
문제
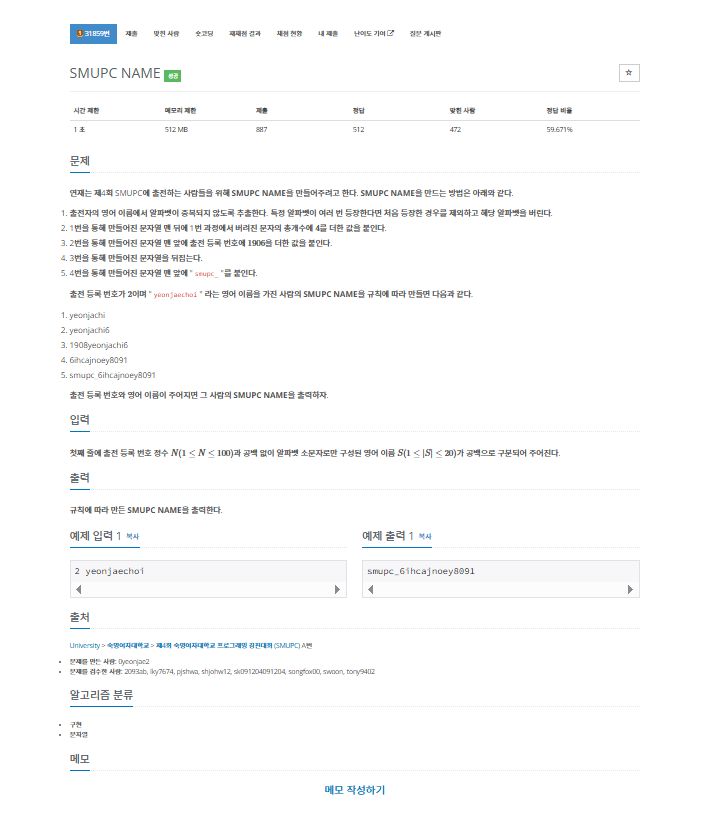
내가 생각했을때 문제에서 원하는부분
첫째 줄에 출전 등록 번호 정수 N (1 ≤ N ≤ 100)과 공백 없이 알파벳 소문자로만 구성된 영어 이름 S (1 ≤ |S| ≤ 20)가 공백으로 구분되어 주어진다.
규칙에 따라 만든 SMUPC NAME을 출력한다.내가 이 문제를 보고 생각해본 부분
입력 처리 (BufferedReader, StringTokenizer):
BufferedReader를 사용하여 한 줄 전체를 읽어온다.
StringTokenizer는 읽어온 문자열(예: "2 yeonjaechoi")을 공백 기준으로 N (등록 번호)과 S (영어 이름)로 분리하는 데 사용된다.
Integer.parseInt(st.nextToken())으로 N을 정수형으로 변환하고, st.nextToken()으로 S를 문자열로 가져온다.
1단계: 중복 없는 알파벳 추출 및 버려진 문자 개수 세기:
StringBuilder uniqueChars: 중복되지 않는 알파벳들을 모아서 최종 문자열을 만들어 나갈 임시 저장소이다.
문자열 연산이 잦을 때 String 대신 StringBuilder를 사용하면 성능에 유리하다.
Set<Character> seenChars = new HashSet<>(): 이미 처리된(즉, uniqueChars에 추가된) 알파벳들을 저장하는 HashSet이다.
HashSet은 요소의 중복을 허용하지 않고, 특정 요소가 집합 안에 있는지 빠르게(O(1)) 확인할 수 있어 이 문제에 적합하다.
discardedCount: 버려진(중복된) 문자의 개수를 세는 변수이다.
for (char c : S.toCharArray()): 입력된 영어 이름 S를 문자 배열로 변환한 뒤, 각 문자를 순회한다.
if (!seenChars.contains(c)): 현재 문자가 seenChars(HashSet)에 아직 없다면, 이는 처음 등장하는 문자라는 의미이다.
uniqueChars.append(c): uniqueChars에 이 문자를 추가한다.
seenChars.add(c): 이 문자를 seenChars에 추가하여, 다음번에 같은 문자가 나타나면 중복으로 처리될 수 있도록 기록한다.
else: 현재 문자가 seenChars에 이미 있다면, 중복된 문자이므로 discardedCount를 1 증가시킨다.
2단계: (버려진 문자 개수 + 4) 추가:
uniqueChars.append(discardedCount + 4): StringBuilder의 append 메서드를 사용하여 1단계에서 생성된 문자열의 맨 뒤에 discardedCount + 4의 값을 이어 붙이다.
3단계: (등록 번호 + 1906) 추가:
uniqueChars.insert(0, N + 1906): StringBuilder의 insert 메서드를 사용하여 0번 인덱스, 즉 문자열의 맨 앞에 N + 1906의 값을 삽입한다.
4단계: 문자열 뒤집기:
uniqueChars.reverse(): StringBuilder가 제공하는 reverse() 메서드를 호출하여 현재 uniqueChars에 담긴 문자열을 통째로 뒤집힌다.
5단계: "smupc_" 추가:
uniqueChars.insert(0, "smupc_"): 4단계와 마찬가지로 insert(0, ...)를 사용하여 맨 앞에 "smupc_" 문자열을 추가한다.
최종 출력:
System.out.println(uniqueChars.toString()): 모든 작업이 끝난 uniqueChars를 toString() 메서드를 통해 다시 String 타입으로 변환한 후 출력한다.
br.close();: BufferedReader를 닫아 시스템 리소스를 해제한다.코드로 구현
package baekjoon.baekjoon_32;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashSet;
import java.util.Set;
import java.util.StringTokenizer;
// 백준 31859번 문제
public class Main1264 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken()); // 출전 등록 번호
String S = st.nextToken(); // 영어 이름
// 1단계: 영어 이름에서 중복되지 않는 알파벳 추출 및 버려진 문자 개수 세기
StringBuilder uniqueChars = new StringBuilder();
Set<Character> seenChars = new HashSet<>(); // 이미 등장한 알파벳을 기록할 Set
int discardedCount = 0; // 버려진 문자 개수
for (char c : S.toCharArray()) {
if (!seenChars.contains(c)) {
uniqueChars.append(c); // 처음 등장하는 문자만 추가
seenChars.add(c); // 등장한 문자로 기록
} else {
discardedCount++; // 이미 등장했던 문자는 버리고 개수 증가
}
}
// 2단계: 생성된 문자열 뒤에 (버려진 문자 개수 + 4) 붙이기
uniqueChars.append(discardedCount + 4);
// 3단계: 생성된 문자열 앞에 (출전 등록 번호 + 1906) 붙이기
// StringBuilder의 insert(0, ...)를 사용하여 맨 앞에 추가
uniqueChars.insert(0, N + 1906);
// 4단계: 생성된 문자열 뒤집기
uniqueChars.reverse();
// 5단계: 생성된 문자열 앞에 "smupc_" 붙이기
uniqueChars.insert(0, "smupc_");
System.out.println(uniqueChars.toString());
br.close();
}
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer