scikit-learn 의 model_selection 패키지에 존재하는 train_test_split 모듈을 활용해서 train set / test set 을 손쉽게 분리 할 수 있다.
우리가 답해야 할 질문은 왜 train/test set 을 분리하는가? 이다.
train/test set?
정확히 말하면 train/test 을 train/validation 이라고 말을 할 수 있겠다.
머신러닝 모델에 train 데이터를 100% 학습시킨 이후에 test 데이터에 모델을 적용했을 때 생각보다 성능이 안 나오는 경우가 많다.
이러한 현상을 Overfitting 되었다고 부른다.
이는 모델이 내가 가진 학습 데이터에 너무 과적합하도록 학습한 나머지, 이를 조금이라도 벗어난 케이스에 대해서는 예측율이 현저하게
떨어지는 현상이다. 모든 데이터에 대해서 원하는 결과를 산출해내야 하는 모델에게 이러한 overfitting 은 치명적이기 때문에 이런 현상을 미연에 방지하기 위해서 validation data set 이 존재하는 것이다. validation data set 을 통해서 모델이 과적합 되었는지를 판단해 학습을 종료하는 것 이다.
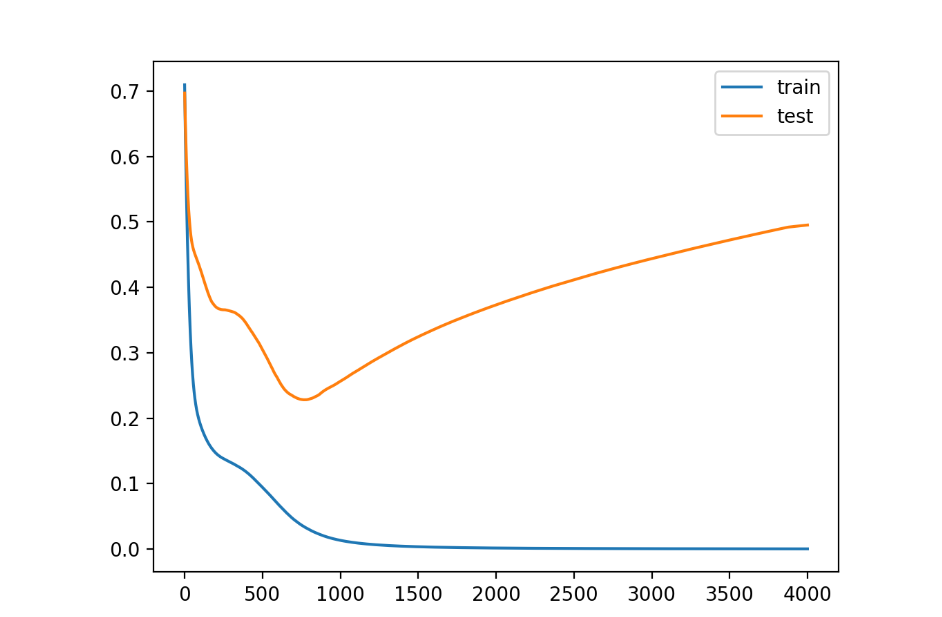
위의 그래프를 보면 train data set 의 오차율은 계속 하강하는 반면 validation data set 의 오차율은 계속 증가하는 것을 볼 수 있다.
train/test 분리
이처럼 overfitting 을 방지하기 위한 test data set 의 중요성에 대해서 알아보았다.
그렇다면, 이를 어떻게 split 할까?
위에서 언급한 sckikit-learn 의 model_selection 패키지를 사용하면 간단하게 해결한다.
Parameters
- arrays
- test_size
테스트 셋 구성의 비율을 나타냅니다. train_size의 옵션과 반대 관계에 있는 옵션 값이며, 주로 test_size를 지정해 줍니다. 0.2는 전체 데이터 셋의 20%를 test (validation) 셋으로 지정하겠다는 의미입니다. default 값은 0.25 입니다. - train_size
- random_state
세트를 섞을 때 해당 int 값을 보고 섞으며, 하이퍼 파라미터를 튜닝시 이 값을 고정해두고 튜닝해야 매번 데이터셋이 변경되는 것을 방지할 수 있습니다. - shuffle
default=True 입니다. split을 해주기 이전에 섞을건지 여부입니다. 보통은 default 값으로 놔둡니다. - stratify
default=None 입니다. classification을 다룰 때 매우 중요한 옵션값입니다. stratify 값을 target으로 지정해주면 각각의 class 비율(ratio)을 train / validation에 유지해 줍니다. (한 쪽에 쏠려서 분배되는 것을 방지합니다) 만약 이 옵션을 지정해 주지 않고 classification 문제를 다룬다면, 성능의 차이가 많이 날 수 있습니다.
Returns
- splitting
[ref]
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
https://teddylee777.github.io/scikit-learn/train-test-split
https://blog.naver.com/PostView.naver?blogId=siniphia&logNo=221396370872
