1.1 관측 가능성의 세 가지 요소
1.1.1 모니터링과 차이점
black box
- 인풋과 아웃풋만 보여지고 실제 내부에 대해서는 알지 못하는 것
white box
- 내부 로직까지 확인하는 것
모니터링과의 차이점
- 모니터링
- 블랙박스 모니터링을 기본으로 핵심적인 어플리케이션과 시스템 메트릭에 집중한다
- 관측 가능성
- 내부의 상태를 디버깅할 수 있는 정보까지 고려하여 장애가 발생할 경우 신속하게 대응하고 계측을 추가하여 향후 비용 절감 및 장애 가능성을 고려한다
- 메트릭, 로그, 추적 세가지 요소에 집중한다.
1.1.2 관측 가능성 구성 요소
메트릭
- 일정 시간동안 측정된 데이터를 집계하고 수치화
로그
- 어플리케이션 실행 시 생성되는 텍스트
추적
- 서비스가 실행되면서 트랜잭션을 처리하는 과정에서 발생하는 세부적인 정보
1.2 메트릭
- 일정 시간동안 측정된 데이터를 집계하고 수치화
- SLI는 SLO의 임계기준을 달성해야한다 (ex: 응답시간 0.5s 미만 등)
- 에러의 기준을 명확히 한다 (ex: 에러코드 통일)
- 리소스 사용률 및 포화상태를 측정한다
- 프로메테우스의 exemplar를 이용하여 메트릭과 추적을 동시에 확인할 수 있다
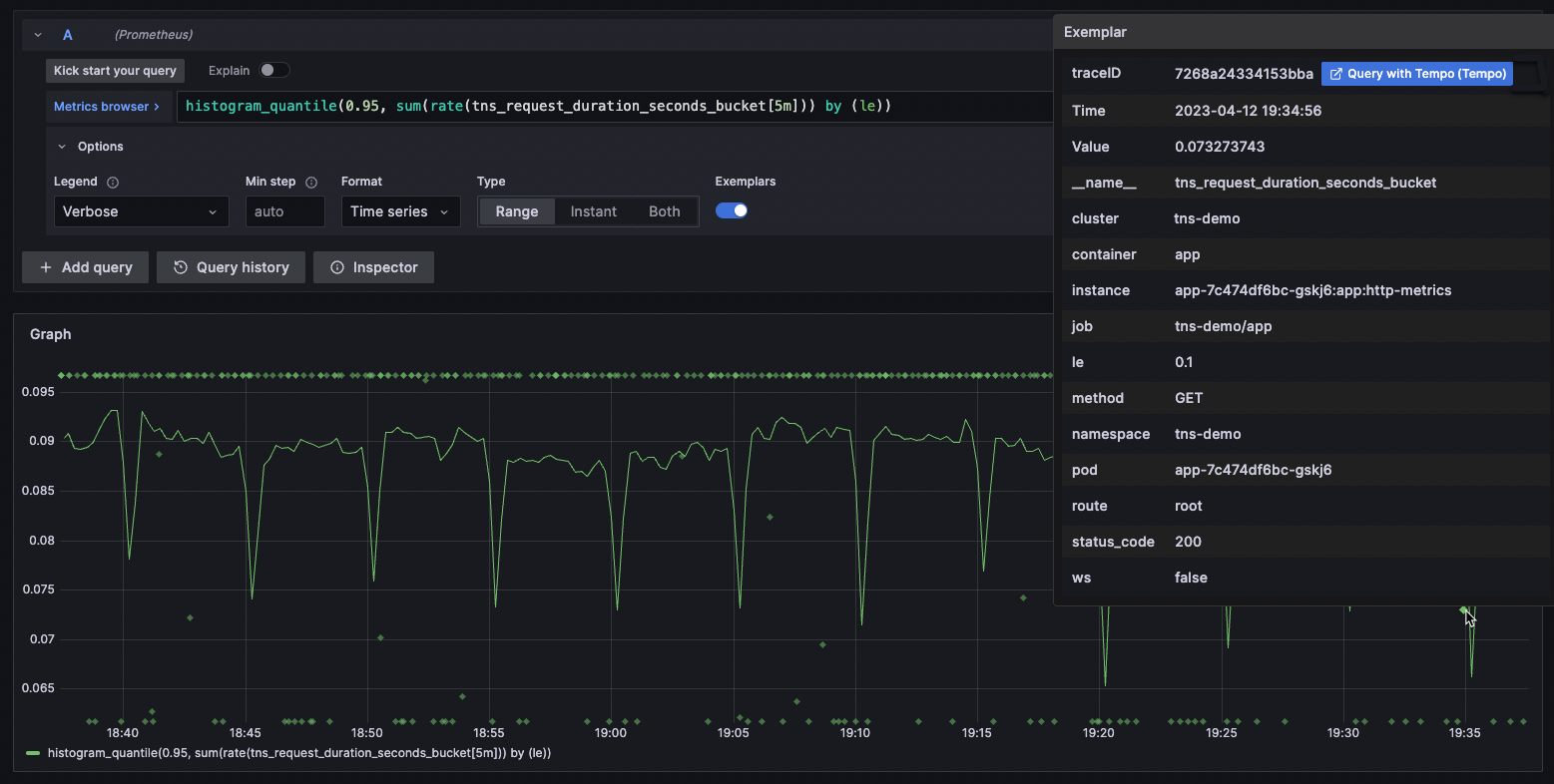
ref: https://grafana.com/docs/grafana/latest/fundamentals/exemplars/
현재 우리 서비스의 cpu 사용률 등을 확인해보자 (이미 적용되어 있다면 내부 로직 또는 코드 확인)
- 메트릭 대시보드는 장애 발생, 도메인/서비스에 문제발생을 즉각 확인할 수 있도록 특화되어야한다
- 응답시간, 에러, 트래픽 등에 관련 지표는 필수이다
- 가능한 태그를 사용해 상황정보를 포함해야한다
1.3 추적
- APM 을 포함하여 자동화 및 데이터 분석 등 확장한 것이 관측 가능성이다
- span
- 소요 시간, 하위 동작 정보, 부모와의 관계 의존성을 고려한 모든 수행 시간을 포함한다
- 태그, 로그, 스팬 콘텍스트 배기지 정보를 포함하고있다
- span context
- 다른 스팬을 참고할 때 span context 를 사용해 가져온다
- inject, extract 를 통해 주고받는다
- span referenece
- 스팬 사이의 인과관계
- baggage
- 다수의 스팬에 전달되고 공유되는 값
1.4 로그
- 시스템에 분산된 로그를 한곳에 저장해서 다룬다
- 어떻게 수집할건지 고려 => 중앙 집중적
- 어떻게 표준화할건지 고려
- 급격하게 증가하는 로그 데이터를 관리하기위해 동적이고 수평적으로 확장하는것이 중요하다
- 로그에 포함할 중요한 요소들
- 타임스탬프
- 식별자 (ex: 주문 아이디, 트랜잭션 아이디 등) => FE와 BE 간 컨벤션을 통일
- 소스 => 쉽게 디버깅할 수 있도록 한다
- 레벨과 카테고리화 (warning, error 등)
- emiiter를 통해 보내는 내용을 선택
- exporter를 통해 받는 로그를 선택
1.5 상관관계
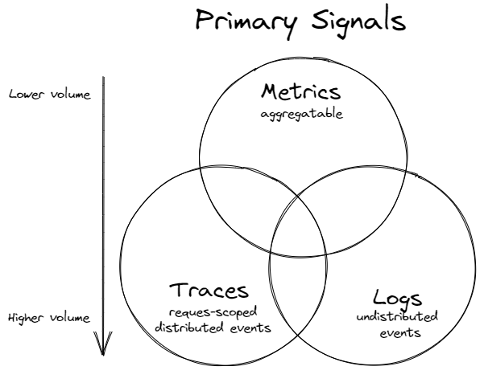
ref: https://microsoft.github.io/code-with-engineering-playbook/observability/log-vs-metric-vs-trace/
- 메트릭에서 수집하면
- 로그에서 레벨화하고
- 추적에서 특정 지표에 대한 세부정보 파악 => prometheus exemplar 를 활용
- 태그, 식별자 등을 이용해 특정 지표에 대한 정보를 얻을 수 있도록 한다
- 단, 모든 지표에 대한 세부정보를 파악하기 보다는 주요 지표에 집중할 수 있도록 한다 (효율성 체크)
- 로그 파일로부터 식별자 등을 통해 추적 세부정보를 파악
1.6 관측 가능성 데모
- 어플리케이션 -> 컬렉터 -> 관측 가능성
- 어플리케이션에서 데이터를 생성하면
- 컬렉터에서 데이터를 수집하고
- 관측 가능성 오픈소스인 로키, 템포, 프로메테우스, 미미르 등을 통해 성능 및 비용절감을 분석한다
- 데이터를 분석하여 시스템과 어플리케이션 운영에 대한 통찰 및 예측
1.7 관측 가능성 레퍼런스 아키텍쳐
- 책 참고
