[컴퓨터 시스템] 동적 메모리 할당 - Explicit Free List의 개념과 구현
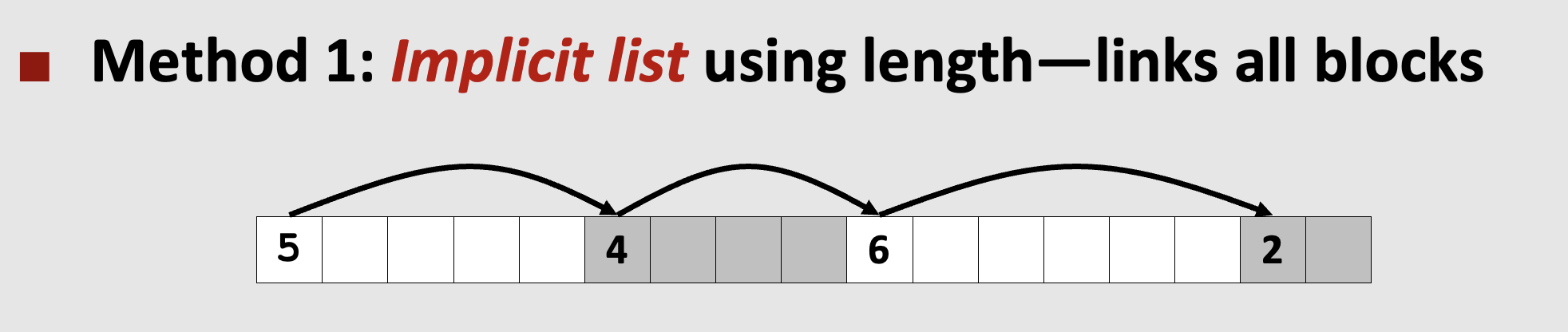
🤔 Implicit Free List의 제한점
이전 포스팅에서는 Implicit Free List (묵시적 가용 리스트)의 개념과 구현방법을 살펴봄으로써 메모리 할당기의 동작 방식을 살펴볼 수 있었다.
앞서 Implicit Free List에서 메모리를 어떻게 할당했는지 기억을 되살려보자.
Implicit Free List는 header와 footer에 현재 블록의 사이즈와 할당 여부 정보가 있어서 이를 바탕으로 이전 블록과 다음 블록의 위치를 파악할 수 있었다.
그런데 할당된 블록과 가용한 블록이 모두 연결되어 있기 때문에 새로 메모리를 할당하려고 하면 모든 블록에 대해 순회하면서 가용한 블록을 찾아야 했다.
즉, 블록 할당 시간이 전체 힙 블록의 수에 비례해서 증가하게 되는 것이다.
그렇면 가용한 블록끼리 연결되게 하면 할당된 블록을 탐색할 필요가 없으므로 가용 블록을 더 빨리 찾을 수 있지 않을까?
이 생각이 바로 Explicit Free List을 이해하는 출발점이 된다.
👀 Explicit Free List란?
Explicit Free List는 아래 그림과 같이 가용 블록끼리 포인터로 연결되는 구조를 가진다.
이러한 연결 방식을 사용하면 First Fit 할당을 할 때, Implicit Free List에서는 전체 블록 수에 비례하게 걸리던 시간을 Explicit Free List에서는 가용 블록의 수에 비례하는 시간으로 줄일 수 있다.
이 속도 차이는 메모리 영역에서 할당된 블록이 차지하는 비중이 높아질수록 더 커질 것이다.

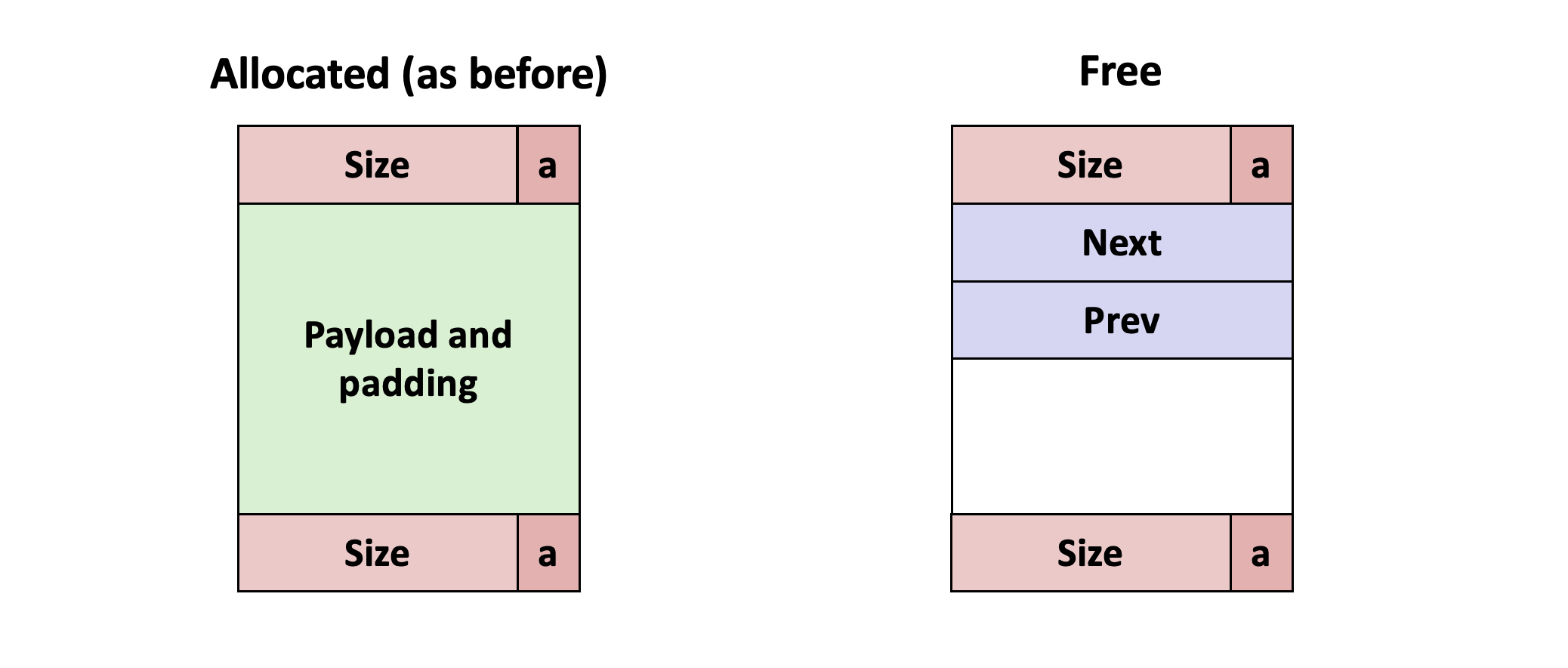
🧱 힙 블록의 포맷
Explicit Free List의 힙 블록 포맷을 살펴보면 아래와 같은데, 할당된 블록의 구조는 Implicit Free List와 동일하지만 가용한 블록의 구조에 차이가 있다.
Explicit Free List에서는 가용한 블록의 payload 영역에 이전 블록(prev, predecessor)의 포인터와 다음 블록(next, successor)의 포인터를 저장해둔다는 차이가 있다.
따라서 Implicit Free List와 비교했을 때 2 Word만큼의 공간을 더 사용하게 된다.
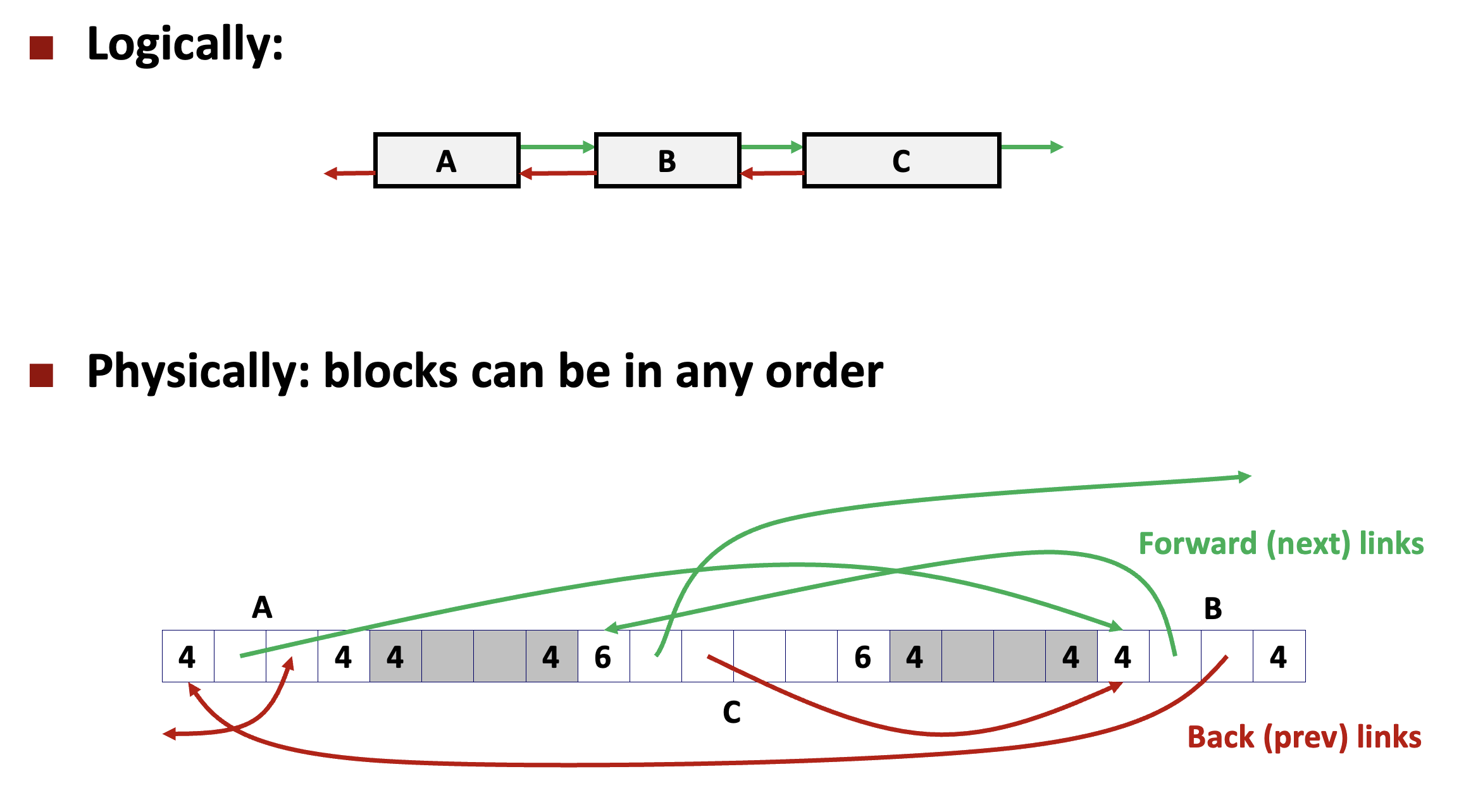
🔗 가용(free) 블록의 연결 방식
개념적으로는 Explicit Free List의 가용 블록들은 메모리 주소 순으로 연결되어 있다고 보면 된다.
하지만 실제 배열에서 가용한 블록들의 순서는 메모리 주소순으로 정렬되어 있을 수도 있고, 아닐 수도 있다.
이렇게 순서가 뒤엉켜있어도 문제가 없는 것은 어차피 아래 그림처럼 포인터를 통해 이전 / 다음 블록의 위치를 찾아가기 때문이다.
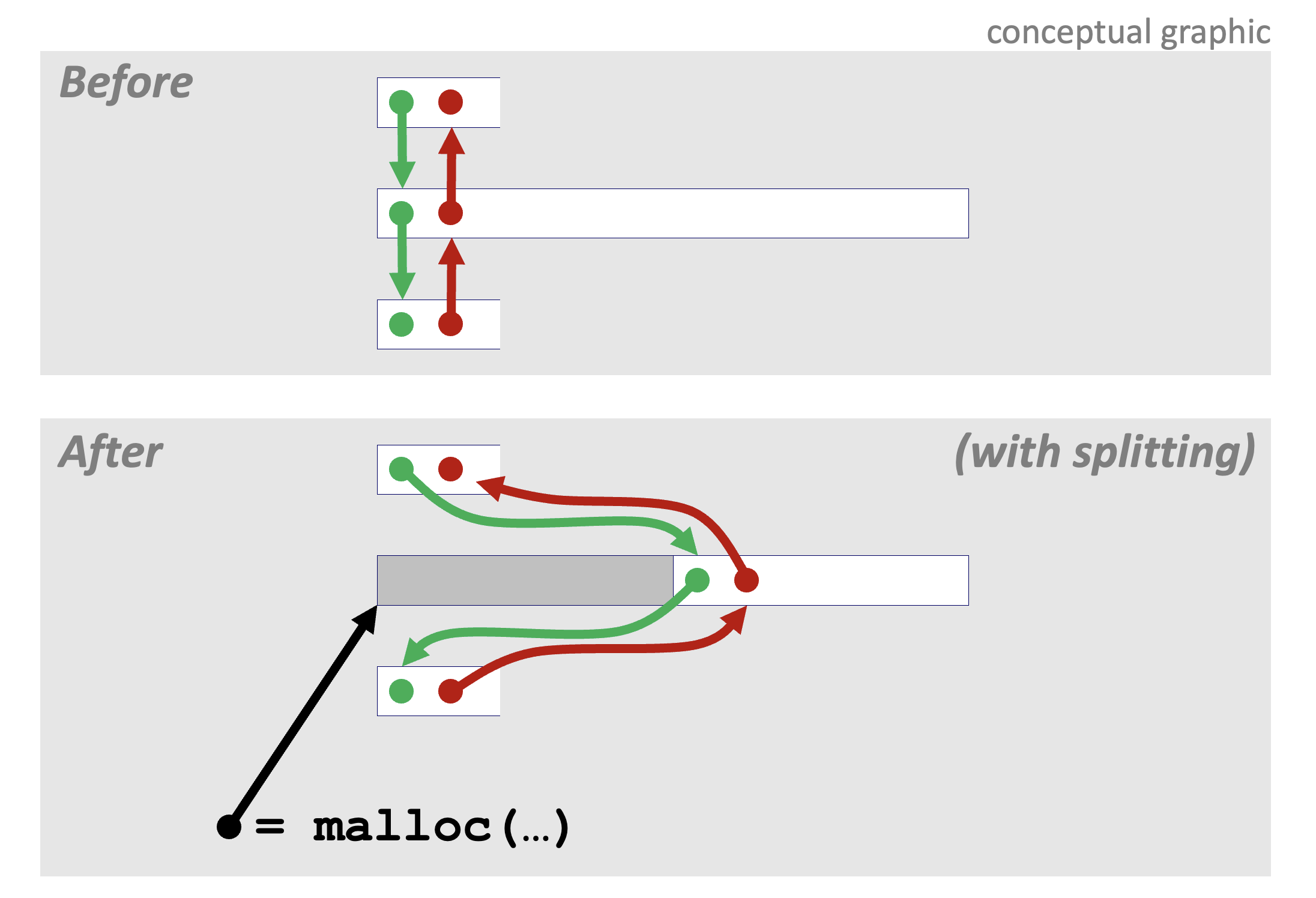
✨ Explicit Free List의 메모리 할당 방식
Explicit Free List에서 메모리 할당은 어떤 방식으로 이루어질까?
아래의 그림에서 초록색 화살표는 다음 블록을 가리키는 포인터이고, 빨간색 화살표는 이전 블록을 가리키는 포인터이다.
만약 malloc 함수를 실행한 결과, 두 번째 블록에서 회색으로 칠한 영역만큼의 메모리 블록이 할당되면, 첫 번째 블록과 세 번째 블록의 포인터는 두 번째 블록에서 남은 가용 영역을 가리키게 된다.
Explicit Free List에서는 이러한 방식으로 가용 블록 간의 연결을 유지한다.
👋 Explicit Free List의 메모리 해제 방식
앞서 Explicit Free List에서 가용 블록이 정렬된 순서는 메모리 주소 순서와 맞지 않을 수 있다고 했다.
그렇다면 메모리를 해제했을 때 그 블록을 Explicit Free List에서 어디에 넣는 것이 좋을까?
해제한 메모리 블록을 Explicit Free List에 삽입하는 방식에는 크게 두 가지가 있다.
1️⃣ LIFO (last-in-first-out, 후입선출) 방식
이 방식은 반환된 블록을 리스트의 시작 부분에 넣는 방식이다.
이 방식의 장점은 단순하고 빠르다는 점이다. 반환된 블록은 리스트의 앞부분에 바로 넣어버리면 되므로 메모리 반환은 상수 시간에 수행된다.
그리고 LIFO 방식과 First fit 방식을 함께 사용하면 할당기는 최근에 반환된 블록들부터 탐색하는데, 이러한 접근방식은 CPU 캐시 효율성을 높일 수 있다.
왜냐하면 최근에 해제된 메모리 블록일수록 아직 CPU의 캐시에 남아있을 가능성이 높기 때문이다.
하지만 Explicit Free List는 메모리 주소와 관계 없이 최근에 반환된 블록부터 탐색하므로 이는 메모리 단편화 문제를 악화시킬 수 있다는 단점이 있다.
2️⃣ 주소순 (Address-ordered) 방식
주소순 방식은 가용 블록들을 메모리 주소 순서에 따라 관리하는 방식이다.
addr(prev) < addr(curr) < addr(next)이 방법의 단점은 적절한 가용 블록을 찾는 데에 선형 시간이 소요된다는 점이다.
하지만 주소순 방식을 사용하면 인접한 가용 블록들을 병합하여 큰 블록을 만드는 것이 용이해지므로, 외부 단편화 문제를 줄일 수 있다는 장점이 있다.
📤 LIFO 방식으로 메모리 해제하기
LIFO 방식으로 Explicit Free List의 메모리를 해제하는 방법을 좀 더 자세히 살펴보자.
1️⃣ Case 1. 반환하는 블록의 앞뒤 블록이 모두 할당된 상태인 경우
아래의 그림에서 가장 오른쪽에 있는 배열은 Explicit Free List의 앞부분을 나타내고, 초록색은 다음 블록, 빨간색은 이전 블록을 가리키는 포인터를 나타낸다.
Explicit Free List에서 가장 앞에 있는 블록은 가리킬 이전 블록이 없으므로 비어있는 빨간색 동그라미로 표현되어 있다.
이 상황에서 노란색으로 표시한 부분을 반환하면 어떻게 될까? 노란색 부분의 앞뒤로는 모두 할당된 블록들이 있는 상태이다.
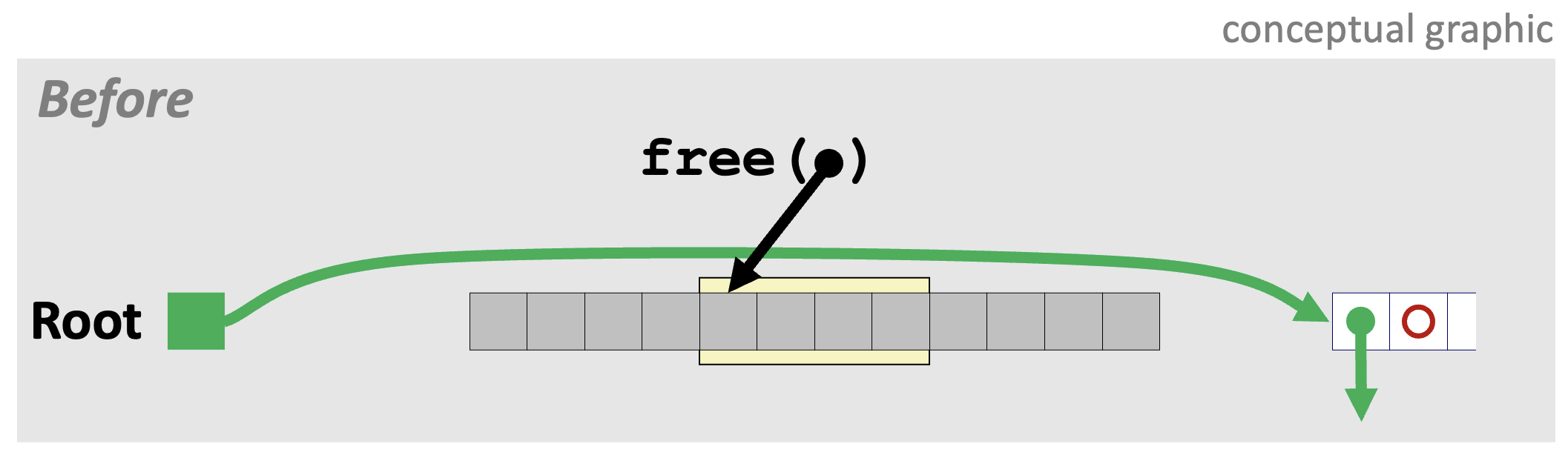
이 경우는 간단하게 아래의 절차를 거치면 반환된 블록의 삽입 절차가 완료된다.
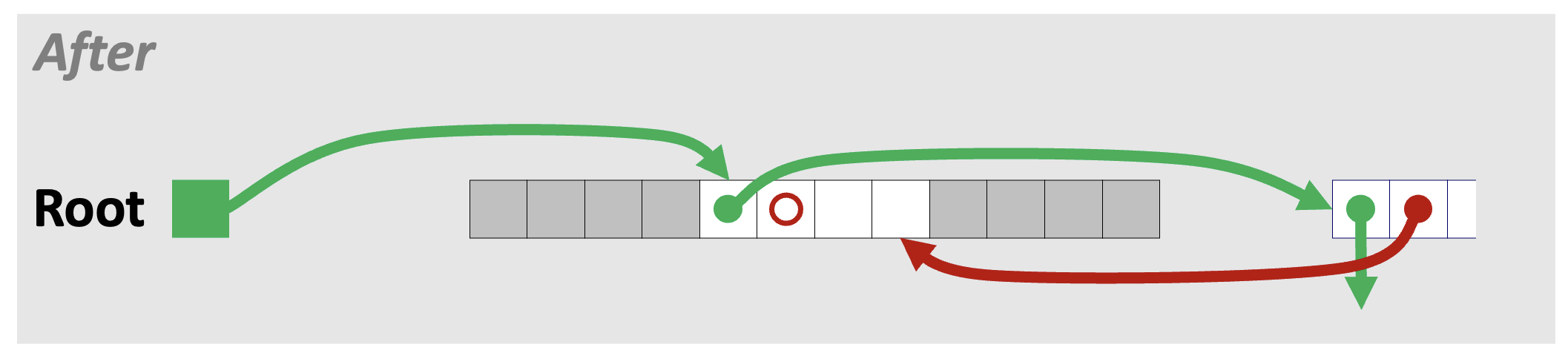
1) Root 노드가 반환된 블록을 다음 블록으로 가리키도록 한다.
2) 반환된 블록이 리스트의 가장 앞에 있던 블록을 다음 블록으로 가리키도록 한다.
3) 리스트 가장 앞에 있던 블록이 반환된 블록을 이전 블록으로 가리키도록 수정한다.
2️⃣ Case 2. 반환하는 블록의 뒷 블록이 가용한 상태인 경우
다음으로는 반환하는 블록의 뒤에 있는 블록이 가용한 상태인 경우를 살펴보자.
이 경우에는 연결(coalescing) 작업을 거쳐야 하므로 Case 1에 비해서는 조금 복잡하다.
반환할 블록의 뒷 블록을 살펴보면 가용 리스트 상의 임의의 블록과 앞뒤로 연결된 상태이다.
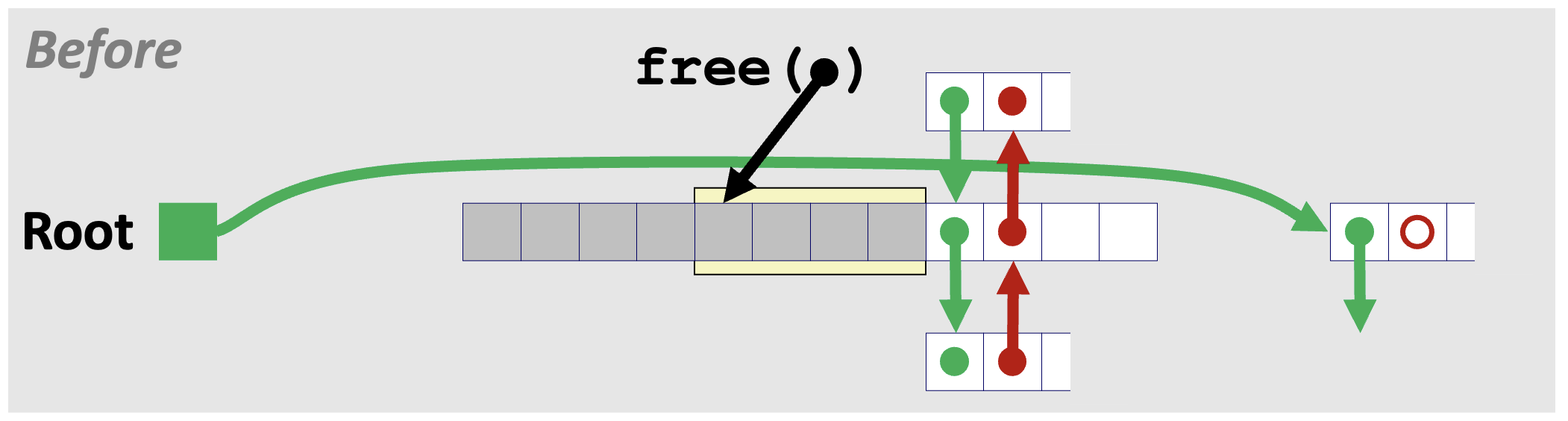
이 상태에서 노란색으로 표시한 부분을 반환하면 뒤의 블록과 연결하고, 리스트의 가장 앞부분에 삽입한다.
그러면 원래 연결되기 전 가용 블록의 앞 블록(Pred.)과 뒷 블록(Succ.)은 어디를 가리켜야 할까?
Pred. 블록과 Succ. 블록의 사이에 있던 블록이 리스트의 가장 앞부분으로 이동해버렸으므로, Pred. 블록과 Succ. 블록은 서로를 앞뒤 블록으로 가리키면 된다.
1) 반환된 블록과 뒤의 가용 블록을 연결한다.
2) Root 노드가 연결된 블록을 다음 블록으로 가리키도록 한다.
3) 리스트 가장 앞에 있던 블록이 연결된 블록을 이전 블록을 가리키도록 수정한다.
4) Pred. 블록이 Succ. 블록을 다음 블록으로 가리키도록 수정한다.
5) Succ. 블록이 Pred. 블록을 이전 블록으로 가리키도록 수정한다.
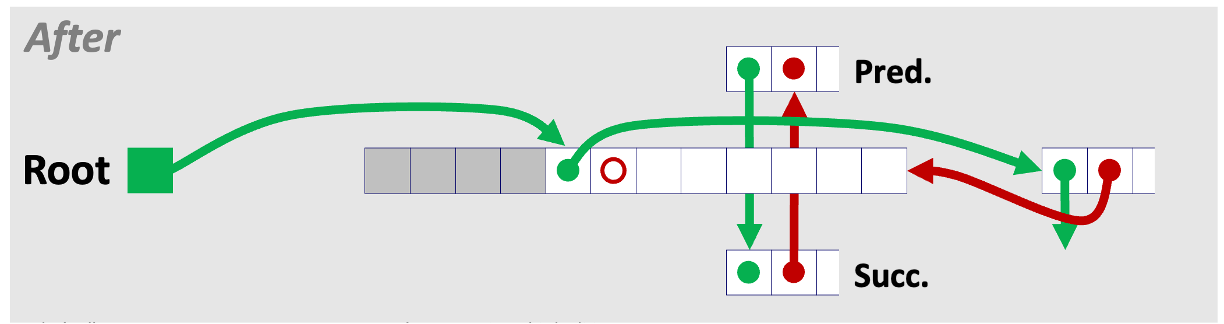
3️⃣ Case 3. 반환하는 블록의 앞 블록이 가용한 상태인 경우
이 경우는 Case 2와 원리가 동일하므로 간단히 그림만 살펴보자.
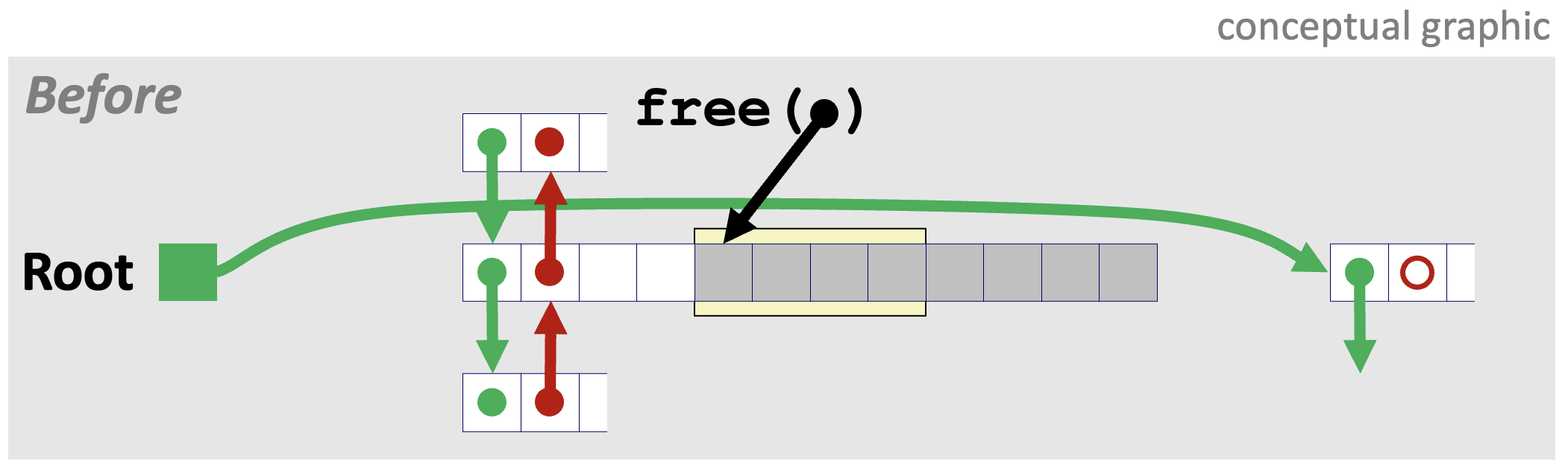
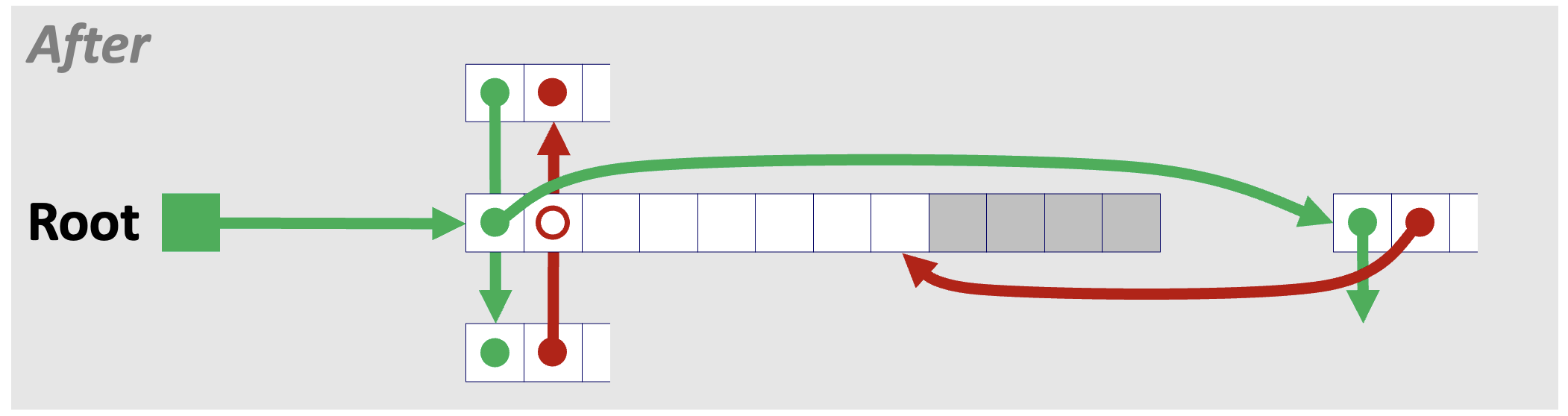
4️⃣ Case 4. 반환하는 블록의 앞뒤 블록이 가용한 상태인 경우
Case 4 또한 Pred. 블록과 Succ. 블록이 앞뒤 블록으로 서로를 가리키게 한다는 점에서 Case 2와 원리가 동일하다.
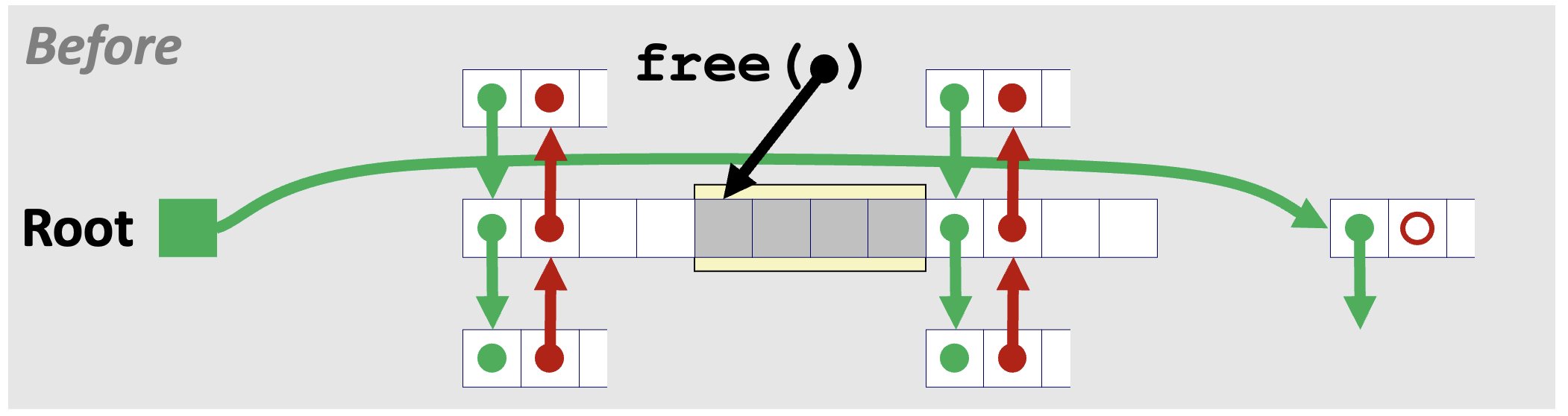
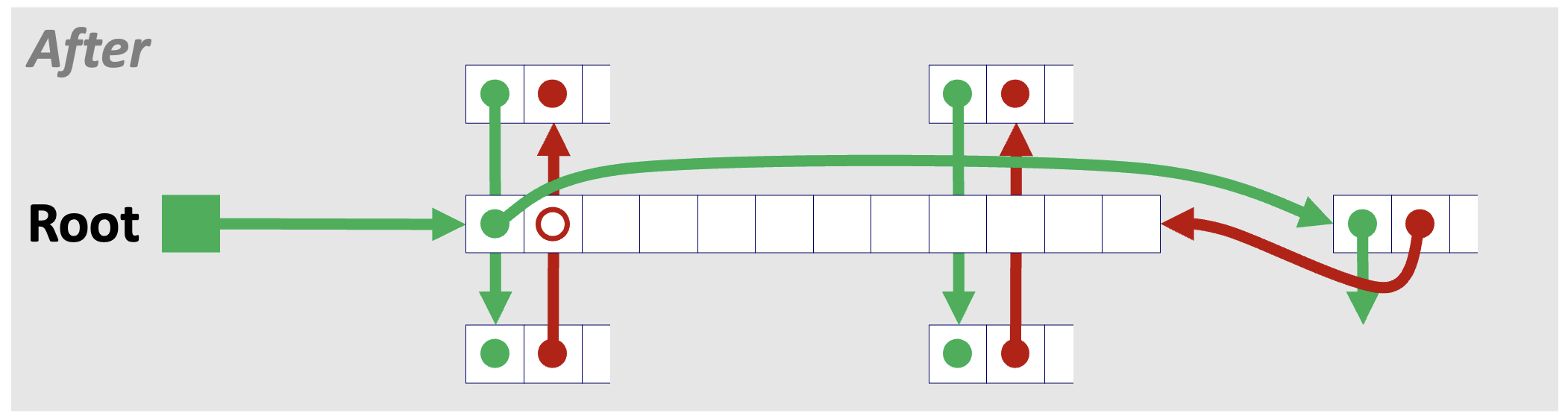
👩🏻💻 C로 Explicit Free List 구현하기 (LIFO 방식)
/*
* 🚀 Explicit Free List (명시적 가용 리스트 / LIFO 방식)
*/
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include <sys/mman.h>
#include <errno.h>
#include "mm.h"
#include "memlib.h"
team_t team = {
/* Team name */
"Jungle Team 7",
/* First member's full name */
"Youngeui Hong",
/* First member's email address */
"my-email@gmail.com",
/* Second member's full name (leave blank if none) */
"",
/* Second member's email address (leave blank if none) */
""};
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
/* size_t 변수가 차지하는 메모리 공간 크기를 8바이트 경계에 맞출 수 있도록 조정 */
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/* Word and header/footer size (bytes) */
#define WSIZE 4
/* Double word size (bytes) */
#define DSIZE 8
/* Extend heap by this amount (bytes) */
#define CHUNKSIZE (1 << 12)
/* Get maximum value */
#define MAX(x, y) ((x) > (y) ? (x) : (y))
/*
* Pack a size and allocated bit into a word
* 블록의 크기와 할당 비트를 통합해서 header와 footer에 저장할 수 있는 값을 리턴
*/
#define PACK(size, alloc) ((size) | (alloc))
/*
* Read a word at address p
* p에 있는 값을 (unsigned int *) 타입으로 변환하여 가져옴
*/
#define GET(p) (*(unsigned int *)(p))
/* Write a word at address p */
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/*
* Read the size field from address p
* 16진수 0x7은 10진수로 7을 의미. 이를 이진수로 변환하면 0111이 되고 NOT 연산자 ~를 붙이면 1000이 됨
* 주소값 p와 and 연산을 하면 비트의 마지막 세 자리를 0으로 바꿈
*/
#define GET_SIZE(p) (GET(p) & ~0x7)
/*
* Read the allocated field from address p
* 마지막 자리를 제외하고 모두 0으로 바꿈
* 할당이 되어 있다면 마지막 자리가 1로 반환되고, 할당이 안 되어 있다면 마지막 자리가 0으로 반환됨
*/
#define GET_ALLOC(p) (GET(p) & 0x1)
/*
* 블록 포인터 bp가 주어지면 블록의 헤더를 가리키는 포인터를 리턴
* 🤔 왜 (char *)로 형 변환을 할까?
* => 포인터 연산을 바이트 단위로 정확하게 하기 위해 1바이트인 char 타입의 포인터로 변환한다.
*/
#define HDRP(bp) ((char *)(bp)-WSIZE)
/* 블록 포인터 bp가 주어지면 블록의 풋터를 가리키는 포인터를 리턴 */
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/*
* 다음 블록의 포인터를 리턴하는 함수
* GET_SIZE(((char *)(bp)-WSIZE))는 현재 블록의 헤더에 있는 사이즈 정보를 읽어옴
*/
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
/*
* 이전 블록의 포인터를 리턴하는 함수
* GET_SIZE((char *)(bp)-DSIZE)는 이전 블록의 footer에 있는 사이즈 정보를 읽어옴
*/
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE((char *)(bp)-DSIZE))
/*************** For Explicit Free List **********************/
#define GET_PRED_FREEP(bp) (*(void **)(bp))
#define GET_SUCC_FREEP(bp) (*(void **)(bp + WSIZE))
/*************************************************************/
/* 힙의 시작 지점을 가리키는 포인터 */
static void *heap_listp;
/* 명시적 가용 리스트의 시작 지점을 가리키는 포인터 */
static void *explicit_listp = NULL;
/* 힙 메모리 영역 확장하기 */
static void *extend_heap(size_t words);
/* 가용 블록 연결하기 */
static void *coalesce(void *bp);
/* 가용한 블록 검색하기 (first-fit) */
static void *find_fit(size_t asize);
/* 할당된 블록 배치하기 */
static void place(void *bp, size_t asize);
/* 명시적 가용 리스트의 맨 앞에 삽입하기 */
static void insert_in_head(void *ptr);
/* 명시적 가용 리스트에 있는 블록 제거하기*/
static void remove_block(void *ptr);
/*
* malloc 패키지 초기화하기
*/
int mm_init(void)
{
// 힙 초기화하기 (시스템 호출이 실패하면 -1을 반환함)
if ((heap_listp = mem_sbrk(6 * WSIZE)) == (void *)-1)
return -1;
PUT(heap_listp, 0); // Alignment padding (힙의 시작주소에 0 할당)
PUT(heap_listp + WSIZE, PACK(4 * WSIZE, 1)); // 프롤로그 헤더 16/1
PUT(heap_listp + 2 * WSIZE, NULL); // 프롤로그 PRED 포인터 NULL로 초기화
PUT(heap_listp + 3 * WSIZE, NULL); // 프롤로그 SUCC 포인터 NULL로 초기화
PUT(heap_listp + 4 * WSIZE, PACK(4 * WSIZE, 1)); // 프롤로그 풋터 16/1
PUT(heap_listp + 5 * WSIZE, PACK(0, 1)); // 에필로그 헤더 0/1
// 에필로그 블록의 주소를 명시적 가용 리스트의 head로 설정
explicit_listp = heap_listp + DSIZE;
// CHUCKSIZE만큼 힙 확장시키기
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) // word가 몇개인지 확인해서 넣으려고(DSIZE로 나눠도 됨)
return -1;
return 0;
}
/*
* mm_malloc - 메모리 할당하기
*/
void *mm_malloc(size_t size)
{
size_t asize; // Adjusted block size
size_t extendsize; // Amount to extend heap if no fit
void *bp; // todo
// 유효하지 않은 요청인 경우 NULL 리턴
if (size == 0)
return NULL;
// overhead 추가와 정렬요건을 충족을 위해 블록사이즈 조정
// overhead란 시스템이 특정 작업을 수행하는 데 필요한 추가적인 리소스나 시간을 가리키는 용어로 여기에서는 헤더와 푸터를 의미
if (size <= DSIZE)
asize = 2 * DSIZE; // 더블 워드 정렬 조건을 충족하기 위해
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE); // size에 가장 가까운 double word size의 배수 찾기
// 가용한 블록 찾기
if ((bp = find_fit(asize)) != NULL)
{
place(bp, asize);
return bp;
}
// 만약 가용한 블록이 없는 경우 힙 메모리 영역을 확장하고 블록을 배치
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}
/*
* mm_free - 메모리 반환하기.
*/
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
// 헤더와 푸터의 할당 비트를 0으로 수정하여 해제
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
/*
* mm_realloc - 메모리 할당 사이즈 변경
*/
void *mm_realloc(void *bp, size_t size)
{
void *old_bp = bp;
void *new_bp = bp;
size_t copy_size;
// size가 0인 경우 메모리 반환만 수행
if (size <= 0)
{
mm_free(bp);
return 0;
}
// 새로운 메모리 블록 할당하기
new_bp = mm_malloc(size);
if (new_bp == NULL)
return NULL;
// 기존 데이터 복사
copy_size = GET(HDRP(old_bp)) - DSIZE;
if (size < copy_size)
copy_size = size;
memcpy(new_bp, old_bp, copy_size);
// 이전 메모리 블록 해제
mm_free(old_bp);
return new_bp;
}
/* 힙 영역 확장하기 */
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
// 더블 워드 정렬을 유지하기 위해 짝수 사이즈의 words를 할당
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL;
// free 상태 블록의 헤더와 푸터를 초기화하고 새로운 에필로그 헤더를 초기화
PUT(HDRP(bp), PACK(size, 0)); // Free block header
PUT(FTRP(bp), PACK(size, 0)); // Free block footer
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // New epilogue header
// 전후로 가용 블록이 있다면 연결
return coalesce(bp);
}
/* 가용 블록 연결하기*/
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 이전 블록의 할당 여부
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 다음 블록의 할당 여부
size_t size = GET_SIZE(HDRP(bp));
// Case 1. 이전 블록, 다음 블록 모두 할당된 상태
if (prev_alloc && next_alloc)
{
insert_in_head(bp); // 연결이 된 블록을 free list 에 추가
return bp;
}
// Case 2. 이전 블록은 할당된 상태, 다음 블록은 가용한 상태
else if (prev_alloc && !next_alloc)
{
remove_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp))); // 현재 블록의 사이즈 + 다음 블록 사이즈
PUT(HDRP(bp), PACK(size, 0)); // 헤더 사이즈 수정
PUT(FTRP(bp), PACK(size, 0)); // 푸터 사이즈 수정
}
// Case 3. 이전 블록은 가용한 상태, 다음 불록은 할당된 상태
else if (!prev_alloc && next_alloc)
{
remove_block(PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
// Case 4. 이전 블록, 다음 블록 모두 가용한 상태
else
{
remove_block(PREV_BLKP(bp));
remove_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
// 명시적 가용 리스트의 맨 앞으로 넣어줌
insert_in_head(bp);
return bp;
}
/* 가용한 블록 찾기 */
static void *find_fit(size_t asize)
{
void *bp;
// 명시적 가용 리스트에서 asize보다 사이즈가 큰 블록을 탐색 (명시적 가용 리스트의 끝, 즉 프롤로그 블록에 이르기 전까지)
for (bp = explicit_listp; GET_ALLOC(HDRP(bp)) != 1; bp = GET_SUCC_FREEP(bp))
{
if (GET_SIZE(HDRP(bp)) >= asize)
{
return bp;
}
}
return NULL; // 가용한 블록이 없는 경우
}
/* 할당된 블록 배치하기 */
static void place(void *bp, size_t asize)
{
// 현재 가용 블록의 사이즈
size_t fsize = GET_SIZE(HDRP(bp));
// 할당된 블록은 명시적 블록 리스트에서 제거
remove_block(bp);
// (현재 가용 사이즈 - 필요한 사이즈) > 최소 블록의 크기(= 2 * DSIZE)라면 asize만큼만 사용하고 나머지는 free 상태로 두기
if ((fsize - asize) >= (2 * DSIZE))
{
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(fsize - asize, 0));
PUT(FTRP(bp), PACK(fsize - asize, 0));
// 명시적 가용 리스트의 맨 앞으로 넣어줌
insert_in_head(bp);
}
else
{
PUT(HDRP(bp), PACK(fsize, 1));
PUT(FTRP(bp), PACK(fsize, 1));
}
}
/* 새로 반환된 가용 블록을 명시적 가용 리스트의 맨 앞에 넣기 (LIFO 방식) */
void insert_in_head(void *bp)
{
GET_SUCC_FREEP(bp) = explicit_listp; // 가장 앞에 있는 블록이므로 NULL 셋팅
GET_PRED_FREEP(bp) = NULL; // 기존에 맨 앞에 있던 블록을 다음 블록으로 셋팅
GET_PRED_FREEP(explicit_listp) = bp; // 기존에 맨 앞에 있던 블록이 현재 블록을 이전 블록으로 가리키도록 수정
explicit_listp = bp; // 명시적 가용 리스트의 시작 지점 변경
}
/* 명시적 가용 리스트에서 가용 볼록 제거하기 */
void remove_block(void *bp)
{
// 만약 첫 번째 블록이라면
if (bp == explicit_listp)
{
GET_PRED_FREEP(GET_SUCC_FREEP(bp)) = NULL;
explicit_listp = GET_SUCC_FREEP(bp);
}
else
{
GET_SUCC_FREEP(GET_PRED_FREEP(bp)) = GET_SUCC_FREEP(bp);
GET_PRED_FREEP(GET_SUCC_FREEP(bp)) = GET_PRED_FREEP(bp);
}
}
