12. 카프카 운영하기
카프카 클러스터를 운영하기 위해서는 토픽이나 설정 등을 변경하기 위한 추가적인 툴이 필요하다. 기본적으로 카프카에서 제공하는 CLI 인터페이스를 활용해 몇몇 설정을 바꿀 수 있다. 그러나 기본적인 기능 뿐만 아니라 더 복잡한 작업을 수행해야할 때는 코어 프로젝트 바깥에 있는 커뮤니티에서 만든 개발 툴을 사용할 수도 있다. 이번 장에서는 아파치 카프카 오픈소스 프로젝트의 일부로서 사용 가능한 툴에 대해서만 다뤄보자.
기본적으로 카프카는 CLI 를 사용할 때 인증/인가 기능이 비활성화되어있다. 즉, 인증 과정없이 CLI 툴을 사용할 수 있다는 것이다. 인가되지 않은 변경을 방지하고 싶다면 한정된 운영자만이 사용할 수 있도록 조치가 필요할 수 있다.
12.1 토픽작업
카프카에서는 토픽을 생성/변경/삭제하는 작업을 CLI 도구로 수행할 수 있다. 일반적으로는 kafka-topics.sh를 많이 사용하지만, 특정 설정을 변경하거나 세부 옵션을 다루기 위해 kafka-configs.sh도 함께 사용한다. 이 절에서는 실제 운영 환경에서 자주 사용하는 토픽 관련 작업들을 예제와 함께 살펴본다.
12.1.1 새 토픽 생성하기
토픽 생성 시 --create 옵션과 함께 지정해야 하는 대표적인 옵션은 다음과 같다.
-
--topic: 생성할 토픽 이름 -
--partitions: 파티션 개수 -
--replication-factor: 복제 계수
예를 들어, 파티션 3개, 복제 계수 2인 user_events라는 토픽을 생성해보자.
# 파일명: 예시 명령
kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic user_events \
--partitions 3 \
--replication-factor 2이때 if-not-exist 옵션을 통해 이미 존재한다면 스킵하도록 처리할 수도 있다.
왜 토픽 이름에
.(dot)을 사용하지 않을까?토픽 이름에는 기본적으로 알파벳, 숫자,
-,_,.등을 사용할 수 있지만, 카프카 내부적으로 사용하는 지표에서는.을_로 치환하는 경우가 있기 때문에 토픽 이름에.(dot)을 사용하지 않는 것을 권장하는 편이다.
12.1.2 토픽 목록 조회하기
현재 클러스터에 존재하는 토픽 목록을 확인하려면 --list 옵션을 사용한다.
kafka-topics.sh \
--bootstrap-server localhost:9092 \
--list
# output
__consumer_offsets
user_events
payment-events
inventory_updates12.1.3 토픽 상세내역 조회하기
특정 토픽의 파티션 수, 리플리카, 리더/팔로워 배치 등 상세 정보를 확인하려면 --describe 옵션을 사용한다.
kafka-topics.sh \
--bootstrap-server localhost:9092 \
--describe \
--topic user_events
# output
Topic: user_events TopicId: abcdefghijklmnop PartitionCount: 3 ReplicationFactor: 2 Configs: retention.ms=604800000
Topic: user_events Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: user_events Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: user_events Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1
-
PartitionCount: 토픽의 파티션 개수 -
ReplicationFactor: 복제 계수 -
Configs: 토픽에 설정된 주요 설정값들 -
Leader: 해당 파티션의 리더 브로커 ID -
Replicas: 해당 파티션을 복제하는 브로커 목록 -
Isr (In-Sync Replicas): 현재 리더와 동기화된 브로커 목록
12.1.4 파티션 추가하기
파티션을 추가하려면 kafka-topics.sh의 --alter 옵션을 사용해서 --partitions 값을 현재보다 크게 지정하면 된다.
예를 들어, 현재 파티션이 3개인 user_events 토픽을 6개로 늘려보자.
kafka-topics.sh \
--bootstrap-server localhost:9092 \
--alter \
--topic user_events \
--partitions 612.1.5 파티션 제거하기
카프카는 기본적으로 기존 토픽의 파티션 수를 줄이는 기능을 제공하지 않는다. (예: 6개 → 3개로 줄이는 것은 불가능)
이는 토픽에 저장된 데이터 일부를 제거하는 것으로써 클라이언트 입장에서 일관적이지 않아보인다. 또한 메시지의 순서도 보장이 안되므로 만약 파티션 수를 줄여야한다면, 새로운 토픽을 만드는 것이 좋다
12.1.6 토픽 삭제하기
사용하지 않는 토픽은 정리해두는 것이 좋다. 불필요한 토픽이 많아지면 불필요한 메타데이터가 쌓이고 클러스터 전반적으로 성능하락이 이뤄질 수 있다. 따라서 더이상 필요하지 않는 토픽은 제거하는 것이 좋다.
토픽 제거는 broker 설정 중에 delete.topic.enable 옵션이 활성화되어야 삭제 가능하며, 명령어를 실행할 때는 삭제 마킹만하고 비동기적으로 삭제된다. 또한 클러스터에 토픽을 제거할 때 사용하는 방식의 한계로 인해 되도록이면 동시에 2개 이상 토픽을 제거하는 것을 권장하지는 않는다.
토픽을 삭제하려면 --delete 옵션을 사용한다.
kafka-topics.sh \
--bootstrap-server localhost:9092 \
--delete \
--topic user_events12.2 컨슈머 그룹 작업
토픽이 프로듀서 측의 논리적 단위라면, 컨슈머 그룹은 소비자 측의 논리적 단위이다. kafka-consumer-groups.sh 도구를 사용하면 컨슈머 그룹의 목록을 조회하고, 특정 그룹의 상태를 확인하거나, 필요에 따라 그룹을 삭제하거나 오프셋을 조정할 수 있다.
12.2.1 컨슈머 그룹 목록 및 상세내역 조회하기
컨슈머 그룹 목록 조회
현재 클러스터 내에 존재하는 컨슈머 그룹 목록을 조회하려면 --list 옵션을 사용한다
kafka-consumer-groups.sh \
--bootstrap-server localhost:9092 \
--list
# output
console-consumer-12345
user-service
payment-service
connect-file-sink컨슈머 그룹 상세내역 조회
특정 컨슈머 그룹의 상태를 확인하려면 --describe 옵션을 사용한다.
kafka-consumer-groups.sh \
--bootstrap-server localhost:9092 \
--describe \
--group user-service
# output 예시
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
user-service user_events 0 10500 10500 0 consumer-user-service-1-abcdef /10.0.0.10 user-service-1
user-service user_events 1 10480 10510 30 consumer-user-service-2-ghijkl /10.0.0.11 user-service-2
user-service user_events 2 10500 10500 0 consumer-user-service-3-mnopqr /10.0.0.12 user-service-3-
GROUP: 컨슈머 그룹 ID
-
TOPIC: 해당 그룹이 구독 중인 토픽
-
PARTITION: 파티션 번호
-
CURRENT-OFFSET: 컨슈머 그룹이 커밋한 마지막 오프셋
-
LOG-END-OFFSET: 브로커에 현재까지 쌓여 있는 마지막 오프셋(최신 위치)
-
LAG:
LOG-END-OFFSET - CURRENT-OFFSET(아직 소비되지 않은 메시지 개수) -
CONSUMER-ID / HOST / CLIENT-ID: 현재 해당 파티션을 소비 중인 컨슈머 인스턴스 정보
12.2.2 컨슈머 그룹 삭제하기
더 이상 사용하지 않는 컨슈머 그룹은 삭제할 수 있다. 만약 하나 이상의 활동중인 컨슈머가 있다면 해당 컨슈머가 포함되어있는 컨슈머 그룹은 제거할 수 없다.
컨슈머 그룹을 삭제하려면 --delete 옵션을 사용한다.
kafka-consumer-groups.sh \
--bootstrap-server localhost:9092 \
--delete \
--group user-service만약 --topic 매개변수를 전달하여 토픽의 이름을 전달하면 컨슈머 그룹 전체를 삭제하는 대신에 컨슈머 그룹이 읽어오고 있는 특정 토픽에 대한 오프셋만 제거한다.
12.2.3 오프셋 관리하기
컨슈머 그룹의 오프셋은 기본적으로 애플리케이션이 자동으로 관리하지만, 운영 중 장애 처리와 같은 상황에서는 오프셋을 수동으로 조정해야 하는 경우가 있다.
오프셋 내보내기
컨슈머 그룹을 csv 파일로 내보내려면 --dry-run 옵션과 함께 --reset-offsets 매개변수를 사용해주면 된다. 이렇게 하면 나중에 오프셋을 가져오거나 롤백하기 위해 사용할 수 있다.
예를 들어, `user-service` 컨슈머 그룹이 읽고 있는 `user_events` 토픽의 오프셋을 내보내고 싶다면 다음과 같이 사용할 수 있다.
```bash
kafka-consumer-groups.sh \
--bootstrap-server localhost:9092 \
--export \
--group user-service \
--topic user_events \
--reset-offsets \
--to-current \
--dry-run > user-service-offsets.csv이렇게 하면 토픽 이름, 파티션 번호, 오프셋 형태로 파일이 저장된다.
오프셋 가져오기
반대로 백업한 파일을 토대로 재설정도 가능하다.
이때 가져오기 전 컨슈머 그룹 내 모든 컨슈머를 중단시켜야된다. 이미 돌아가고 있는 컨슈머가 있다면 새로운 오프셋을 읽어오지 않기 때문에 가져와도 새로 덮어써버린다.
kafka-consumer-groups.sh \
--bootstrap-server localhost:9092 \
--group user-service \
--reset-offsets \
--from-file user-service-offsets.csv \
--execute
12.3 동적 설정 변경
운영 환경에서 클러스터를 재시작하지 않고 설정만 조정해야 하는 경우, kafka-configs.sh 를 사용한다. 이 도구를 이용하면 브로커, 토픽, 사용자, 클라이언트 등 여러 리소스에 대한 설정을 동적으로 추가/변경/삭제할 수 있다.
12.3.1 토픽 설정 기본값 재정의하기
브로커 기본값과 다른 정책을 적용해야 하는 경우가 많다.
예를 들어 브로커 기본 보존 기간이 7일(604,800,000ms)인데, user_events 토픽만 3일로 줄이고 싶다면 다음과 같이 설정한다.
kafka-configs.sh \
--bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name user_events \
--alter \
--add-config retention.ms=259200000동적으로 설정 가능한 토픽 키들은 해당 문서 를 참고하면 된다.
12.3.2 클라이언트와 사용자 설정 기본값 재정의하기
토픽과 마찬가지로, 카프카에서는 클라이언트와 사용자 단위로도 일부 설정을 재정의할 수 있다. 단, 쿼터에 관련된 몇가지 밖에 없다. 가장 일반적인 설정 두 개는
- 특정한 클라이언트 ID 에 대해 브로컬 별 설정되는 프로듀서
- 컨슈머 bytes/sec 속도
예를 들어, user-service라는 client.id를 사용하는 애플리케이션의 프로듀서/컨슈머 속도를 제한하고 싶다면 다음과 같이 설정할 수 있다.
kafka-configs.sh \
--bootstrap-server localhost:9092 \
--entity-type clients \
--entity-name user-service \
--alter \
--add-config producer_byte_rate=1048576,consumer_byte_rate=1048576이때 스로틀링은 브로커 단위로 이뤄진다. 따라서 특정 브로커에 리더 파티션이 몰려있지 않게 균형있는 클러스터여야 한다. 만약 프로듀서 별 쿼터가 10Mbps 일 때 고르게 N 개의 브로커에 전달된다면 쓰기 속도는 10Mbps x N 이 된다. 그러나 리더파티션들이 하나의 브로커에만 몰려있다면 아무리 브로커를 늘려도 10Mbps 이다.
이외에도 브로커 설정 기본값 재정의하기, 재정의된 설정 상세 조회하기, 재설정된 값 제거하기 등을 할 수 있다.
재정의된 설정 상세보기(
--describe) 할 때 기본값을 따르는 설정은 보이지 않는다. 따라서 기본값은 따로 알아두어야한다.
12.4 쓰기 작업과 읽기 작업
토픽과 컨슈머 그룹, 설정을 관리하는 기능 외에도, 운영 과정에서는 단순히 메시지를 직접 써보고(read/write 테스트), 토픽에 쌓인 내용을 확인해야 하는 경우가 많다. 이때 가장 자주 사용하는 도구가 kafka-console-producer.sh와 kafka-console-consumer.sh다.
-
kafka-console-producer.sh: 콘솔에서 입력한 내용을 토픽으로 전송(쓰기) -
kafka-console-consumer.sh: 토픽에 쌓인 메시지를 콘솔로 출력(읽기)
운영 중 토픽 상태를 빠르게 확인하거나, 간단한 재현 테스트를 할 때 매우 유용하다.
12.4.1 콘솔 프로듀서
kafka-console-producer.sh는 표준 입력(터미널에 직접 입력한 텍스트)을 받아서 지정한 토픽으로 전송한다. 가장 기본적인 형태는 다음과 같다.
kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic user_events
# 명령을 실행하면 프롬프트가 대기 상태로 바뀌고, 이후부터 입력하는 각 줄이 모두 `user_events` 토픽으로 전송된다.
> 첫 번째 메시지
> second message12.4.2 콘솔 컨슈머
kafka-console-consumer.sh는 지정된 토픽(또는 토픽 패턴)에서 메시지를 읽어서 콘솔에 출력한다. 가장 기본적인 형태는 다음과 같다.
kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic user_events기본값으로는 새로 들어오는 메시지만 읽는다. 이미 쌓여 있는 과거 메시지까지 모두 읽고 싶다면 --from-beginning 옵션을 추가한다.
kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic user_events \
--from-beginning이외에도 offset, --partition 등 옵션을 통해 어디서부터(또는 어느 파티션에서) 읽어올지 설정할 수도 있다.
12.5 파티션 관리
카프카는 파티션 관리 관련 스크립트도 탑재되어있다. 하나는 리더 레플리카를 다시 선출하기 위한 툴이고, 또 하나는 파티션을 브로커에 할당해주는 저수준 유틸리티이다. 이 두 툴을 클러스터 내 메시지 트래픽 균형을 맞춰야할 때 사용한다.
12.5.1 선호 레플리카 선출
카프카는 각 파티션에 대해 선호 리더(preferred leader) 라는 개념을 가진다. 보통 토픽 생성 시 균형 잡힌 리더/팔로워 분산을 위해 선호 리더가 정해지는데, 장애나 리밸런싱 이후에는 선호 리더가 아닌 브로커가 리더로 남아있을 수 있다.
선호 리더가 아닌 브로커가 계속 리더로 남아 있으면, 특정 브로커에 리더가 몰리면서 부하가 쏠리는 문제가 생길 수 있다. 이때 전체 클러스터에 대해 “선호 리더를 다시 리더로 선출”하는 작업을 수행할 수 있다.
# 전체 다 수행
kafka-leader-election.sh \
--bootstrap-server localhost:9092 \
--all-topic-partitions \
--election-type PREFERRED
# 특정 토픽 파티션
kafka-leader-election.sh \
--bootstrap-server localhost:9092 \
--topic user_events \
--partition 0 \
--election-type PREFERRED12.5.2 파티션 레플리카 변경
운영 중에는 다음과 같은 요구사항이 생길 수 있다.
- 특정 토픽의 복제 팩터를 2 → 3으로 늘려서 내결함성을 높이고 싶다.
- 특정 브로커에서 레플리카를 줄이고, 다른 브로커로 옮기고 싶다.
카프카에서는 레플리카 재할당(Replica Reassignment) 기능을 통해 파티션의 레플리카 구성을 변경한다. 일반적으로는 JSON 파일에 원하는 배치를 정의한 뒤, kafka-reassign-partitions.sh를 사용한다.
예를 들어, user_events 토픽의 레플리카를 브로커 1,2,3에 걸쳐서 다시 배치하고 싶다면 다음과 같이 하면 된다.
# 1. 토픽 목록을 담은 json 파일 생성한다.
{
"topics": [
{ "topic": "user_events" }
],
"version": 1
}
# 이제 `--generate` 옵션을 사용해 제안된 재할당 플랜을 얻는다.
kafka-reassign-partitions.sh \
--bootstrap-server localhost:9092 \
--topics-to-move-json-file topics-to-move.json \
--broker-list 1,2,3 \
--generate위를 통해 복제 팩터 수를 변경하거나 브로커 간 균형있게 레플리카를 배치할 수 있다. 만약 kafka-reassign-partitions.sh 사용할 때 --cancel 옵션을 사용하면 현재 돌아가고 있는 재할당 작업들을 취소하여 파티션 이동을 중단시킬 수 있다. 만약 작동이 정지된 브로커 또는 과부하가 걸린 브로커에서 레플리카를 제거하다가 취소할 경우 클러스터가 원하지 않는 상태로 빠질 수 있다.
크루즈 컨트롤
위와 같이 CLI 를 통해 레플리카를 재배치할 수 있지만 모두 하나하나 설정하기에는 분명 한계가 있다. 크루즈 컨트롤(링크드인 오픈소스)을 사용하면 클러스터 내 균형 유지, 자가회복 등 편리하게 컨트롤할 수 있는 방법도 있다.
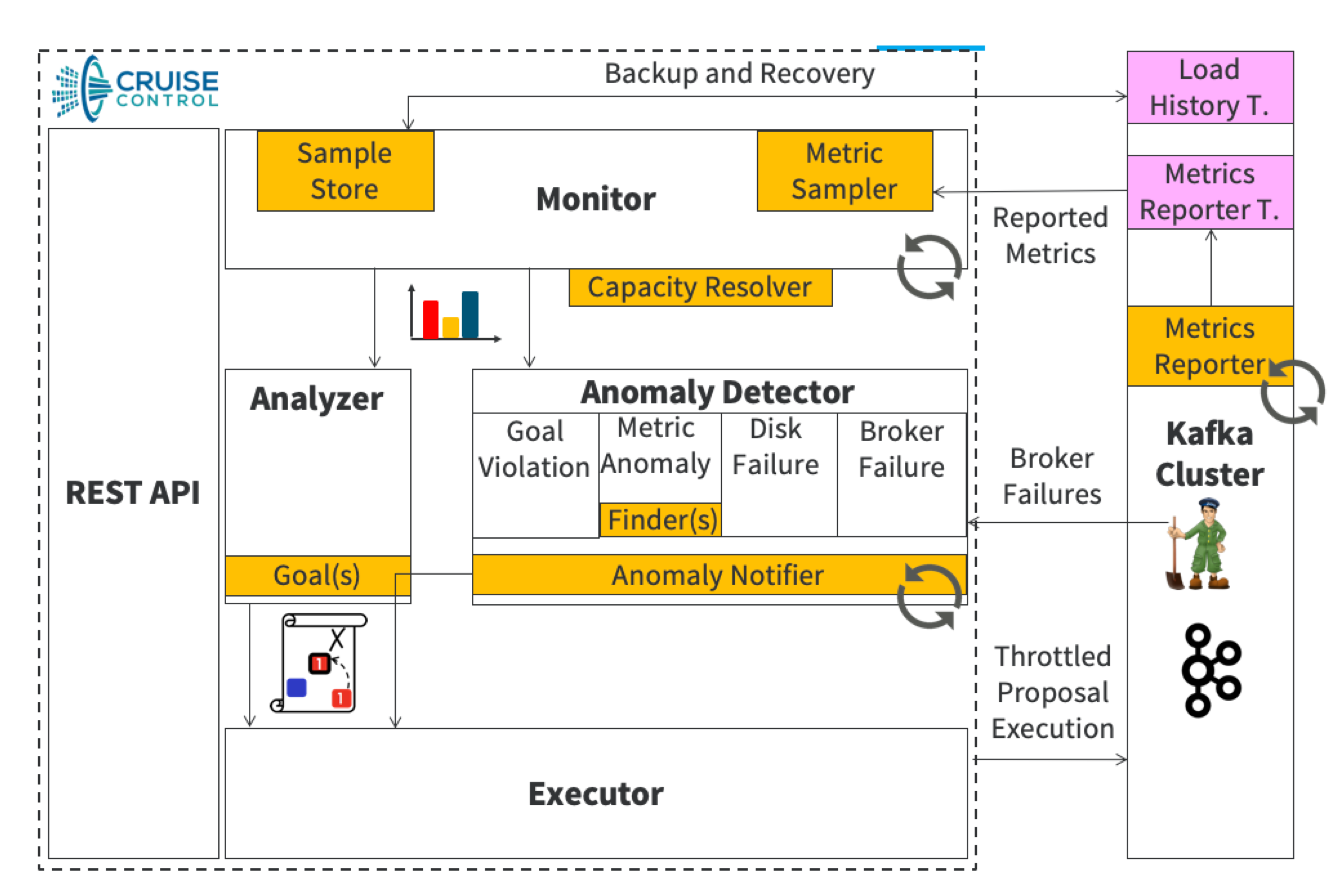
Ref: https://github.com/linkedin/cruise-control/wiki/Overview
-
Load Monitor
▫ Kafka 브로커·파티션 메트릭(디스크, CPU, bytes in/out 등)을 주기적으로 수집
▫ 파티션 단위로 “이 파티션이 어느 정도 부하를 주고 있다”는 클러스터 부하 모델(cluster load model) 을 만든다. -
Analyzer
▫ 부하 모델 + 사용자가 정의한 Goal 목록(우선순위 포함) 을 입력으로 받아
▫ “어떤 파티션/리더를 어디로 옮기면 좋은지” 최적화 제안(Optimization Proposal) 을 만든다.▫ Goal 예:
⁃ 랙 어웨어 유지(하드 목표)
⁃ 브로커 간 디스크·네트워크 사용 균등
⁃ 특정 토픽의 파티션을 브로커에 고르게 분산
⁃ 리더 파티션을 브로커에 고르게 분산 -
Executor
▫ Analyzer가 만든 제안을 실제 Kafka에 적용한다.
12.5.3 로그 세그먼트 덤프 뜨기
토픽 내 특정 메시지(포이즌 필이라고도 함)가 오염되어 컨슈머가 처리할 수 없는 경우 직접 메시지의 내용물을 확인해야 될 때가 있다.
이때 kafka-dump-log.sh 스크립트를 사용하여 덤프를 뜰 수 있다.
kafka-dump-log.sh \
--files /kafka-logs/user_events-0/00000000000000000000.log12.6 기타 툴
이외에도 클라이언트 ACL, 경량 미러메이커, 테스트를 위한 툴들도 존재한다.
