2장. eBPF's "Hello World"
이번 장에서는 eBPF 프로그램 실행에 대해서 구체적으로 이해하기 위해 간단한 “Hello World” 예제를 통해 eBPF의 동작 방식을 살펴보자.
eBPF 애플리케이션을 작성하는 방법은 여러 가지가 있다. 그중에서 이번 장에서는 가장 접근하기 쉬운 방법 중 하나인 BCC Python 프레임워크를 사용한다. 즉, eBPF를 처음 접하는 입문자에게는 빠르게 개념을 익히고 직접 실행해볼 수 있는 좋은 도구다.
다만 BCC는 프로덕션 환경에서 배포용 애플리케이션을 만들기 위한 최적의 선택은 아닐 수 있다. 이 부분에 대해서는 이후 장에서 더 자세히 다룰 예정이다.
BCC로 작성하는 "Hello World"
다음은 BCC Python 라이브러리를 사용해 작성된 eBPF “Hello World” 예제 코드다.
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
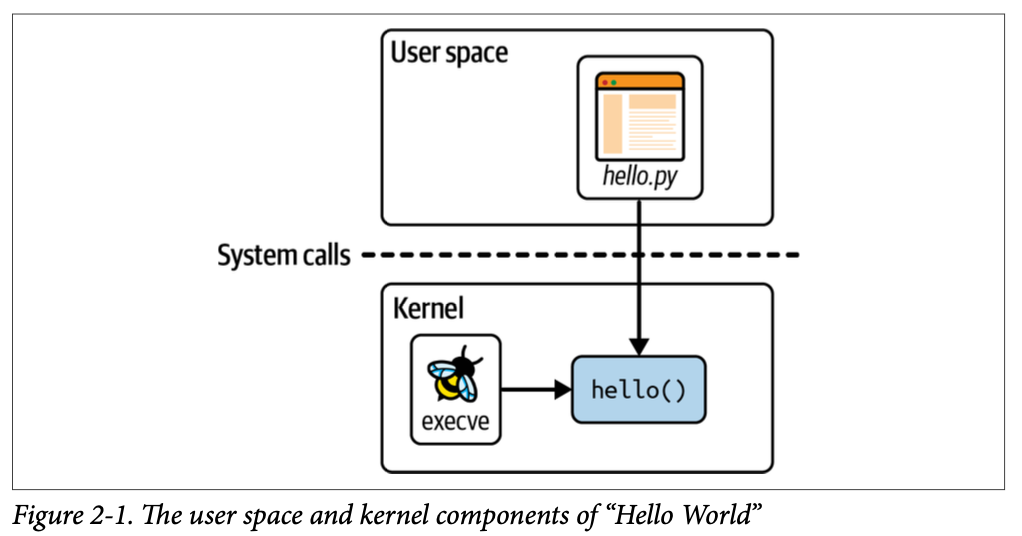
b.trace_print()이 코드는 크게 두 부분으로 구성된다.
- 커널에서 실행되는 eBPF 프로그램
- 사용자 공간(User Space) 코드
• eBPF 프로그램을 커널에 로드한다
• 커널에서 발생한 출력(trace)을 읽어온다
코드 살펴보기
program = """
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""bpf_trace_printk 헬퍼 메서드를 사용해 문자열을 출력하는 역할만 한다.
b = BPF(text=program)문자열로 정의된 프로그램을 컴파일하고 커널에 동적으로 로드한다.
syscall = b.get_syscall_fnname("execve")execve 시스템 콜에 연결한다. execve는 새로운 프로그램을 실행할 때 호출되는 시스템 콜이다.
즉, 이 프로그램은 누군가 프로그램을 실행할 때마다 동작하게 된다. 다만 execve는 표준 이름이지만, 실제 커널 내부 함수 이름은 CPU 아키텍처에 따라 다를 수 있다. 이를 해결하기 위해 BCC는 현재 시스템에서 사용되는 실제 커널 함수 이름을 찾아준다.
b.attach_kprobe(event=syscall, fn_name="hello")이제 kprobe 를 사용하여 시스템콜에 ePBF 프로그램을 연결한다. execve 시스템 콜이 호출되면 커널에서 hello eBPF 프로그램이 실행된다.
kprobe란? 커널 함수가 실행될 때 특정 코드를 끼워 넣을 수 있는 메커니즘 (1장 참고)
b.trace_print()eBPF 프로그램은 이미 커널에 로드되고 이벤트에 연결된 상태이고 이 시점부터 프로그램이 종료될때까지 새로운 프로그램이 실행될 때마다 eBPF 코드가 자동으로 실행된다.
위 프로그램에 대해서 그림으로 요약하면 다음과 같다.
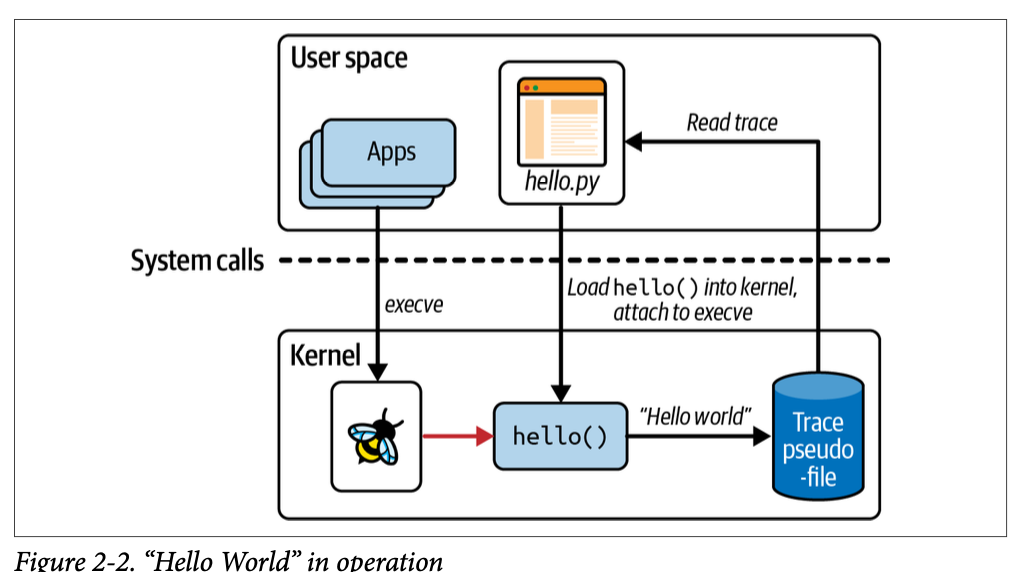
(trace 를 읽고 출력할 때 pseudo file 을 이용한다. pseudo file 에 대해서는 이후 설명)
"Hello World" 실행해보기
이 프로그램을 실행하면, 현재 머신에서 어떤 일이 일어나고 있는지에 따라 바로 trace 로그가 출력될 수도 있다. 이는 이미 실행 중인 다른 프로세스들이 execve 시스템 콜을 호출하고 있기 때문이다.
만약 아무 출력도 보이지 않는다면, 다른 터미널을 열어 아무 명령어나 실행해보면 된다. 그러면 다음과 같은 출력이 나타난다.
$ hello.py
b' bash-5412 [001] .... 90432.904952: 0: bpf_trace_printk: Hello World'BPF 프로그램이 로드되고 이벤트에 연결되는 순간, 이미 실행 중이던 프로세스에서도 바로 동작하기 시작한다. 이것은 다음 두 가지 중요한 특징을 보여준다.
- 시스템 동작을 즉시 변경할 수 있다 (재부팅 필요 X)
- 애플리케이션 수정이 필요 없다 (앱 재시작 필요 X)
출력 결과에는 "Hello World"뿐만 아니라 추가적인 정보도 함께 포함된다.
예를 들어:
bash-5412이 부분은 다음을 의미한다.
- 실행한 프로세스: bash
- 프로세스 ID: 5412
이러한 정보는 커널의 tracing 인프라에서 자동으로 추가되는 컨텍스트 정보다. 또한 이후에는 eBPF 프로그램 내부에서도 이와 같은 컨텍스트 정보를 직접 가져와 활용할 수 있다.
앞서 본 Python 코드에서 trace_print()가 trace psuedo file 로부터 데이터를 읽어온다고 이미지에 보여졌다. eBPF 프로그램에서 사용한 bpf_trace_printk() 함수는 /sys/kernel/debug/tracing/trace_pipe 파일로 데이터를 작성하고, Python 코드는 이 파일을 읽어서 커널에서 발생한 trace 메시지를 가져오는 것이다. 이 파일은 cat 명령어로 직접 확인할 수도 있지만, 접근하려면 root 권한이 필요하다.
이러한 trace_pipe 방식은 한계가 존재한다.
-
출력 형식이 제한적이다
bpf_trace_printk()는 문자열 출력만 지원한다.
따라서 구조화된 데이터(예: 숫자, 구조체 등)를 다루기에는 적합하지 않다. -
출력 형식의 유연성이 부족하다
출력 포맷을 자유롭게 정의하기 어렵기 때문에 복잡한 정보 전달에는 한계가 있다. -
단일 출력 경로만 존재한다
가장 큰 문제는 출력 위치가 하나뿐이라는 점이다.
- 여러 eBPF 프로그램이 동시에 실행되면
- 모든 출력이 동일한 trace_pipe로 모인다
이로 인해 출력이 뒤섞여 사람이 해석하기 어려워질 수 있다.
eBPF 실행 권한
eBPF는 강력한 기능을 제공하기 때문에 root 와 같은 권한이 필요하다.
커널 5.8부터는 CAP_BPF라는 권한이 도입되었지만, 실제로는 다음과 같은 추가 권한이 필요할 수 있다.
- 트레이싱 프로그램: CAP_BPF + CAP_PERFMON
- 네트워크 프로그램: CAP_BPF + CAP_NET_ADMIN
BPF Maps
BPF Map은 eBPF의 핵심 기능 중 하나로, 커널에서 실행되는 eBPF 프로그램과 사용자 공간(user space) 프로그램이 함께 접근할 수 있는 데이터 구조다. 이 기능은 기존 BPF에는 없던 것으로, eBPF를 강력하게 만들어주는 중요한 요소다. 용어는 “eBPF map” 또는 “BPF map” 모두 사용되며, 두 표현은 같은 의미로 쓰인다.
Map의 주요 역할
BPF Map은 다음과 같은 용도로 사용된다.
- 사용자 공간에서 설정 정보를 작성하고 eBPF 프로그램이 이를 읽는 경우
- eBPF 프로그램이 상태(state)를 저장하고, 이후 다시 사용하는 경우
- eBPF 프로그램이 결과나 메트릭을 저장하고, 사용자 공간에서 이를 읽어가는 경우
즉, Map은 데이터 공유와 통신을 위한 핵심 메커니즘이다.
Map의 기본 구조
대부분의 BPF Map은 key–value 형태의 데이터 구조다.
Linux의 uapi/linux/bpf.h 파일에는 다양한 Map 타입이 정의되어 있다.
- 배열과 해시 테이블
- 배열(Array): 항상 4바이트 인덱스를 key로 사용
- 해시 테이블(Hash): 임의의 데이터 타입을 key로 사용 가능
- 특수 목적 Map
특정 연산에 최적화된 Map들도 존재한다.
- FIFO 큐 (Queue)
- LIFO 스택 (Stack)
- LRU(Least Recently Used) 캐시
- Longest Prefix Matching
- Bloom Filter (존재 여부를 빠르게 확인하는 확률적 자료구조)
- 특정 객체를 위한 Map
일부 Map은 특정 커널 객체를 다루기 위해 존재한다.
- sockmap: 소켓 정보 저장
- devmap: 네트워크 디바이스 정보 저장
→ 주로 네트워크 트래픽 리다이렉션에 사용된다
- 기타 등등
- program array map: eBPF 프로그램들을 저장 → 이를 통해 tail call을 구현할 수 있다
- map-of-maps: Map 안에 또 다른 Map을 저장하는 구조도 존재한다
- 일부 Map은 CPU 코어마다 별도의 메모리를 사용하는 per-CPU 방식을 지원 -> 동시성 문제 해결
Hash Table Map 예제
이번 예제에서는 해시 테이블(Hash Table) 형태의 BPF Map을 사용한다. 이 프로그램은 이전과 마찬가지로 execve 시스템 콜의 kprobe에 연결된다.
이 eBPF 프로그램의 목적은 다음과 같다.
• 사용자 ID(uid)를 key로 사용하고
• 해당 사용자가 프로그램을 실행한 횟수를 value로 저장한다
즉, 결과적으로 각 사용자별로 프로그램 실행 횟수를 집계하는 예제다.
BPF_HASH(counter_table);
int hello(void *ctx) {
u64 uid;
u64 counter = 0;
u64 *p;
uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
p = counter_table.lookup(&uid);
if (p != 0) {
counter = *p;
}
counter++;
counter_table.update(&uid, &counter);
return 0;
}주요 동작 흐름
- BPF_HASH(counter_table);
→ 해시 테이블 Map을 정의한다 - bpf_get_current_uid_gid()
→ 현재 프로세스를 실행한 사용자 ID(uid)를 가져온다
→ 반환값은 64비트이며, 하위 32비트만 uid이므로 마스킹한다 - lookup(&uid)
→ 해당 uid가 Map에 있는지 확인하고
→ 있으면 해당 value에 대한 포인터를 반환한다 (기존 값이 있으면 가져오고, 없으면 0으로 시작한다) - counter++
→ 실행 횟수를 증가시킨다 - update(&uid, &counter)
→ Map에 새로운 값을 저장한다
BCC의 특징 (C-like 문법)
p = counter_table.lookup(&uid);
counter_table.update(&uid, &counter);
이 코드는 일반적인 C 문법처럼 보이지 않는다. 실제로는 BCC가 제공하는 확장 문법이며, 내부적으로 정상적인 C 코드로 변환된 뒤 컴파일된다.
즉, BCC는 eBPF 개발을 쉽게 하기 위한 추상화 계층을 제공한다.
위 프로그램을 이제 로드하는 파이썬 코드를 살펴보자
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
while True:
sleep(2)
s = ""
for k, v in b["counter_table"].items():
s += f"ID {k.value}: {v.value}\t"
print(s)앞서 코드와 다른 점은 while 문에서 map 으로부터 데이터를 읽어와 출력하는 부분이다.
- while 문 동작 방식
- 2초마다 반복 실행된다
- counter_table Map을 순회하면서 사용자 ID와 실행 횟수를 출력한다
BCC는 Map을 Python 객체 형태로 자동 생성해주기 때문에 쉽게 접근할 수 있다.
이제 두 개의 터미널(하나는 실행용, 하나는 모니터링용)을 띄워놓고, 이 프로그램을 실행한 뒤 결과를 살펴보면 다음과 같다.
Terminal 1 Terminal 2
$ ./hello-map.py
[blank line(s) until I run something]
ID 501: 1 ls
ID 501: 1
ID 501: 2 ls
ID 501: 3 ID 0: 1 sudo ls
ID 501: 4 ID 0: 1 ls
ID 501: 4 ID 0: 1
ID 501: 5 ID 0: 2 sudo ls- 일반 사용자(uid=501)가 ls 실행 → 카운트 증가
- sudo ls 실행 → sudo 실행은 일반 사용자가 루트 사용자로 실행한 것이므로 501 과 0 아이디 모두 1씩 증가
- 최종적으로 Map에는 다음과 같은 값이 저장된다.
- key=501, value=5
- key=0, value=2
위와 같이 해시 테이블을 이용해서 key–value 형태의 상태로 저장할 수 있다. 그러나 이런 방법을 하려면사용자 공간에서 주기적으로 Map을 polling해야 한다는 단점이 있다.
Perf Buffer와 Ring Buffer Map
이번에는 기존 “Hello World”보다 조금 더 발전된 방식으로, Perf Buffer(Map)를 사용해 데이터를 사용자 공간으로 전달하는 방법을 살펴본다. 참고로 최근에는 BPF ring buffer가 더 권장되는 방식이며, 커널 5.8 이상에서는 이를 사용하는 것이 일반적이다.
Ring Buffer란 무엇인가
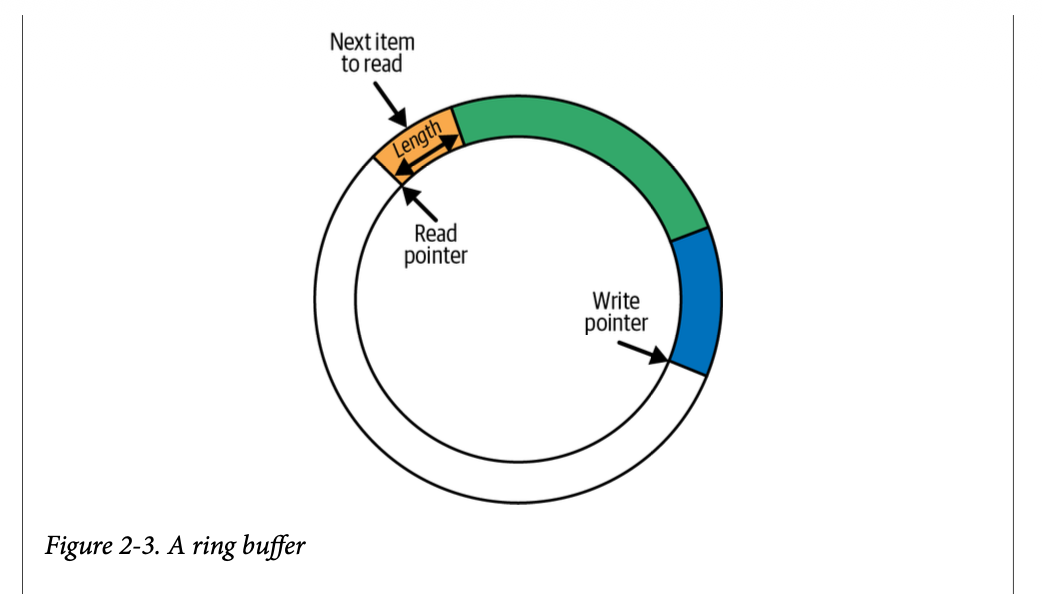
Ring Buffer는 eBPF만의 개념은 아니며, 데이터를 순환 구조로 저장하는 메모리 구조다.
- write 포인터: 데이터를 쓰는 위치
- read 포인터: 데이터를 읽는 위치
데이터는 write 포인터 위치에 기록되고, 길이 정보와 함께 저장된다. 이후 read 포인터가 이를 읽어간다.
동작 특징은 다음과 같다.
- read 포인터가 write 포인터를 따라잡으면 → 읽을 데이터 없음
- write 포인터가 read 포인터를 덮어쓰려 하면 → 데이터는 버려지고 drop 카운터 증가
즉, 데이터 흐름을 효율적으로 처리하기 위한 구조다.
eBPF 프로그램(Perf Buffer 사용)
BPF_PERF_OUTPUT(output);
struct data_t {
int pid;
int uid;
char command[16];
char message[12];
};
int hello(void *ctx) {
struct data_t data = {};
char message[12] = "Hello World";
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(&data.command, sizeof(data.command));
bpf_probe_read_kernel(&data.message, sizeof(data.message), message);
output.perf_submit(ctx, &data, sizeof(data));
return 0;
}- BPF_PERF_OUTPUT(output)
→ 사용자 공간으로 데이터를 전달하기 위한 Map 생성 - struct data_t
→ 전달할 데이터 구조 정의 (pid, uid, command, message) - helper 함수들
- bpf_get_current_pid_tgid() → 프로세스 ID
- bpf_get_current_uid_gid() → 사용자 ID
- bpf_get_current_comm() → 실행 중인 명령어 이름
- bpf_probe_read_kernel() → 문자열 데이터를 구조체에 복사
- output.perf_submit()
→ 데이터를 ring buffer로 전달
즉, 프로세스 ID 와 사용자 ID, 실행한 커맨드, 메시지를 링 버퍼에 전달한다.
이후 아래 파이썬코드를 통해 데이터를 수신한다.
def print_event(cpu, data, size):
data = b["output"].event(data)
print(f"{data.pid} {data.uid} {data.command.decode()} {data.message.decode()}")
b["output"].open_perf_buffer(print_event)
while True:
b.perf_buffer_poll()- print_event()
→ 데이터를 출력하는 함수 - open_perf_buffer()
→ ring buffer를 열고 콜백 함수 등록 - perf_buffer_poll()
→ 계속 buffer를 확인하며 데이터가 있으면 콜백 실행
이제 위 프로그램을 실행하면 다음과 같이 출력이 찍힌다.
$ sudo ./hello-buffer.py
11654 node Hello World
11655 sh Hello World
...
기존 trace_pipe 방식은 모든 프로그램이 하나의 trace_pipe 공유하여 사용하지만, eBPF 프로그램이 자체 ring buffer 를 사용하여 데이터 충돌 없이 독립적으로 처리 가능하다.
그리고 해시 테이블 기반에서는 while 문으로 루프를 돌며 polling 하였지만 ring buffer 에서는 콜백 함수를 등록하여 수신 될때마다 실행되도록 개선이 되었다.
또한 단순 문자열이 아니라 구조체 형태의 데이터 전달이 가능하며, eBPF 프로그램은 이벤트 발생 시 프로세스 ID, 실행된 명령어 등 컨텍스트 정보와 함께 넘겨 관측(observability)에 매우 유용하다.
perf-buffer 와 ring buffer 비교
항목 perf buffer ring buffer 구조 per-CPU (CPU 별로 데이터를 가지기 때문에 이후 통합 필요) single buffer 데이터 통합 필요 불필요 메모리 많이 사용 효율적 사용 권장 과거 현재 (권장)
함수 호출(Function Calls)
지금까지 eBPF 프로그램이 커널이 제공하는 helper 함수를 호출할 수 있다는 것을 보았다. 그렇다면 일반적인 프로그래밍처럼 직접 만든 함수를 나누어 사용할 수는 없을까라는 의문이 생긴다.
일반적으로 소프트웨어 개발에서는 중복되는 코드를 함수로 분리해서 재사용하는 것이 좋은 방식이다. 하지만 초기 eBPF에서는 helper 함수 외에는 함수 호출이 허용되지 않았다.
초기 eBPF의 제한과 inline 함수
이 제한을 우회하기 위해 개발자들은 다음과 같은 방식을 사용했다.
static __always_inline void my_function(void *ctx, int val)여기서 __always_inline은 컴파일러에게 해당 함수를 반드시 inline 하도록 지시하는 키워드다.
일반적인 함수 호출은 다음과 같은 방식으로 동작한다. (아래 이미지의 왼쪽)
- 함수 호출 시 → 점프(jump) 명령어로 함수 위치로 이동
- 함수 실행 후 → 다시 원래 위치로 돌아옴
하지만 inline 함수는 다르게 동작한다. (아래 이미지의 오른쪽)
- 함수 호출 대신 → 함수 내용이 그대로 복사되어 삽입됨
- 즉, 점프 없이 코드가 펼쳐진 형태로 실행됨
이런 방식으로 인해 함수가 여러 번 사용되면 코드가 중복 생성된다.
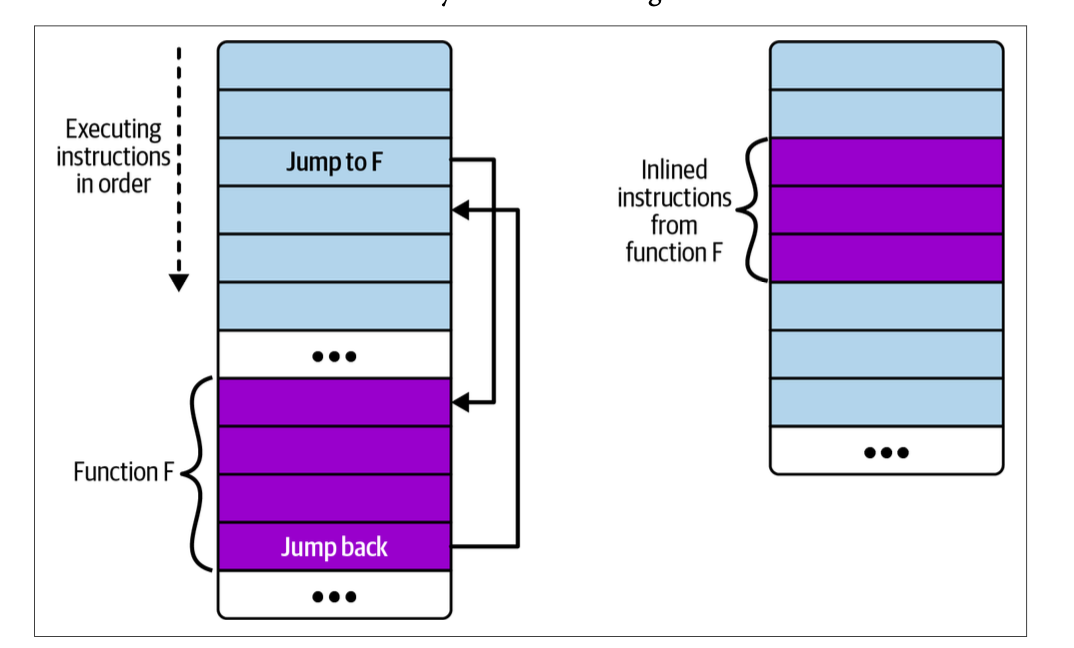
eBPF에서 함수 호출 지원
이후 발전을 통해 Linux 커널 4.16 + LLVM 6.0부터는 일반 함수 호출이 가능해졌다.
이 기능은 다음과 같이 불린다.
• BPF to BPF function calls
• 또는 BPF subprograms
즉, 이제는 inline 없이도 보다 자연스럽게 함수 구조를 사용할 수 있게 되었다. 그러나 BCC 에서는 이를 지원하지 않는다. 따라서 BCC 에서는 inline 함수 방식으로 작성해야 한다.
하지만 복잡한 로직을 나누는 또 다른 방법으로는 tail call이라는 메커니즘이 존재한다.
Tail Call
하나의 eBPF 프로그램이 다른 eBPF 프로그램을 호출하면서 실행 흐름을 완전히 넘기는 방식이다. 이때 중요한 특징은 호출이 끝나도 원래 프로그램으로 돌아오지 않는다는 점이다.
Tail call 을 사용하면 스택 사용을 줄일 수 있다. 보통 함수 호출이 반복되면 스택 프레임이 계속 쌓이게 되는데, 이는 스택 오버플로우를 유발할 수 있다. 특히 eBPF는 스택 크기가 512바이트로 매우 제한적이기 때문에 이런 문제가 더 중요하다.
Tail call 은 아래 헬퍼메서드를 통해 실행할 수 있다.
long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index)- ctx
→ 현재 실행 컨텍스트 전달 - prog_array_map
→ eBPF 프로그램들이 저장된 Map (BPF_MAP_TYPE_PROG_ARRAY) - index
→ 호출할 프로그램의 위치
- Map에서 index에 해당하는 프로그램을 찾는다
- 존재하면 해당 프로그램으로 실행을 넘긴다. 이 경우 현재 프로그램은 종료되고 돌아오지 않는다
만약 실패하면(ex: 지정된 프로그램이 맵에 존재하지 않는 경우), 이 경우 호출한 프로그램은 계속 실행한다.
BCC 에서는 prog_array_map.call(ctx, index) 와 같이 작성할 수 있다.
BPF_PROG_ARRAY(syscall, 300);
int hello(struct bpf_raw_tracepoint_args *ctx) {
int opcode = ctx->args[1];
syscall.call(ctx, opcode);
bpf_trace_printk("Another syscall: %d", opcode);
return 0;
}
int hello_execve(void *ctx) {
bpf_trace_printk("Executing a program");
return 0;
}
int hello_timer(struct bpf_raw_tracepoint_args *ctx) {
if (ctx->args[1] == 222) {
bpf_trace_printk("Creating a timer");
} else if (ctx->args[1] == 226) {
bpf_trace_printk("Deleting a timer");
} else {
bpf_trace_printk("Some other timer operation");
}
return 0;
}
int ignore_opcode(void *ctx) {
return 0;
}-
BCC에서는 BPF_PROG_ARRAY 매크로를 사용해서 eBPF 프로그램들을 담는 Map(BPF_MAP_TYPE_PROG_ARRAY)을 쉽게 만들 수 있다. 여기서는 이 Map의 이름을 syscall로 만들고, 최대 300개의 프로그램을 저장할 수 있게 설정했다.
-
hello 함수
syscall 번호(opcode) 가져와서 해당 opcode에 맞는 프로그램 실행한다. (tail call)
만약 실행할 함수가 없다면bpf_trace_printk("Another syscall: %d", opcode);가 실행된다. -
hello_execve() → execve 전용
프로그램 실행(execve) 발생 시 출력한다. -
hello_timer()
timer 관련 처리를 담당한다. opcode 값에 따라 다르게 출력한다.
- 222 → timer 생성
- 226 → timer 삭제
- 나머지 → 기타 timer 작업
- ignore_opcode()
특정 syscall 무시하도록 작성한 함수이다.
[syscall 발생]
↓
hello()
↓
opcode 확인
↓
syscall map lookup
↓
┌───────────────┬───────────────┐
│ 있음 │ 없음 │
↓ ↓
해당 함수 실행 "Another syscall" 출력이제 데이터를 수신하는 사용자 코드를 살펴보자.
b = BPF(text=program)
b.attach_raw_tracepoint(tp="sys_enter", fn_name="hello")
ignore_fn = b.load_func("ignore_opcode", BPF.RAW_TRACEPOINT)
exec_fn = b.load_func("hello_exec", BPF.RAW_TRACEPOINT)
timer_fn = b.load_func("hello_timer", BPF.RAW_TRACEPOINT)
prog_array = b.get_table("syscall")
prog_array[ct.c_int(59)] = ct.c_int(exec_fn.fd)
prog_array[ct.c_int(222)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(223)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(224)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(225)] = ct.c_int(timer_fn.fd)
prog_array[ct.c_int(226)] = ct.c_int(timer_fn.fd)
# Ignore some syscalls that come up a lot
prog_array[ct.c_int(21)] = ct.c_int(ignore_fn.fd)
prog_array[ct.c_int(22)] = ct.c_int(ignore_fn.fd)
prog_array[ct.c_int(25)] = ct.c_int(ignore_fn.fd)
...
b.trace_print()BPF(text=program)을 통해 컴파일 및 로드를 한다- 앞서 예제들과 다르게 kprobe 에 연결하지 않고,
b.attach_raw_tracepoint(tp="sys_enter", fn_name="hello")를 통해 hello 함수를sys_entertracepoint 에 연결한다. - 이외 exec, timer, ignore 함수도 로드한다.
- C 코드에서 만든 BPF_PROG_ARRAY를 가져온다. (c 에서
BPF_PROG_ARRAY(syscall, 300);이 부분) - 프로그램 배열에 각 함수들을 넣어준다.
- 이제 커널에서 발생한 trace 들을 출력한다.
위 프로그램을 실행하면 아래와 같이 출력된다.
./hello-tail.py
b' hello-tail.py-2767 ... Another syscall: 62'
b' hello-tail.py-2767 ... Another syscall: 62'
...
b' bash-2626 ... Executing a program'
b' bash-2626 ... Another syscall: 220'
...
b' <...>-2774 ... Creating a timer'
b' <...>-2774 ... Another syscall: 48'
b' <...>-2774 ... Deleting a timer'
...
b' ls-2774 ... Another syscall: 61'
b' ls-2774 ... Another syscall: 61'- Executing a program
→ execve syscall 발생 (프로그램 실행됨) - Creating a timer / Deleting a timer
→ timer 관련 syscall 발생 - Another syscall
→ 호출 프로그램 맵에 항목이 없는 opcode
위와 같이 tail call 등을 통해서 지금의 eBPF는 여러 프로그램을 연결해 커널 안에서 매우 복잡한 로직까지 구현할 수 있는 수준이다
