주제 : Naming, Flat-naming
1. Naming
Name
정의 : Can be resloved to the entity it refers to
엔티티를 지칭하는,
string of bits, 엔티티를 참조할 수 있는 값.
Naming
해당 엔티티를 "찾아가는 과정"
분산시스템에서 ID=8080인 애를 찾아가야한다. 근데 얘가 어떤 컴퓨터에 있는지 어떻게 알어?
그걸 찾아가는 과정이 naming이다.
Access point
- 엔티티를 찾으려면 먼저 얘를 찾아가야함.
- Access point의 name = Address
- ex. 전화기 (사람 => 전화기 => 상대방 전화기(AP) => 사람)
- ex. 서버 app에 접속하려면 먼저 그 컴퓨터를 찾아야 한다.
Address
- entity의 이름을 address로 쓰면 안됨.
- 계속 바뀔 수 있기 때문에 관리 어려움
- ex. ip 달라지면 entity 매번 바뀜. 이러면 안됨.
Names, identifiers, and addresses
진정한 식별자
- 오직 하나의 엔티티를 참조
- 모든 엔티티는 최대 하나의 식별자에 의해 참조
- 재사용되지 않는다.
- 주소가 다른 엔티티로 재할당될 수 있으면, 주소는 식별자로 사용불가
- ex. 전화번호를 다른사람이 가져갈 수 있잖아
Address & Identifier
- 두 유형
- Machine-readable form : 이더넷 주소, 메모리 주소 같이 기계가 읽을수 있는
- Human-friendly names : UNIX 파일 이름, DNS 이름 처럼 사람이 이해하기 좋은
Human-friendly name : 문자열로 표현하는
핵심 : 식별자는 고유해야 하고, 절대 재사용도 안된다.
2. Naming system
특정 이름을 갖는 리소스를 찾는 과정
Access Point를 먼저 찾기
ex. DNS
유형 : flat, strcturred, attributed-based naming
2-1. Flat naming
- flat, unstructured (이름에 의미가 없음)
- 랜덤 비트 스트링
- address 정보가 담겨 있지 않음
How to find
a. Broadcasting
- p2p일 경우 다 뿌려서 물어봐(LAN만 가능)
- 안 쓰는 게 좋음
- ex. ARP ( Link layer에서 사용)
b. Multicasting
- 멀티캐스트가 극단으로 가면 브로드캐스트
- 특정 멀티캐스트 주소를 할당해서, 여기다가 물어보자, 그럼 join한 노드 중에 있다면 응답을 해주겠지
c. Forwarding pointer : 컴퓨터가 바뀔 경우
entity가 A => B로 이동했을 때,
- A에 forwarding pointer 프로세스를 둬서, B에 주소로 전달해줌
- 단점 : 옛날 컴퓨터를 계속 사용해야 됨, 길어질수록 fail 확률 높아짐
d. Home-based approaches
MIPv6의 Home-agent를 통해,
기계가 어디로 이동하던 보고를 해서,
home-agent에 나를 찾는 애들에게 위치를 알려준다.
- 엔티티의 현재 주소를 계속 추적
- 바뀐 주소(care-of-address)를 home-agent에 알려줌
Flat naming : Distributed Hash tables - Chord
- broadcast 안하고 찾을 수 있음
- 리소스의 key 값으로 어떤 노드가 가지고 있는지 알 수 있음 (id>=k 중 가장 작은_
- 동일한 해시함수 사용해 LOOKUP(k) 사용 가능
- LOOKUP(k) 구현 : 링 형태로 오버레이가 구성되어, 내 이웃에게 물어봐서
"어 나 아닌데, 다음으로 전달 전달" 하면서 찾기 => 너무 단순, 비효율
Finger table
노드마다 finger table이 있어, 테이블에 다른 노드 정보가 있음.
예를 들어 31개가 맥시멈인 노드이면,
2^^5 = 32 니까 5비트로 모든 노드를 표현할 수 있다.
그러면 5개 entry가 있는 finger table을 만들고,
key = 1,2,3,4,5
value = succ(p + 2^^i-1)
를 넣는다. p= 나 자신, i= index다.
예를 들어 노드 1이 가지는 테이블은
1 : succ(p+1) => 내 바로 다음 주소
2 :succ(p+2) => 다음 주소
....
이렇게 구성된다.
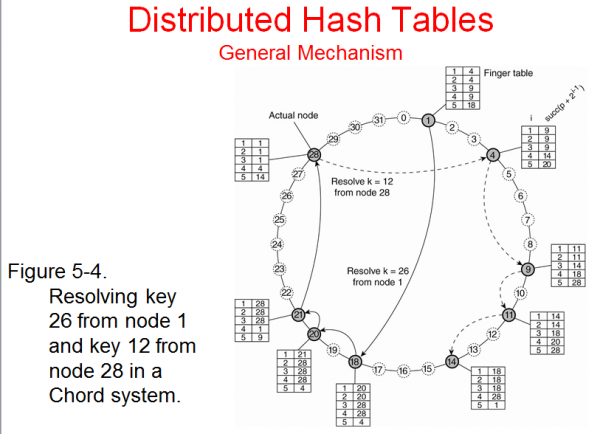
위 그림을 보고, 노드 1이 k=26인 데이터를 찾고 싶은 경우를 생각해보자.
실제로 데이터는 28에 있을 것이다.
1은 테이블을 본다.
1. k=28이니까 4,9 이런데는 없을 것이다. 18의 주소를 안다. 바로 물어본다.
2. 18은 나한텐 없고, 테이블을 본다. 21과 28이 있다. 28에 다이렉트로 물어보긴 위험하다.
내가 모르는 26,27이 있을지도 모르니, 안전빵으로 21에 물어본다.
3. 21은 아는게 28이 최선이다. 28에게 물어본다.
4. 28은 내가 가지고 있다. 1에 대한 주소를 알고 있으니 바로 전달할 수 있다.
단점 : table update (피어가 나갔다가 들어왔다 할테니)
- 주기적으로 내 succ에게, pred가 누구냐고 물어본다. 내가 아닐 수도 있다. 그 사이에 누군가가 사이에 끼어들었을 수도 있으니. 그럼 테이블을 업데이트한다.
- 내 pred에게 잘 살아있는지 확인 => 응답없으면 unknown으로 변경, 누군가 나에게 붙고 싶을때 붙이면 된다.
- k=q+2
(i−1)
은 현재 노드에서 i번째 항목이 가리켜야 할 위치를 계산하는 공식
Flat naming : Hierarchical approaches
네트워크를 작은 단위의 도메인으로 나눠서, 플랫 네이밍을 찾기 쉽게 하는 방법
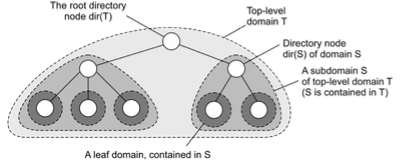
Directory node : 네트워크 내 자기가 관리하는 노드들의 이름 정보 가지고 있음
Roote node : 모든 엔티티의 포인터는 알고 있음
엔티티를 찾고 싶으면 본인 디렉토리 노드에 물어보고, 모르면 계속 올라가면서 찾는다.
Location record
디렉토리 노드에 address가 담겨서 "여기로 가봐" 할 수 있다.
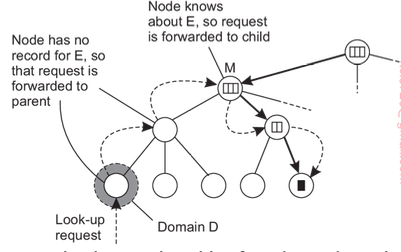
Multiple address
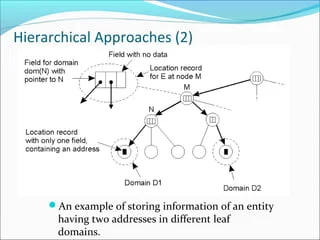
만약 replicate 되어서 한 엔티티가 여러 주소를 가질 수도 있다.
그 땐 그 2개의 주소를 모두 커버하는 디렉토리 노드가, 투 포인터를 가지면 된다.
위 그림에선 M에서 가져야 할 것이다.
LOOKUP (네이밍과정)
특징
- Locality 활용(일단 내 도메인부터 찾기)
- Hierarchy 한 구성을 유지하는 게 중요
Q. 새로운 노드가 들어왔을 때 어떻게 본인을 알리는가
계속 부모로 올리면서 추가.
처음 들어오면 Root까지 추가할 것이다.
