배경
서버를 운영하면서 쿼리 최적화는 백엔드 개발자의 필수 능력이다. 레일즈와 장고와 같은 프레임워크에서는 lazy loading 을 하기 때문에 N+1 query 가 발생할 수 있고, 한 SELECT statement 에서 너무 많은 records 를 갖고 올 경우 성능 저하를 불러일으킬 수 있으며, 인덱스가 잘못 설정되어 있을 경우 CUD 시 오버헤드 발생 및 너무 많은 records 를 갖고오며 이것 또한 성능 저하를 불러일으킬 수 있다 (인덱스에 대해서는 나중에 자세히 다루자)
내가 운영하는 서버에서 어떤 쿼리가 오고가는지, 그리고 쿼리마다 average duration 는 어떻게 되는지 궁금하다
수작업
쿼리마다 파싱하여 normalized 한 뒤 fingerprint 를 만들고 이에 대응하는 쿼리마다 시간과 비용을 sum & divide by count 를 하면 평균 소요 시간 및 쿼리 호출 수 등을 구할 수 있을 것이다. 그러나 내가 만든 코드가 과연 괜찮을까? 내가 만든 코드가 괜히 과한 오버헤드를 일으켜 성능저하를 일으키지 않을까 걱정된다. 확실하게 여러 사람들이 이용하는 오픈소스가 있으면 좋겠다.
pg stat statement
postgresql 에서 제공하는 pg stat statement 를 사용하면 쿼리마다 소요시간 및 쿼리 카운팅도 충분히 할 수 있다. 그리고 pg_stat_statement 에서는 알아서 쿼리를 normalized 한 뒤 queryId 를 추출해준다. pg stat statement 를 활성화하기 위해서는 postgresql.conf 에 shared_preload_libraries 에 pg_stat_statements 를 추가하고 DB 를 재시작해야된다.
AWS RDS 에서도 11 버전 이후의 postgresql 에서 pg_stat_statements 라이브러리가 기본값으로 로드되며(이전 버전에는 수동으로 로드해야됌) 이를 이용한 통계기능을 제공하고 있다.
또한 파이썬의 powa 라이브러리는 pg_stat_statement 기능을 이용하여 다음과 같이 GUI 를 제공해주고 있다.
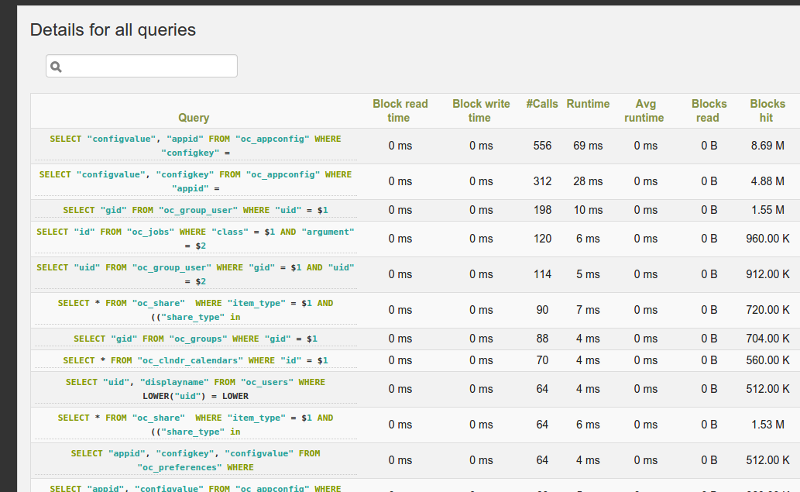
ref: https://powa.readthedocs.io/en/latest/components/stats_extensions/pg_stat_statements.html
postgresql 의 pg_stat_statement 기능을 활용하여 서버 내 어느 쿼리메서드가 소요시간이 오래 걸리는지 파악하여 인덱스가 필요한 테이블에는 인덱싱을 추가해주고, 쓰기가 오래걸리는 경우 인덱스가 잘못 걸려있는게 아닌지 파악할 수 있을 거 같다.
QueryId 괜찮은가?
QueryId 가 쿼리를 normalized 하여 해시값을 추출한다고 하지만 실제로 완전 normalized 는 하지 않는 거 같다. 이에 관한 예시로 SELECT 문에서 IN 조건을 넣을 때 다음과 같은 이슈가 있었다.
SELECT name FROM users IN ('user1','user2','user3')
-> 이건 1q2w3e4r 해시값이 나온다면
SELECT name FROM users IN ('user1','user3')
-> 이건 5t6y7u8i 해시값이 나옴IN 조건에 들어가는 요소 개수에 따라 normalized 쿼리 해시값이 달라지는 경우가 있다는 것이다. 어느 경우엔 조건절에 특정 속성값에 인덱싱이 되어 있을 수 있어 이렇게 다른 값이 도출될 수 있으나, 우리의 경우 본질이 같은 쿼리들은 하나로 묶어 한 눈에 파악을 용이하게 할 필요가 있었다. ruby 에는 pg_query 라는 gem 있는데 해당 gem 에서 제공하는 메서드를 통해 쉽게 normalized 쿼리를 추출할 수 있었다.
parsed_query = PgQuery.parse("SELECT * FROM users")
# Normalizing a query (like pg_stat_statements in Postgres 10+)
PgQuery.normalize("SELECT 1 FROM x WHERE y = 'foo'")
=> "SELECT $1 FROM x WHERE y = $2"
PgQuery.parse("SELECT 1").fingerprint
=> "50fde20626009aba" # 똑같다
PgQuery.parse("SELECT 2; --- comment").fingerprint
=> "50fde20626009aba" # 똑같다
# Faster fingerprint method that is implemented inside the native C library
PgQuery.fingerprint("SELECT $1")
=> "50fde20626009aba" # 똑같다native C 라이브러리로 만들었기에 빠르게 fingerprint 생성이 가능하고 이를 통해 중복된(본질은 같으나 다르게 normalized 되는) 쿼리들을 하나로 묶을 수 있었다.
reference
https://www.postgresql.org/docs/current/pgstatstatements.html
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_PerfInsights.UsingDashboard.AnalyzeDBLoad.AdditionalMetrics.PostgreSQL.html
https://powa.readthedocs.io/en/latest/components/stats_extensions/pg_stat_statements.html
https://github.com/pganalyze/pg_query
