
목적
알고리즘을 공부하는중에 누적합을 공부하다가 DP알고리즘이 생각이 제대로 안나서 복습할 목적으로 글을 작성한다.
1. 개요
DP 다이나미 프로그래밍(동적 계획법)은 기본적인 아이디어로 하나의 큰 문제를 여러개의 작은 문제로 나누어서 그 결과를 저장하여 다시 큰 문제를 해결할때 사용하는 것이다.
2. DP를 사용하는 이유
일반적으로 재귀(Naive Recursion)방식 또한 DP와 매우 유사하다. 차이점은 일반적인 재귀를 단순히 사용시 동일한 작은 문제들이 여러번 반복되어 비효율적인 계산될 수 있다.
피보나치 수열을 예로들수 있다.
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144 ...
피보나치 수를 구하고 싶을때 재귀로 함수를 구성하면 return f(n) = f(n-1) + f(n-2) 이렇게 단순히 구성이 가능하다. 그런데 f(n-1), f(n-2)에서 각 함수를 1번씩 호출하면 동일한 값을 2번씩 구하게 되고 이로 인해 100번째 피보나치 수를 구하기 위해 호출되는 함수의 횟수는 기하급수 적으로 증가한다. 왜냐하면 f(n-1)에서 한번 구한 값을 f(n-2)에서 또 다시 같은 값을 구하는 과정을 반복하게 되기 때문이다.
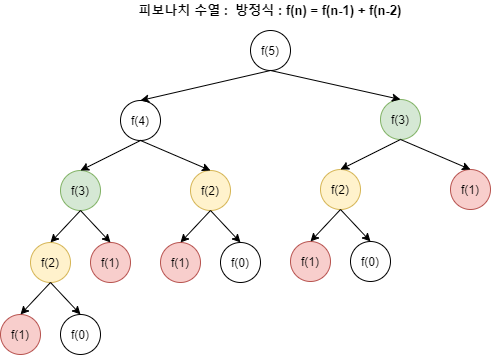
피보나치 수열 함수 호출 트리그러나 한번 구한 작은 문제의 결과 값을 저장해두고 재사용 한다면 어떻게 될까? 앞에서 계산된 값을 다시 반복할 필요가 없이 약 200회 내에 계싼이 가능해진다.
매우 효율적으로 문제를 해결할 수 있게 된다. 시간복잡도를 기준으로 O(n^2) -> O(f(n)) 로 개선이 가능하다.
3. DP의 사용조건
- Overlapping Subproblems(겹치는 부분 문제)
- Optimal Substructure(최적 부분 구조)
Overlapping Subproblems(겹치는 부분 문제)
DP는 기본적으로 문제를 나누고 그 문제의 결과 값을 재활용해서 전체 답을 구한다. 그래서 동일한 작은 문제들이 반복하여 나타나는 경우에 사용이 가능하다.
DP는 부분 문제의 결과를 저장하여 재 계산하지 않을 수 있어야 하는데 해당 부분 문제가 반복적으로 나타나지 않는다면 재 사용이 불가능하니 부분 문제가 중복되지 않는 경우에는 사용할 수 없다.
이진 탐색은 특정 데이터를 정렬된 배열 내에서 그 위치를 찾기 때문에 그 위치를 찾은 후 바로 반환할 뿐 그것을 재사용하는 과정을 거치지 않는다. 피보나치 수열은 f(n) = f(n-1) + f(n-2)인데, 아래와 같이 트리구조로 함수가 호출된다.
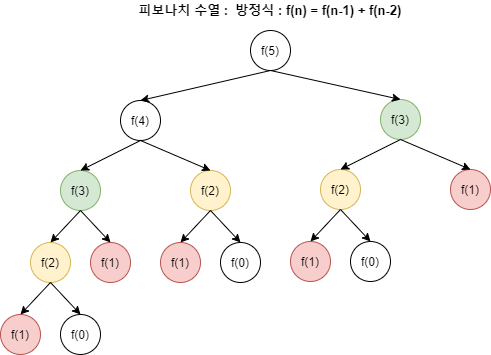
피보나치 수열 함수 호출 트리f(3), f(2), f(1)과 같이 동일한 부분 문제가 중복되어 나타난다. 그러므로 1회 계산했을때 저장된 값을 재활용할 수 있게된다.
Optimal Substructure(최적 부분 구조)
부분 문제의 최적 결과 값을 사용해 전체 문제의 최적 결과를 낼 수 있는 경우를 의미한다. 그래서 특정 문제의 정답은 문제의 크기에 상관없이 항상 동일하다.
만약 A-B까지의 가장 짧은 경로를 찾고자 하는 경우를 예시로 할때 중간에 X가 있을때 A-X/X-B가 많은 경로 중 가장 짧은 경로라면 전체 최적 경로도 A-X-B가 정답이 된다.
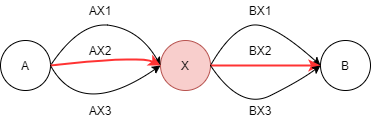
최단 경로 찾기A-X 사이의 최단 거리는 AX2이고 X-B 사이의 최단 거리는 BX2이다. 전체 최단 경로는 AX2-BX2이다. 다른 경로를 택한다고 해서 전체 최단 경로가 변할 수는 없다.
이와 같이 부분 문제에서 구한 최적 결과가 전체 문제에서도 동일하게 적용되어 결과가 변하지 않을때 DP를 사용할 수 있게된다. 피보나치 수열도 동일하게 이전의 계산 값을 그대로 사용하여 전체 답을 구할 수 있어 최적 부분 구조를 갖고 있다.
4. DP 사용하기
DP는 특정한 경우에 사용하는 알고리즘이 아니라 하나의 방법론이므로 다양한 문제 해결에 쓰일 수 있다. 그래서 DP를 적용할 수 있는 문제인지를 알아내는 것부터 코드를 짜는 과정이 난이도가 쉬운 것부터 어려운 것까지 다양하다.
일반적으로 DP를 사용하기 전에는 아래의 과정을 거쳐 진행할 수 있다.
-
DP로 풀 수 있는 문제인지 확인한다.
-
문제의 변수 파악
-
변수 간 관계식 만들기(점화식)
-
메모하기(memoization or tabulation)
-
기저 상태 파악하기
-
구현하기
-
DP로 풀 수 있는 문제인지 확인
DP의 조건 부분에서 확인할 수 있듯이 현재 직면한 문제가 작은 문제들로 이루어진 하나의 함수로 표현될 수 있는지 판단해야 한다. 조건들이 충족되는 문제인지를 체크해봐야한다.
보통 즉정 데이터 내 최대화 / 최소화 계싼을 하거나 특정 조건 내 데이터를 세야 한다거나 확률 등의 계산의 경우 DP로 풀 수 있는 경우가 많다.
- 문제의 변수 파악
DP는 현재 변수에 따라 그 결과 값을 찾고 그것을 전달하여 재사용하는 것을 거친다. 문제 내 변수의 개수를 알아내야 한다는 것 이것을 영어로 "state"를 결정한다고 한다.
피보나치 수열에서는 n번째 숫자를 구하는 것이므로 n이 변수가 된다. 그 변수가 얼마이냐에 따라 결과값이 다르지만 그 결과를 재사용하고 있다. 또한 문자열 간의 차이를 구할때는 문자열의 길이 Edit거리 등 2가지 변수를 사용한다.
- 변수 간 관계식 만들기
변수들에 의해 결과 값이 달라지지만 동일한 변수값인 경우 결과는 동일하다. 또한 우리는 그 결과값을 그대로 이용할 것이므로 그 관계식을 만들어 낼 수 있어야 한다.
그러한 식을 점화식이라고 부르며 그를 통해 우리면 짧은 코드 내에서 반복/재귀를 통해 문제가 자동으로 해결되도록 구축할 수 있게 된다.
피보나치 수열에서는 f(n) = f(n-1) + f(n-2)였다. 이는 변수의 개수 문제의 상황마다 모두 다를 수 있다.
- 메모하기
변수 간 관계식까지 정상적으로 생성되었다면 변수의 값에 따른 결과를 저장해야 한다. 이것을 메모한다고하여 Memoization이라고 부른다.
변수 값에 따른 결과를 저장할 배열등을 미리 만들고 그 결과를 나올때마다 배열 내에 저장하고 그 저장된 값을 재사용하는 방식으로 문제를 해결한다.
이 결과 값을 저장할때는 보통 배열을 쓰며 변수의 개수레 따라 배열의 차원이 1~3차원등 다양할 수 있다.
- 기저 상태 파악
여기까지 진행했으면, 가장 작은 문제의 상태를 알아야 한다. 보통 몇 가지 예시를 직접 손으로 테스트하여 구성하는 경우가 많다.
피보나치 수열을 예시로 들면, f(0) = 0, f(1) = 1과 같은 방식이다. 이후 두 가지 숫자를 더해가며 값을 구하지만 가장 작은 문제는 저 2개로 볼 수 있다.
해당 기저 문제에 대해 파악 후 미리 배열 등에 저장해두면 된다. 이 경우, 피보나치 수열은 매우 간단했지만 문제에 따라 좀 복잡할 수 있다.
- 구현하기
개념과 DP를 사용하는 조건, DP 문제를 해결하는 과정도 익혔으니 실제로 어떻게 사용할 수 있는지를 알아보고자 한다. DP는 2가지 방식으로 구현할 수 있다.
1) Bottom-Up (Tabulation 방식) - 반복문 사용
2) Top-Down (Memoization 방식) - 재귀 사용
1) Bottom-Up (Tabulation 방식)
이름에서 보이듯이, 아래에서 부터 계산을 수행 하고 누적시켜서 전체 큰 문제를 해결하는 방식이다.
메모를 위해서 dp라는 배열을 만들었고 이것이 1차원이라 가정했을 때, dp[0]가 기저 상태이고 dp[n]을 목표 상태라고 하자. Bottom-up은 dp[0]부터 시작하여 반복문을 통해 점화식으로 결과를 내서 dp[n]까지 그 값을 전이시켜 재활용하는 방식이다.
사실 위에서 메모하기 부분에서 Memoization이라고 했는데 Bottom-up일 때는 Tabulation이라고 부른다.
왜냐면 반복을 통해 dp[0]부터 하나 하나씩 채우는 과정을 "table-filling" 하며, 이 Table에 저장된 값에 직접 접근하여 재활용하므로 Tabulation이라는 명칭이 붙었다고 한다.
사실상 근본적인 개념은 결과값을 기억하고 재활용한다는 측면에서 메모하기(Memoization)와 크게 다르지 않다.
2) Top-Down (Memoization 방식)
이는 dp[0]의 기저 상태에서 출발하는 대신 dp[n]의 값을 찾기 위해 위에서 부터 바로 호출을 시작하여 dp[0]의 상태까지 내려간 다음 해당 결과 값을 재귀를 통해 전이시켜 재활용하는 방식이다.
피보나치의 예시처럼, f(n) = f(n-2) + f(n-1)의 과정에서 함수 호출 트리의 과정에서 보이듯, n=5일 때, f(3), f(2)의 동일한 계산이 반복적으로 나오게 된다.
이 때, 이미 이전에 계산을 완료한 경우에는 단순히 메모리에 저장되어 있던 내역을 꺼내서 활용하면 된다. 그래서 가장 최근의 상태 값을 메모해 두었다고 하여 Memoization 이라고 부른다.
참조
https://hongjw1938.tistory.com/47
마무리
내용을 정리하고 다시한번 읽어봤지만 아직도 이해가 안돼는 부분이 있다. 알고리즘 풀려면 생각을 많이 해야하는데 정말 어려운것같다. 사고력을 기르기 위해서 책을 좀 많이 봐야할것같다.
