
목표
알고리즘을 풀다가 Scanner와 BufferedReader 중에서 뭐가 어떻게 다르길래 실행시간에서 차이가 나는지 Scanner와 BufferedReader 중에서 무엇을 사용해야 효율적인 코드를 작성할 수 있을지 생각하다가 이번 기회를 이용해서 확실히 정리하고 싶다는 생각이 들었고 그래서 글을 작성하기로했다.
Scanner
Scanner 클래스는 입력받은 데이터(바이트)를 다양한 타입으로 변환하여 반환하는 클래스이다. 기본형과 String 타입을 정규표현식을 사용해서 파싱할 수 있다.
Scanner 특징
java.uitl 패키지에 속한 클래스이다.
공백 및 개행을 기준으로 읽는다.
원하는 타입으로 읽을 수 있다.
버퍼의 기본 크기는 1KB(1024Byte)이다.
BufferedReader
데이터를 한번에 읽어와 버퍼에 보관한 후 버퍼에서 데이터를 읽어오는 방식으로 동작하는 클래스이다. 즉 사용자가 입력한 문자 스트림을 읽는 것이다.
Buffer(버퍼)
데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 해당 데이터를 보관하는 임시 메모리 영역이다. 주로 입력과 출력 속도 향상을 위해 Buffer를 사용한다.
Java에서는 Buffer를 BufferedReader와 BufferedWriter라는 클래스를 제공하여 사용할 수 있다.
BufferedReader 특징
java.io 패키지에 속한 클래스이다.
데이터를 파싱하지 않고 String으로만 읽고 가져올 수 있다.
버퍼의 기본 크기는 8KB(8192Byte)이다.
Scanner 작성법
import java.util.scanner;
Scanner sc = new Scanner(System.in);
String st = sc.nextLine();
System.in을 통해 Scanner 객체를 생성한다.
System.in
System.in은 표준 입력 스트림(standard input stream)을 나타내는 표준 입력 객체이다. 이 객체를 통해 프로그램이 실행 중 사용자로부터 입력을 받을 수 있다. 즉 콘솔로부터 입력을 받이 위해서는 대부분의 경우 System.in을 인자로 전달해야 한다.
BufferedReader 작성법
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
public static void main(String[] args) throws IOException {
BufferReader br = new BufferedReader(InputStreamReader(System.in));
String st = br.readLine();
int a = Integer.parseInt(br.readLine());
int b = Integer.parseInt(st);
}BufferedReader는 매개변수로 InputStreamReader를 사용하여 객체를 생성한다.
InputStreamReader
문자 기반으로 보조 스트림으로써 바이트 기반 스트림을 문자 기반 스트림으로 연결시켜 주는 역할을 한다.
시스템의 표준 입력이나 파일 입력 같은 바이트 기반 스트림을 입력 받는다.
Scanner와 BufferedReader 비교
Scanner는 입력된 데이터를 파싱하여 token 단위로 쪼개어 읽어온다. 그리고 BufferedReader는 입력 데이터를 그래도 읽어오기만 한다고 나는 이해했다.
Scanner는 BufferedReader보다 타입에 구애받지 않는다.
BufferedReader는 String 형식으로만 읽고 저장하기에 형변환을 위한 추가적인 코드작성이 불가피한 반면에 Scanner는 원하는 타입으로 읽고 파싱할 수 있다.
Scanner의 경우는 int, long, short, float, doulbe의 경우 nextInt(), nextLong(), nextShort(), nextFloat(), nextDouble()과 같은 함수들을 사용할 수 있다. 하지만 BufferedReader는 readLine() 함수만 사용할 수 있다.
BufferedReader는 Scanner보다 효율적인 메모리 용량을 가지고있다.
BufferedReader의 버퍼 메모리가 8KB이고 Scanner의 버퍼 메모리는 1KB이다. 둘다 비교해 봤을때 BufferedReader의 버퍼 메모리가 더 크기에 입력을 많이 받았을 경우에 더 효율적이다. 하지만 BufferedReader의 경우에는 큰 메모리를 잡아 먹을수 있다.
BufferedReader는 Scanner보다 안전하다.
Scanner는 스레드 안전을 하기에는 멀티스레드 환경에서 안전하지 않지만 BufferedReader는 안전한다.
스레드 간 Scanner는 공유할 수 없지만 BufferedReader는 공유할 수 있다. 동기화를 지원하는 BufferedReader는 싱글스레드인 Scanner보다 약간 느리다. Scanner의 경우에는 정규식을 사용하여 입력을 받지만 BufferedReader는 문자열을 더욱 빠르게 입력받을 수 있다.
속도적인 측면에서도 BufferedReader가 Scanner보다 실행 속도가 빠르다.
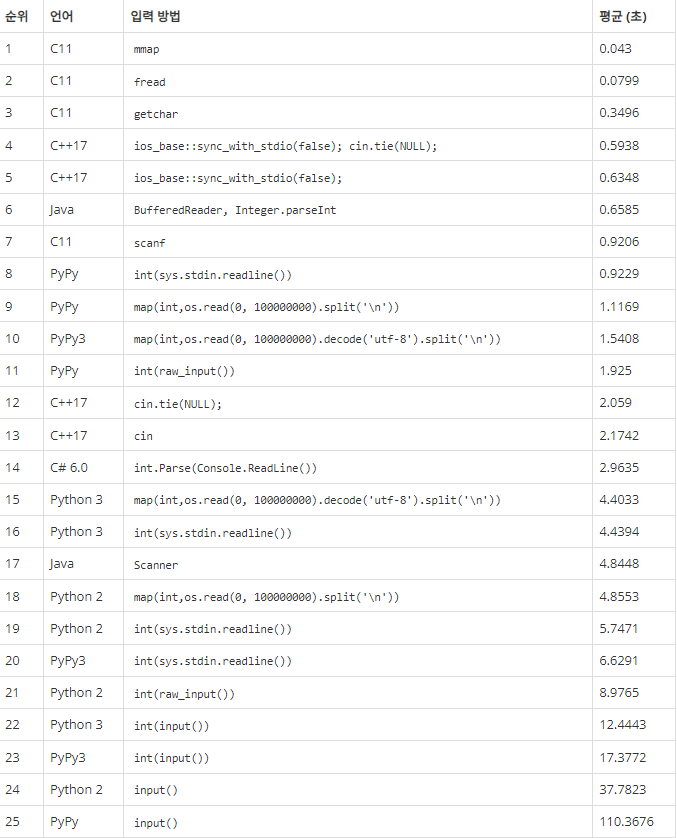
참고[1]
백준에서 작성된 입력속도 비교표를 확인해보면 BufferedReader는 0.6585초 이다.
Scanner는 4.8448초가 소요되며 둘의 시간차이는 생각보다 크다.
BufferedReader가 왜 조금더 빠를까?
BufferedReader는 문자 기반 버퍼를 사용하여 한번에 대량의 데이터를 읽어올 수 있다.
반면 Scanner는 데이터를 실시간으로 파싱하고 토큰화해야 하므로 단위 데이터 처리 속도가 느리다. 즉, BufferedReader는 버퍼를 이용해서 대량 읽기를 하기 때문에 입출력 횟수가 적고 속도가 빠르지만, Scanner는 실시간 파싱과 토큰화 과정에서 오버헤드가 발생하므로 상대적으로 느리다고 볼 수 있다.
로컬에서는 속도차이가 얼마 나는지 궁금해졌다.
로컬에서 Scanner와 BufferedReader 속도 차이가 얼마 나는지 궁금해져서 코드를 작성해봤다.
Scanner 코드
package baekjoon.baekjoon_18;
import java.util.Scanner;
public class test{
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
long startTime = System.currentTimeMillis(); // 실행 시작 시간 저장
int a = sc.nextInt();
int b = sc.nextInt();
int sum = a + b;
System.out.println(sum);
long endTime = System.currentTimeMillis(); // 실행 종료 시간 저장
long execTime = endTime - startTime; // 실행 시간 계산 (종료 시간 - 시작 시간)
System.out.println("실행 시간 : " + execTime + "ms");
// 메모리 사용량 측정
long heapSize = Runtime.getRuntime().totalMemory();
System.out.println("총 힙 메모리 크기 : " + heapSize + " bytes");
long heapFreeSize = Runtime.getRuntime().freeMemory();
System.out.println("사용 가능한 힙 메모리 크기 : " + heapFreeSize + " bytes");
sc.close();
}
}
Scanner 객체를 생성해서 nextInt()함수를 통해 a와 b를 입력받아 합을 구했다.
BufferedReader 코드
package baekjoon.baekjoon_18;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class test1 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
long startTime = System.currentTimeMillis(); // 시작 시간
String s = br.readLine();
StringTokenizer st = new StringTokenizer(s);
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
System.out.println(a + b);
long endTime = System.currentTimeMillis(); // 종료 시간
long execTime = endTime - startTime; // 실행 시간
System.out.println("실행 시간: " + execTime + " ms");
long heapSize = Runtime.getRuntime().totalMemory();
System.out.println("총 힙 사이즈: " + heapSize + " bytes");
br.close();
}
}BufferedReader를 객체를 생성하고 한줄 단위로 처리할 수 있는 readLine() 함수를 통해 s에 저장한 뒤 StringTokenizer 객체를 사용하여 a와 b에 공백을 기준으로 나누어 저장한뒤 합을 구했다.
StringTokenizer
문자열을 지정한 구분자로 문자열을 쪼개주는 클래스이다. 그렇게 쪼개진 문자열을 토큰이라고 부른다.
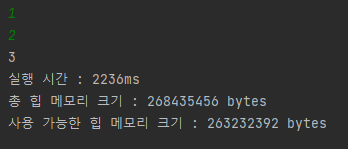
로컬에서 Scanner 실행시간
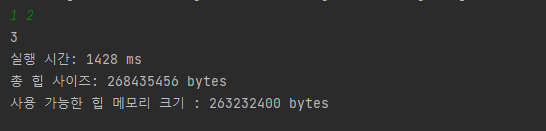
로컬에서 BufferedReader 실행시간
Scanner를 사용했을 경우 2235ms가 걸렸다.
BufferedReader를 사용했을 경우 1428ms가 걸렸다.
BufferedReader의 코드길이가 더 길긴하지만 더 빠른 속도를 보여주고있다.
내 로컬 pc에서 실행했을때 메모리 경우에는
Scanner의 메모리 사용량은 268435456 byte로 측정되었고,
BufferedReader의 메모리 사용량은 263232400 byte로 측적되었다.
Scanner가 사용한 메모리가 약 5203056 byte 더 많은 것을 확인할 수 있다.
이는 BufferedReader가 내부 버퍼를 사용하여 한번에 많은 양의 데이터를 읽어오기 때문에 Scanner보다 더 적은 메모리를 사용한걸로 나는 생각했다.
다만 입력 데이터 양이 적다면 Scanner를 사용하여도 큰 메모리 차이는 없다.
입력 데이터 양이 많아질수록 BufferedReader의 메모리 사용량을 절감할 수 있다는 생각일 들었다.
마무리
오늘 Scanner와 BufferedReader에 대해서 조금더 공부하는 시간을 가져봤다. 평소에는 Scanner와 BufferedReader 쓰고싶은거를 사용했지만 이번 계기를 통해서 메모리적인 측면에서 어떤 클래스가 조금더 효율적으로 메모리를 적게 사용하면서 코드에 적용을 할 수 있을지를 생각해볼 수 있는 계기가 된것같다.
참고
