
문제
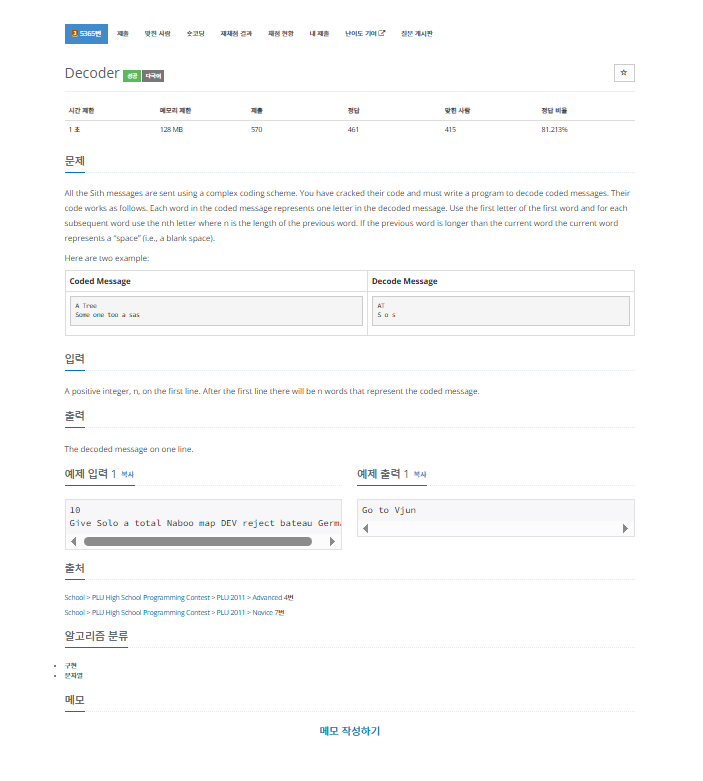
내가 생각했을때 문제에서 원하는부분
A positive integer, n, on the first line.
After the first line there will be n words that represent the coded message.
The decoded message on one line.내가 이 문제를 보고 생각해본 부분
입력 및 출력 준비:
BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); : 대량의 텍스트 입력을 효율적으로 처리하기 위해 BufferedReader를 사용한다.
System.in은 표준 입력 스트림을 나타내며, 이를 InputStreamReader로 래핑하여 문자 기반 입력으로 변환한 후 BufferedReader가 더 빠르게 읽을 수 있도록 한다.
StringBuilder decodedMessage = new StringBuilder(); : 해독된 메시지를 저장할 StringBuilder 객체이다.
String 객체는 불변(immutable)이라서 문자열을 계속 연결하면 새로운 String 객체가 생성되어 메모리 사용과 성능에 비효율적이다.
StringBuilder는 가변(mutable)이므로 문자열을 추가하거나 변경하는 작업에 매우 효율적이다.
int totalNumberOfWords = Integer.parseInt(br.readLine()); : 첫 번째 입력 줄에서, 처리해야 할 총 단어의 개수 N을 읽어와 int형으로 변환하여 totalNumberOfWords 변수에 저장한다.
StringTokenizer st = new StringTokenizer(br.readLine(), " "); : 두 번째 입력 줄에는 해독해야 할 모든 단어들이 공백으로 구분되어 있다.
br.readLine()으로 이 한 줄 전체를 읽어온 다음, StringTokenizer를 사용하여 공백(" ")을 기준으로 단어들을 개별적으로 분리한다.
이렇게 하면 각 단어를 순서대로 쉽게 추출할 수 있다.
변수 초기화:
int previousWordLength = 0; : 이 변수는 이전 단어의 길이를 저장한다.
문제 규칙상, 현재 단어에서 어떤 글자를 가져올지 (또는 공백을 넣을지) 결정할 때 이 previousWordLength 값이 기준이 된다.
처음에는 0으로 초기화되어 있다.
단어 처리 반복문:
for (int i = 0; i < totalNumberOfWords; i++) { ... } : totalNumberOfWords에 저장된 단어의 개수만큼 반복한다.
i는 현재 처리 중인 단어가 전체 단어 중에서 몇 번째인지(0부터 시작하는 인덱스)를 나타낸다.
String currentWord = st.nextToken(); : StringTokenizer에서 다음 단어를 하나 가져와 currentWord 변수에 저장한다.
int currentWordLength = currentWord.length(); : 현재 단어의 길이를 계산하여 currentWordLength에 저장한다.
해독 규칙 적용:
if (i == 0) { ... } (첫 번째 단어 처리):
decodedMessage.append(currentWord.charAt(0)); : i가 0인 경우, 즉 첫 번째 단어일 때는 무조건 그 단어의 첫 번째 글자를 가져와 decodedMessage에 추가한다.
charAt(0)은 문자열의 0번째 인덱스, 즉 첫 번째 문자를 반환한다.
else { ... } (두 번째 단어부터 처리):
if (previousWordLength > currentWordLength) { ... } : i가 0이 아닌 경우, 즉 두 번째 단어부터는 문제의 특별 규칙이 적용된다.
여기서 이전 단어의 길이(previousWordLength)가 현재 단어의 길이(currentWordLength)보다 큰지를 확인한다.
만약 이 조건이 true이면, decodedMessage.append(' ');를 통해 해독된 메시지에 공백 문자를 추가한다.
이 단어는 글자가 아니라 공백을 나타내는 역할을 한다.
else { ... } : previousWordLength가 currentWordLength보다 작거나 같은 경우이다.
decodedMessage.append(currentWord.charAt(previousWordLength - 1)); : 이 경우에는 현재 단어에서 특정 위치의 글자를 가져온다.
문제에서는 "이전 단어의 길이(previousWordLength)를 n으로 하여 현재 단어의 n번째 글자"라고 했다.
Java의 String.charAt() 메서드는 0부터 시작하는 인덱스를 사용하므로, 1부터 시작하는 previousWordLength에서 1을 빼서 0-기반 인덱스(previousWordLength - 1)를 맞춰준다.
예를 들어, previousWordLength가 4라면, charAt(3)을 호출하여 네 번째 글자를 가져오게 된다.
previousWordLength 재설정:
previousWordLength = currentWordLength; : 현재 단어에 대한 모든 처리가 끝난 후, 다음 단어를 처리할 때 사용하기 위해 previousWordLength 변수를 현재 단어의 길이로 재설정한다.
이 재설정은 공백을 추가했든 글자를 추가했든 관계없이 매번 이루어져야 한다.
결과 출력 및 자원 해제:
System.out.println(decodedMessage.toString()); : 모든 단어를 처리하여 해독된 메시지가 StringBuilder에 완성되면, toString() 메서드를 호출하여 String으로 변환한 후 System.out.println()으로 표준 출력 스트림에 출력한다.
br.close(); : 마지막으로, 사용했던 BufferedReader 객체를 닫아 시스템 자원을 깔끔하게 해제한다.코드로 구현
package baekjoon.baekjoon_32;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
// 백준 5365번 문제
public class Main1270 {
public static void main(String[] args) throws IOException {
// 입력을 효율적으로 읽기 위해 BufferedReader를 사용합니다.
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 해독된 메시지를 효율적으로 구성하기 위해 StringBuilder를 사용합니다.
// String 연산을 '+'로 반복하면 성능 저하가 있을 수 있기 때문입니다.
StringBuilder decodedMessage = new StringBuilder();
// 첫 줄에서 총 단어의 개수 N을 읽어옵니다.
int totalNumberOfWords = Integer.parseInt(br.readLine());
// 다음 줄에서 모든 암호화된 단어들을 한 줄로 읽어와 StringTokenizer로 분리합니다.
// 예시: "Give Solo a total Naboo map DEV reject bateau German"
StringTokenizer st = new StringTokenizer(br.readLine(), " "); // 공백을 구분자로 사용합니다.
// 이전 단어의 길이를 저장할 변수입니다.
int previousWordLength = 0;
// 모든 단어를 처리하는 반복문입니다.
// i는 0부터 totalNumberOfWords-1까지 증가하며 각 단어의 순서를 나타냅니다.
for (int i = 0; i < totalNumberOfWords; i++) {
// 현재 처리할 단어를 토크나이저에서 가져옵니다.
String currentWord = st.nextToken();
// 현재 단어의 길이를 구합니다.
int currentWordLength = currentWord.length();
// 첫 번째 단어인 경우 (i == 0)
if (i == 0) {
// 첫 번째 단어의 첫 번째 글자를 해독된 메시지에 추가합니다. (항상 인덱스 0)
decodedMessage.append(currentWord.charAt(0));
}
// 두 번째 단어부터인 경우 (i > 0)
else {
// 해독 규칙 적용: 이전 단어의 길이가 현재 단어의 길이보다 긴 경우
if (previousWordLength > currentWordLength) {
// 이 경우 현재 단어는 '공백'을 의미합니다.
decodedMessage.append(' ');
} else {
// 이전 단어의 길이(previousWordLength)가 n이 되어, 현재 단어의 n번째 글자를 가져옵니다.
// String.charAt()은 0-based 인덱스를 사용하므로 previousWordLength - 1을 해줍니다.
decodedMessage.append(currentWord.charAt(previousWordLength - 1));
}
}
// 다음 반복을 위해 현재 단어의 길이를 previousWordLength에 저장합니다.
// (공백이 추가되었든 글자가 추가되었든, 다음 단어의 해독에는 항상 현재 단어의 길이가 사용됩니다.)
previousWordLength = currentWordLength;
}
// 최종적으로 완성된 해독 메시지를 출력합니다.
System.out.println(decodedMessage.toString());
// 사용한 BufferedReader 자원을 닫아줍니다.
br.close();
}
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer