 시도하는 과정에서도 일어난다. 이 값은 바로 처음 연결을 시도하는 SYN 패킷에 대한 재시도 횟수를 결정한다. 기본 값은 5 이다.
즉 5 번의 재전송 이후에도 연결이 되지 않으면 연결하지 않는다. 실제로 와이어샤크로 TCP dump 를 떠보면 이를 볼 수 있다.
이 값을 줄이면 좀 더 빠르게 새로운 연결에 대한 타임아웃을 설정하는게 가능하다. 애플리케이션 단에서 연결의 타임아웃 설정이 없다면 이 커널 파라미터를 통해서도 조절하는게 가능하다.
하지만 TCP 스펙에서는 최소 5 로 하길 권장한다.
두 번째는 net.ipv4.tcp_synack_retries 이다. 이름에서도 알 수 있듯이 상대편이 연결을 위해서 보낸 SYN 패킷에 대한 응답으로 보내는 SYN + ACK 패킷에 대한 재전송 횟수를 정의하는 값이다. 기본 값은 5 이고 상대방의 SYN 패킷에 대해서 최대 5 번의 SYN + ACK 패킷을 보낸다는 의미다.
이 값이 중요한 이유는 소켓 처리와 관련이 있어서인데 SYN 패킷의 요청을 받으면 소켓은 SYN + ACK 패킷을 보내고 SYN_RECV 가 된다. 그리고 응답 패킷이 오지 않으면 기본적으로 최대 5 번의 재전송을 하게 되고 요청이 안오면 종료가 되는데 이 값이 없다면 계속해서 SYN_RECV 상태로 유지되서 리소스가 고갈될 수 있기 떄문에 이 값이 반드시 있어야 한다.
- 디도스의 공격이 SYN 패킷만 보내서 SYN_RECV 상태로 만들어놓는 식의 공격이다. SYN + ACK 로 보내도 대답해주지 않는다.
세 번째는 net.ipv4.tcp_orphan_retries 이다. orphan socket 이라 불리는 상태의 소켓들에 대한 재전송 횟수를 결정한다.
그렇다면 orphan socket 이 뭘까?
TCP 연결을 끊을 때 연결을 끊으려고 시도하는 쪽은 FIN 패킷을 보내고 FIN_WAIT 1 상태가 된다. 이 상태의 소켓이 orphan socket 이라고 불린다.
왜 FIN_WAIT2 상태나 TIME_WAIT 상태는 orphan socket 이라고 불리지 않을까?
내가 보냈던 패킷은 FIN 패킷밖에 없고 나머지는 TIME_WAIT 상태에서 응답을 보내는 패킷인 ACK 패킷만 있기 때문인데, 재전송은 내가 패킷을 보낸것에 대한 재전송을 말하는 것이지 응답을 보내는 용도가 아니기 때문이다.
그리고 orphan socket 으로 들어가면 더이상 소켓은 프로세스에 귀속되지 않는다. 오로지 커널에만 귀속되게 되며 재전송 횟수가 지나도 응답을 받지 못하면 커널에서 강제 회수한다.****
네 번째와 다섯 번째는 각각 net.ipv4.tcp_retries1 과 net.ipv4.tcp_retries2 값이다.
이 두 값은 서로 관련이 있는데 retries1 는 ip 레이어에 네트워크가 잘못되었는지 확인하는 기준이 되며 retries2 는 더이상 통신을 할 수 없다는 기준이 된다.
즉 전자를 soft threshold 후자를 hard threshold 라고 생각하면 되고 결과적으로 retries2 를 넘겨야 연결이 끊어진다.
재전송 추적하기
TCP 재전송을 추적하려면 어떻게 하면 될까? 간단한건 재전송이 의심되는 곳에서 tcpdump 를 뜨면 되는데 이는 너무 많은 패킷이 잡혀서 오히려 더 힘들 수 있다.
이럴 때 사용하면 좋은 툴이 바로 tcpretrans 스크립트이다. tcpretrans 스크립트를 살펴보면 1 초에 한번씩 깨어나서 ftrace 를 통해 수집한 후 커널 함수 정보를 바탕으로 재전송이 일어났는지 확인한 후, /proc/net/tcp 의 내용을 파악해서 어떤 세션에서 재전송이 일어났는지 확인한다.
RTO_MIN 값이 200ms 이기 때문에 1 초의 인터벌 간격은 재전송되는 패킷을 놓칠수도 있다. 좀 더 정확하게 추적이 필요하다면 interval 값을 200ms 로 수정해서 실행시카자.
RTO_MIN 값 변경하기
RTO_MIN 값은 200ms 이기 때문에 이보다 빠른 내부 통신에서도 200ms 밑으로 내려갈 수 없다.
커널 소스를 보면 TCP_RTO_MAX, TCP_RTO_MIN 으로 define 한 걸 볼 수 있는데 RTO 의 최댓값은 120 초 이고 최솟값은 200ms 이다.
그리고 일반적으로 RTO 는 RTT 를 바탕으로 설정되기 때문에 세션마다 다를 수 있다.
- RTO 의 값은 RTO_MIN + RTT_MAX 로 대충 추정하면 맞다. RTO 와 RTT 는
ss -i옵션으로 볼 수 있다.
만약 RTT_MAX 가 12.25ms 이고 편차가 1.5ms 라면 RTO 값은 214 정도가 잡힐 것이다. 근데 대부분의 패킷이 12.25ms 에서 결정되는 상황이라면 RTO 의 214 값은 너무 크지 않은가? 패킷 15 개 정도를 주고 받을 수 있을 정도의 시간이다. 대략적으로 50 ms 만 설정해도 괜찮을 수 있다.
이 값을 바꿀려면 리눅스에서 ip route 라는 명령의 rto_min 옵션을 통해서 TCP_RTO_MIN 보다 작게 바꾸는게 가능하다. 세션별로 바꿀 수는 없고 하나의 네트워크 디바이스를 기준으로 바꾸는게 가능하다. 문법은 다음과 같다.
ip route change default via <GW> dev <DEVICE> rto_min 100ms
변경 하려면 먼저 ip route 명령을 통해서 현재 서버에 설정되어 있는 라우팅 정보를 보자.
ubuntu@ip-192-168-111-182:~$ ip route
default via 192.168.111.161 dev ens5 proto dhcp src 192.168.111.182 metric 100
192.168.111.160/27 dev ens5 proto kernel scope link src 192.168.111.182
192.168.111.161 dev ens5 proto dhcp scope link src 192.168.111.182 metric 100- 여기서는 기본적으로 ens5 라는 네트워크 디바이스의
192.168.111.161주소를 통해서 나간다는 의미다.
이 정보를 통해서 RTO 값을 100ms 로 바꾸면 다음과 같다.
ip route change default via default dev ens5 rto_min 100ms****
애플리케이션 타임아웃
지금까지 리눅스 상에서 TCP 재전송이 언제 발생하는지 어떻게 횟수를 조절하는지에 대해서 알아봤는데 여기서는 TCP 재전송이 실제 어플리케이션에 끼치는 영향을 보겠다.
TCP 재전송이 일어나면 어플리케이션도 응답을 받지 못했기 때문에 타임아웃이 발생할 수 있다.
정확하게 말하면 애플리케이션 타임아웃 임계치를 몇 초로 설정했느냐에 따라서 타임아웃이 발생할 수도 발생하지 않을 수도 있다.
애플리케이션의 타임아웃은 크게 두 종류가 있다.
- Connection Timeout: TCP Handshake 과정에서 재전송이 일어날 수 있는 경우에 발생하는 타임아웃이다. (최소 권장은 3 초 이상이다.)
- Read Timeout: 맺어져 있는 세션을 통해서 데이터를 요청하는 과정에서 발생할 수 있는 타임 아웃이다. (최소 권장은 300ms 이상이다)
- 여기서 권장은 기본값을 사용한다는 기준이다.
Connection TImeout 은 SYN 패킷과 SYN + ACK 패킷의 재전송을 고려해서 신경써야 하는 값이다. 이 패킷들은 RTO 값을 계산할 수 없기 때문에 재전송 타임은 1 초로 설정된다. 즉 한 번의 유실을 허용할 것이라면 1 초 이상으로 설정하면 되고 두 번의 유실까지도 허용하려면 3 초 이상으로 설정하면 된다. (타이머로 인해서 재전송이 일어나면 다음 재전송 시간은 2 배씩 늘어난다.)
Read Timeout 은 몇 초로 설정하는 것이 좋을까? 이미 맺어진 세션에서 패킷을 읽어오는 것이기 때문에 작을 것이고 한 번의 재전송 정도는 커버할 수 있는 값으로 무조건 설정해야 한다. (재전송은 꽤 일어날 수 있다.)
일반적으로 RTO_MIN 값이 200ms 이고 맺어져 있는 세션이 재전송 할 때 최소한 200ms 시간이 필요하기 때문에 200ms 보다 큰 값인 300ms 정도면 한 번의 재전송은 커버할 수 있다. 물론 RTT 가 길어서 RTO 가 200ms 이상이라면 300ms 보다 더 크게 설정해야 한다. 하지만 내부 통신일 경우에는 RTT 가 짧아서 200ms 보다 커지는 경우는 없다.
