쓰다보니
모든 오답을 하다간
날을 지새겠으므로
트리 순회 외에는 요점만 적겠다.
난이도 하
1197 최소 스패닝 트리
최소 신장 트리 알고리즘 그대로.
전체 그래프에서
가장 작은 간선만 선택하되,
이미 방문한 노드들을 연결하는 거면 선택하지 않음.
끝.
kruscal과 prim 알고리즘이 있는데,
아까 말한건 kruscal이고
prim은 시작 단계,
시작 정점에서,
최소 간선으로 연결된 정점을 선택하여 트리를 확장.
구현은..
나 다 까먹었다..
크루스칼
헤에
가장 낮은 가중치의 간선을 고른다고해도
리스트에서 모든 가중치를 뽑는건 일일텐데
for로 minimum으로 전부 비교해서 하나 뽑았다 쳐도
하나 고르고?
그 노드를 visited 처리해도?
또 for 돌려서 최소 간선 뽑아야할텐데?
아마...
그냥 아예 처음부터 힙으로 넣을걸?
(그러면 최소를 바로바로 뽑을 수 있어서?)
가중치를 리스트 저장시에 제일 앞에 넣고
(아니 근데 대신에 힙정렬 하면
인덱스 자체를 앞의 노드로 설정하는 건 못함. 섞여서.)
(그래서 (가중치, n1, n2)로 해야할 거임.)
리스트를 힙화 하고?
힙pop하고?
뽑은 간선은 완성 리스트에 담아주고?
또 다시 힙pop하는데,
이미 방문한 노드는 방문할 필요 없으니까?
조건문으로 방문한 노드인지 확인을 해서
순차적으로 처리할걸...
..
프림은....
인접 노드에서,
최소 간선을 순차적으로 뽑는거라...
현재 노드에서 연결된 간선 정보 다 꺼내서,
최소 가중치를 뽑은다음,
그 노드가 방문했는지 아닌지 확인하고,
방문 안했으면,
그 노드의 연결된 간선정보까지 다 꺼내서,
다시 최소 가중치를 뽑을 엣지리스트에 넣되,
거기서 꺼내기 전에 엣지리스트를 힙화 한다.
1260 DFS/BFS
dfs..
bfs..
하는법.
DFS
dfs함수.
현재 노드 방문 처리함.
연결 된 노드 꺼냄.
전부 현재 함수 dfs 처리해버림.
스택으로 한다면
현재 노드 방문처리함.
연결된 노드 꺼냄.
전부 스택에 쌓음.
스택이 있는 동안...(while..)
스택 노드 제일 위에서 꺼냄
노드 방문 처리함.
연결된 노드 찾음.
전부 스택에 넣음...
파이썬에서는 꺼낼때 pop만 하면됨^^
BFS
bfs.
현재 노드 방문처리함.
연결 된 노드 꺼냄.
전부 큐에 담아버림.
큐가 있는 동안...
큐에서 popleft로 꺼냄.
노드 방문처리함.
연결된 노드 찾아서 전부 큐에 넣음...
아우 쉬워
저번주 큐 스택 문제가 궁금해지는 시점.
(안풀었음.)
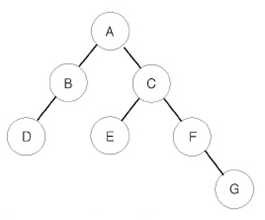
1991 트리순회
이진 트리를 입력받아 전위 순회(preorder traversal), 중위 순회(inorder traversal), 후위 순회(postorder traversal)한 결과를 출력하는 프로그램을 작성하시오.
예를 들어 위와 같은 이진 트리가 입력되면,
전위 순회한 결과 : ABDCEFG // (루트) (왼쪽 자식) (오른쪽 자식)
중위 순회한 결과 : DBAECFG // (왼쪽 자식) (루트) (오른쪽 자식)
후위 순회한 결과 : DBEGFCA // (왼쪽 자식) (오른쪽 자식) (루트)
가 된다.
아우 잘잤다
개념적으로만 나온 전위, 중위, 후위를 실천하고 있다.
처음에는 그냥 리스트로 받다가
어! 이제 보니..
A B C
B D .
F . G
등으로 왼쪽 오른쪽 자식 노드로 구분해서 주는 것이다!
그리고 보통,
(루트) (왼쪽 자식) (오른쪽 자식)
(왼쪽 자식) (루트) (오른쪽 자식)
(왼쪽 자식) (오른쪽 자식) (루트)
이런거! 힌트로 쓰라고 주는 거구나!
라는걸 한번 코드 짜고 나서야 알았다.(유감.)
전위는 dfs를 돌리면 무조건 나와서
일단 dfs로 전위를 해결했다...(돋보이는 야매)
그러나 중위와 후위가 걸리는 것이다...
나는 이문제가..
정말...
...
트리 순회와 이진 검색트리,
최소 스패닝 트리까지 아마 하루가 꼬박,
그것도 문제풀이 첫날에 그만큼 걸려서
솔루션을 신봉하고..
아니 열받고..
답지를 보는 일을 믿고.... 이하생략.
중위 순회.
dfs를 좀만 손보면 되지 않을까?
안 되더라...
이제 왼쪽과 오른쪽이 의미있다는걸 대충 알았다.
그래서 함수를 leftsearch, rootsearch, rightsearch를 세개 만든 후
그 세개를 돌리면... 나오긴 나온다.
(리스트를 만든 후 그걸 순차적으로 출력.)
이때는 이제 후위는 이거 손보면 되겟지?^^ 했는데
안 되었다...
...
def dfs2(graph, start_node, n):
## deque 패키지 불러오기
from collections import deque
visited2 = []
leftlist = []
rightlist = []
rootlist = []
left = tree[start_node][1]
right = tree[start_node][0]
leftlist.append(left)
def leftsearch(leftlist:list, visited2:list, graph):
while leftlist:
node = leftlist.pop()
if node not in visited2 and node != '.':
for key, value in graph.items():
if key == node:
another = value
if value[1] != '.':
leftlist.append(value[1])
visited2.append(node)
return visited2, leftlist
def rootsearch(rootlist:list, visited2:list, graph):
node = visited2.pop()
visited2.append(node)
for key, value in graph.items():
if value[1] == node:
rootlist.append(key)
visited2.append(key)
while rootlist:
parent = rootlist.pop()
for key, value in graph.items():
if value[1] == parent:
rootlist.append(key)
visited2.append(key)
rootlist.append(parent)
return visited2, rootlist
def rightsearch(rightlist:list, leftlist:list, visited2:list, graph):
for key, value in graph.items():
if key == parent:
if value[0] != '.':
rightlist.append(value[0])
while rightlist:
rchild = rightlist.pop()
for key, value in graph.items():
if key == rchild:
if value[1] != '.':
leftlist.append(value[1])
elif value[0] != '.':
visited2.append(rchild)
rightlist.append(value[0])
return visited2, rightlist, leftlist
while leftlist:
leftsearch(leftlist, visited2, graph)
rootsearch(rootlist, visited2, graph)
parent = rootlist.pop()
rightsearch(rightlist, leftlist, visited2, graph)
last = list(graph.keys())[n-1]
last = str(last)
visited2.append(last)
return print(visited2)
dfs2(tree, 'A', n)
last = list(tree.keys())[n-1]
print(last)첫 문제로 이런 길이 나오면 미쳐버리고만다
(답지 코드, 한 네줄됨.)
일단,
자료구조는 왼쪽과 오른쪽 노드를 나눠서 준다.
(나는 전위순회때 원하는대로 출력시키느라 왼 오를 한번 꼬았기때문에 코드에서는 반대로 써야했음. 정말 뒷사람을 생각하지않는 코드^^)
- 첫번째 노드의 왼쪽과 오른쪽을 왼, 오 설정해준다.
...
- leftsearch
왼쪽 리스트가 있는 동안,
만약 그 노드를 방문하지 않았고, 비어있지도 않다면.
그 노드와 연결된 노드를 그래프에서 꺼내서,
왼쪽 자식을 왼쪽 리스트에 담는다.
전부 담고 나면,
방문 체크한다.
def leftsearch(leftlist:list, visited2:list, graph):
#왼쪽 리스트가 있는 동안,
while leftlist:
#현재 노드를 꺼내서,
node = leftlist.pop()
# 그 노드를 방문 안했고, 없는 것도 아니라면.
if node not in visited2 and node != '.':
# 딕셔너리에서 그 노드 항목을 꺼내서
for key, value in graph.items():
if key == node:
another = value
# 왼쪽 자식이 비어있지 않다면 왼쪽 리스트에 넣겠다.
if value[1] != '.':
leftlist.append(value[1])
# 그래서 모든 왼쪽을 타고 가면, 마지막에 방문한 노드를 기억하기 위해 담아놓겠다.
visited2.append(node)
return visited2, leftlist(아마...)
(이때, 노드들을 dict으로 저장했기때문에,
노드와 연결된 노드를 꺼내기 위해서는...
(1,2,3이 아니라 A, B, C라서 그걸로 인덱스 설정이 불가함)
키 값으로 전부 뒤져봐야한다는 점이 좀.
그치만 index로 인덱스 찾아서 그냥 value꺼내도 됐을것.)
그래서 최종으로는 왼쪽 끝에 도달함.
중위에서는 왼쪽으로 시작하기때문에 짜야했던 코드인데,
솔루션에서는 그냥 순차적으로 함수에서 print 시켰지만
나는 리스트 안에 순서를 구현하고 싶어해서 생긴 함수.
확실히 진행 결과를 단순히 print나 그런걸로 하지 않고 리스트 등에 기록하는건
메모리, 시간 초과가 실제 알고리즘보다 나게하기 쉬운 원인인듯.
(지금도 그런거 겪고 있고.)
뭣보다 문자형 노드라서 dict으로 설정하는게 애먹었음.
(내가 쓴 오답 혼자 재밌네)
- rootsearch.
넘겨받은, 최종 왼쪽 노드를 꺼낸다.
그리고 그 왼쪽 노드를 자식으로 가진 노드를 찾아서,
루트 리스트에 넣고,
그 루트도 방문 처리한다.
그리고 루트 리스트가 있는동안,
그 루트 리스트 내의 노드를
자식으로 가진 노드를 루트리스트에 넣고,
방문처리 하고,
...
올라가면서 샤샤샥 방문처리 다 하고 나면,
마지막으로 방문했던 노드를 다음 오른쪽 서치 함수를 위해 넣어둔다.
def rootsearch(rootlist:list, visited2:list, graph):
# 현재 노드를 꺼내서, 방문 처리한다.
node = visited2.pop()
visited2.append(node)
# 그리고, 그래프에서 그 노드를 왼쪽 자식으로 갖는 부모를 찾아,
for key, value in graph.items():
if value[1] == node:
# 루트리스트에 넣고, 방문 처리한다.(순서에 넣음.)
rootlist.append(key)
visited2.append(key)
# 그리고 그 루트 리스트가 살아있는 동안,
while rootlist:
# 매번 노드 하나씩 꺼내서,
parent = rootlist.pop()
# 그 노드를 왼쪽 자식으로 갖고 있는 애를 찾으면서 방문처리 하며 쫒아 올라간다.
for key, value in graph.items():
if value[1] == parent:
rootlist.append(key)
visited2.append(key)
# 그리고 다음 순서를 돌 애를 위해 마지막에 돌았던 노드를 저장해둔다.
rootlist.append(parent)
return visited2, rootlist키와 value로 자식뿐만 아니라 부모도 역추적할 수 있어서
헉...짱!했지만
.items()로 쭉 꺼내는 거 너무 귀찮았고...
그래도 이쯤오면 나 좀 잘한듯??^^? 하는데
이후 울게된다..
- rightsearch에서 끝까지..
def rightsearch(rightlist:list, leftlist:list, visited2:list, graph):
# 만약 이전에 찾은 마지막 노드가 오른쪽 자식이 비어있지 않으면 오른리스트에 넣는다.
for key, value in graph.items():
if key == parent:
if value[0] != '.':
rightlist.append(value[0])
# 오른 리스트가 있는 동안, 하나씩 꺼내서
while rightlist:
rchild = rightlist.pop()
# 그 노드의 연결된 노드의 왼쪽이 비어있으면 왼쪽을 먼저 수색하고,
for key, value in graph.items():
if key == rchild:
if value[1] != '.':
leftlist.append(value[1])
# 이제 오른쪽만 보면 되면 방문 처리하며 내려간다.
elif value[0] != '.':
visited2.append(rchild)
rightlist.append(value[0])
return visited2, rightlist, leftlist
# 최종적으로, 왼쪽 리스트가 있는 동안은 왼쪽 찾기, 루트 찾기, 오른쪽 찾기를 반복한다.
while leftlist:
leftsearch(leftlist, visited2, graph)
rootsearch(rootlist, visited2, graph)
parent = rootlist.pop()
rightsearch(rightlist, leftlist, visited2, graph)
# 그리고 맨 마지막 노드가 안들어가길래 따로 그래프 검색해서 맨 마지막을 호출하여 순서에 넣어줌.
last = list(graph.keys())[n-1]
last = str(last)
visited2.append(last)
return print(visited2)
# 저 해냈어요! 아마도.
dfs2(tree, 'A', n)
last = list(tree.keys())[n-1]
print(last)...
사실...
마지막 구조가...
솔루션이랑...비슷하긴해...
조금...?
후위 순회를 좀만 고치면..
어차피 왼쪽 루트 오른쪽 찾는건 비슷하잖아?
싶어서, 중위 순회를 복붙한뒤
조금씩 수정하려했는데,
visitied 설정이 워낙 중위 맞춤이라 걷잡을 수 없이 꼬이고
나는 억울하기 시작했다..
이렇게 열심히 구현했는데....안되다니.....
솔루션.
import sys
N = int(sys.stdin.readline().strip())
tree = {}
for n in range(N):
root, left, right = sys.stdin.readline().strip().split()
tree[root] = [left, right]
def preorder(root):
if root != '.':
print(root, end='') # root
preorder(tree[root][0]) # left
preorder(tree[root][1]) # right
def inorder(root):
if root != '.':
inorder(tree[root][0]) # left
print(root, end='') # root
inorder(tree[root][1]) # right
def postorder(root):
if root != '.':
postorder(tree[root][0]) # left
postorder(tree[root][1]) # right
print(root, end='') # root
preorder('A')
print()
inorder('A')
print()
postorder('A')
.........
그렇다.
단순히 재귀로 풀어버린 것이다.
나는 아직도 재귀가 어려운데
걔가 먼저 가버렸다
민수님이 해주신 설명이 기억에 남는군
아주 큰 트리도 단순하게
왼쪽자식(트리) - 루트 - 오른쪽 자식(트리)
라고 생각하자.
전위를 예를 들자면,
루트를 먼저 출력한 뒤에,
왼쪽을 출력하고(왼쪽도 뭐 복잡하게 있겠지만)
왼쪽 트리를 다 보고 나면
오른쪽 트리로 넘어가게 된다....
...라는 골자의....
....
그랬다.
재귀와 스택, 나의 원수.....
5639 이진 검색 트리
이걸.....
이거 솔루션보고
아니
하....
씁...
하...
이걸 어떻게 풀어요
전위 순회한 결과를 후위 순회 결과로 출력하는 문제.
그래서
항상 언제나 가장 왼쪽이 루트이기때문에,
아까 앞에서 전위, 중위, 후위 순회처럼
아예 세가지로 나눠버림.
일단 무조건 왼쪽 서브트리는 루트보다 작은값,
오른쪽 서브 트리는 루트보다 큰값이기때문에,
(맨앞루트)(루트보다 작은 왼쪽값 서브트리)(루트보다 큰 오른쪽값 서브트리)
로 맨 앞 루트를 기준값으로
왼쪽, 오른쪽으로 나눠서
리스트를 슬라이스해서
이 여태까지 내용의 함수를 저 리스트를 받아서 돌림.
맨 앞 루트는 순서 리스트 안에 넣음.
즉, 재귀로...
(맨앞)(왼쪽값서브)(오른쪽서브)
...
그래서 프린트 순서를
(함수)
(함수)
print(중간값)
으로 앞서 트리 순회에서 했던 것처럼
루트 왼쪽 다 돌고
오른쪽부터 출력하는.....
...
뭐...
...
그렇다.
내가 시도했던 건
(여기서 애먹었던건, 딕셔너리로 키값을 지정안했을 때.. 추가하려면 쓰는 문법. get을 쓰긴 하는데 아직 잘 못 해서 찾아서 복붙함.)
작은값이 나오다가 큰값이 나오면,
그 값은 여태까지 입력 받은 값보다....
큰값의 바로 전 노드의 자식이 되기때문에
(입력 순서를 노린 꼼수)
그 값을 비교해서,
인덱스를 찾아서, 붙여줬었다.
역순으로 찾아가야하기때문에 그 리스트 역순 호출법이랑,
딕셔너리의 기존 키값의 value를 고치기위해 update...
... 아 이거 예제는 잘? 나오는데
틀렸다고 나와서 때려쳤당 ^^
입력순서말고
문제 조건을 잘 보라는 교훈을..
못 얻은듯(TIL을 그때그때 안해서..)
문제 조건 잘못 이해해서 알고리즘 다시 짠 게 이천년..
2606 바이러스
1번 컴에서 시작했을때
감염당한, 이어진 컴의 갯수를 출력하는 문제.
사실 dfs든? bfs든? 할줄만 안다면?
카운트만 올리면 되기때문에?
그러고보니 솔루션 안 보고 깼군.
첫 문제가 이거였구나.
시험 하 문제 이정도로 부탁드립니다.
(나는 그냥 방문목록 받아서 그거 길이 쟀군.)
11724 연결 요소의 개수
이거 뭐지
그래프가
...
완전히 분리된 그래프의 갯수를 세는 문제.
알고리즘 원리는...
일단 dfs로 전부 돌려서
방문 목록 다 채웠는데
방문하지 않은게 있다?
라면 그 노드를 뽑아서
다시 dfs를 돌려서
그 dfs 횟수를 세면 되는데....
...
완존 렉걸릴거같은데
이거 전체를
for i in visitied:
while i is False:
해도 되나???
아니 근데 while안에서 갱신된게
저기 for에서 갱신 안될거같은데
dfs함수를 만들어서,
시작노드로 한번 돌리고,
false를 찾고,
그걸로 dfs로 다시 넘기는데 카운트를 +1하는데
이걸 어떻게 반복?적으로 하지?
흠 걍 큐에 넣어서
(visited False인 노드를)
dfs 시키는데, dfs 앞 조건문에
방문했는지 아닌지 여부를 넣어서
dfs 다 끝냈는데도 방문 안한 노드들만
추가로 탐색하고나서 count+1 하면..
솔루션은...
큐 안하고 그냥
노드를 다 꺼내서 false가 아니면
dfs시키고 count +1 시키는군..
뭐 비슷했어...
2178 미로 탐색
울고싶다
내가 바로바로
아니 근데 마지막에 몰아하는게
시험 대비도 되고 좋긴한데??
이건...
101..식으로 주는데
1만 지나갈 수 있는 길이고,
시작 지점과 도착 지점이 정해져있으니,
최단 거리를 찾아라! 이다.
이건...
이 10101..자체를 리스트로 저장한다음에
[1,0,1,0,1...]
해당 리스트에서 x만큼, y만큼 거리 차이가 있는 자리를 찾아서 그게 1이면 큐에 넣어서,
큐가 있는 동안,
그 노드를 꺼내서,
방문 처리하고,
연결된 노드를 다 돌되,
자기 자리에는 방문처리용으로 que마다 증가하는 path값을 지정해서 거기에 넣어둔다.
(이렇게 하면 최종 지점에 도착했을때 총 이동한 칸 수가 저장되기때문에, 마지막 값을 최종 지점인덱스로 찾으면 됨.)
나는 맨처음에
모든걸 노드화...
그리고 옆 자리가 1이면 간선을 만들어줌...
간선으로 bfs....
를 하면 이제 간선 수를 만드는 과정마저 계산이 폭발^^ 해서
안된다.......ㅠㅠ힝
좀 특이한건
x와 y좌표 이동을
범위 지정이 이게 좀 까다로운데
(노드와 연결된 x와 y에 해당하는 위치들을 찾는게)
(for로 x만 꺼냈다 y만 꺼냈다 할수가...없으니까)
(for을 두번하면 둘이 같이 이동하므로...)
dx = [ 1, -1, 0, 0]
dy = [0,0, 1,-1]
로 해서 range 4로
x에는 dx더하고, y에는 dy를 돌리는 것이다!
이걸 처음 생각해낸사람은 뿌듯해서
한달간 떠들었을듯.(나라면.)
18352 특정 거리 도시 찾기
이 문제는
시작 도시를 줄테니,
시작 도시에서 최단 거리가 k인 도시들을 찾아라! 이다.
흠...
한 정점에서
모든 정점을 대상으로 하는 거라
다익스트라...
다익스트라가
아마...
현재 시작 노드와,
다른 모든 정점과의 리스트를 만들어서,
하나씩 간선을 연결할때마다,
도착 간선 가중치를 업데이트하는 식이다.
실제 구현은...
distance라는 리스트를 [INF]*n식으로
노드 갯수만큼 만든 다음에
자기 자신은 0으로 갱신.
자기 자신과 이어진 노드는
가중치를 받아서 distance를 갱신.
이 후부터,
자기 자신과 이어진 노드를 큐에 담아가지고
그 노드와 이어진 노드(n2와 n3)를 확인하면서
리스트를 갱신하는데
정석적으로는 min(현재 리스트에 들어있는 값,n1과 n2의 가중치+ n2와 n3의 가중치)
로
n1의 n3을 향한 리스트를 갱신하는데,
뭐 이렇게까지 필요하지않다든가..
하면 적당히 손보기도 하는 모양...
그렇게 전부 갱신한다음에,
k에 해당하는 도시의 번호를...
그 distance의 인덱스를 출력하면 될것이다.
(k라는 최단거리를 가진 distance의 인덱스.)
어차피 이후 거리는 다 도시들이 최단이 아닐거라서
거리가 k에 도달하면 멈추는것도 방법.
나는 처음에 플로이드워셜을 했는데,
사실 시작 지점이 주어지므로 그럴필요가없음..^^;
아!
코드보니,
방문한 노드를 또 방문하지 않도록
visitied 확인해서 연결된 노드 꺼내야함!!
2252 줄 세우기
이 문제는
실제 학생의 키를 주진 않되,
학생의 키의 순서를 줄테니,
올바른 학생 키 순서를 찾아라! 이다.
....
.....
....
이거 줄때
1 > 3
등으로 얘는 얘보다 큼 으로 주기땜시
아예 indegree라는 리스트를 만들어서
해당 번호 인덱스에
진입차수를 입력받을때부터 기록함.
graph[a].append[b]
indegree[b] += 1
뭐 이런...
아니 근데
1이 3보다 크다?
그럼 1이 앞인건데?
1 <- 3이면?
indegree는 1이 받는거 아냐?
근데 indegree가 0인걸 제외하는거라서
흠....
뭐 됐나
아무튼 그런 원리로 전부 받은 다음
indegree내에서 0이 되는 노드를 고름!
큐에 담음!
(큐 짱!)
큐가 있는 동안...
큐에서 꺼냄...
꺼낸 노드와 연결된 노드를 꺼내서
꺼낸 노드는 방문처리(확인처리)하고
방문하지 않은 연결 노드라면
indegree[연결된노드] -= 1로
간선 제거해주는 과정을 거쳐서
순차적으로...
그렇다.
저기서 큐에서 꺼낼때
순서 리스트에 동시에 넣어주면 좋다.
그리고 장난감조립은 위상정렬이랬는데
날 버렸다...
여기서부터 중
문제 선택 순서는?
그것은.....
교육장내 동기들의 핫이슈 문제들.
21606 아침 산책
이건..
실외, 실내인 노드들이 있을 때.
각자의 정점에서 시작해서,
'산책루트'를 성립하는 경로의 수를 모두 찾아라! 이다.
근데 나는
실내 - 실내
실내 - 실외 - 실내
만 경로 취급해서
그냥 노드를 꺼내서
실내인지 실외인지 방문한건지만 확인하고
그게 존재하면 path+=1해서
경우의 수로 더하는 걸 했는데
알고보니..
실내 -실외 - 실외- 실내
같은 경우도 된다고...
...
그래서 200점 만점 3점 받았당 ^^
코어타임 때 언급이 많이 나왔지만
전부 잊어버린 모습...
민수님은...
경로의 거리 수가 정해져있으니
n각형의 대각선 거리가 일정하다는
공식을 쓰셔서 200점 받으셨는데...
...
코드도 아직 덜 봤다..
11725 트리의 부모 찾기
무작위로 연결된 간선을 줄테니,
1을 루트라고 설정해서,
각 모든 노드의 부모를 제시해라! 이다.
나는...
전부 받음.
그리고 1의 자식을 부름.
자식의 부모를 1이라고 함.
그리고 자식의 자식을 부름.
그 자식의 자식의 부모를 자식으로 처리함
(즉, n3의 부모를 n2로 처리함.)
식으로 자식의 자식들을 부를때....
큐에 넣어서...
parent라는 리스트를 만든다음...
그거를 계속 갱신하는 식으로...
솔루션 안보고 풀었다..
그럴만한 문제였군..
그치만 저는 행복했습니다...
참, 방문했는지 아닌지도 fasle로 만들었습니다..
7569 토마토
3차원짜리 토마토가 담긴 상자에서,
익은 토마토는 하루에 주변 토마토를 익힌다고 할때,
그 상자 안 토마토를 전부 익히는데
걸리는 날짜를 제시해라! 이다.
...
하아...
자료 처음 받을때
3차원?
흠...잘 몰겠군
하고 그냥 2차원 배열로 받아서
더 시간이 꼬인 ^^....
사실 원리는 미로 탐색이랑 똑같다.
대신 시작 지점이 아주 많으니까(익은 토마토의 갯수만큼..)
큐에 넣을때 시작지점을 전부 넣는다는점...
날짜를 따로 담을 생각말고 그 자리에 갱신해서 넣은다음
가장 큰값을 해당 그래프에서 max 함수로 뽑으면 된다는점...
안 익는 토마토가 존재하는 경우..
이미 다 익은 경우..를 예외 케이스로 빼면
대신
dx를 1, -1, 0, 0, n, -n으로 하되
그...
틀렸습니다 처리가 떴는데 그 이유가
1, -1을 하는 과정에서
원래는 범위를 정해주기때문에 벗어나지 않지만,
nx로 층수까지 넣어줬기때문에,
같은 층이 아니라 다른 층으로
1, -1로 넘어가더라도 탐지하지 못하는 경우가 있다.
그래서 dx에서 i가 4, 5인 경우는 그대로 하고,
i가 1, 2, 3, 4 일 때는
floor인지 확인하는 조건을 하나 더 넣는다.
floor = x//n
...
if (tomato[nx][ny] == 0 and nx//n == floor):사실 아직 이해 덜 했어
근데 n개의 줄이기때문에
아마...
0번째 층으로 floor를 만들어주고
그 바닥 층에 벗어나면
nx//n == floor가 성립을 안 한다는건데
몫...이 일치 한다는 거거든
아아
nx//n의 몫이 줄의 수를 벗어나면
다음 층이 되어버린다는군...
하지만 역시 .......
잘모르겠어...
2637 장난감 조립
못 풀었다
나의 애증어쩌고
완제품과, 완제품에 쓰이는 중간부품, 기본 부품을.
각 부품의 번호와 필요 갯수만 제시할테니
해당하는 기본 부품의 번호와 갯수를 출력해라! 이다.
나는 1, 2, 3, 4가 기본 부품이라는
전제로 알고리즘을 짜서,
리스트 인덱스도 그걸로 맞춰놨고,
indegree를 제거할때마다
필요갯수를 result list에 넣어서,
기본 부품이 아니라면,
그 인덱스를 다시 장난감 조립 함수에 넣어서,
result list를 갱신해,
기본 부품의 합을 각각 출력하는건데....
이건 기본 부품이 랜덤이라면
중간 부품 인덱스만 골라서 호출, 조건문 하는...
게 불가능하기때문에
다시 짜야한다..^^
그래서
아마 반대로
기본 부품, 즉 어떤 부품도 필요하지 않는 부품부터 제거하면서
n1 - 2 - n2
라면 n2를 큐에 넣어서
n2 - 3 - n3
을 꺼내가지고
저 3을 앞에 있는 가중치에 곱해줘...
3x2....
그리고 곱해주되
그대로 저장하지말고
결과 리스트에 넣어놓는다.(해당하는 부품의...)
{[n1]:[6...]}
다음에 꺼내는 가중치도 꺼내서 기본 가중치에 곱해서 넣어주고..
{[n1]:[6,4...]}
다음에 n3 - 4 - n4도 보겠지?
흠...
4를 꺼내서
앞에 있는 가중치 3을 곱함...
그리고 기본부품 가중치를 곱함...
음, 기본 부품과 이어진 노드만 처리한다면,
그 이후의 노드는 이전 노드와의 가중치만 곱한다음
기존의 기본 부품 가중치와 곱해서 result list에
저장해둔다음
합산해서 뽑으면 되겠군...
적당히 visited 처리도 하고...
outdegree? indegree도 차감해서..
그게 0인것만 돌아가도록...
que에 계속 append해주고...
어라??
아니네??
앞에 여태까지의 가중치를 받아와서
곱해줘야하네...........
...
뭐 퇴근시간이다
퇴근하자!
