
문제
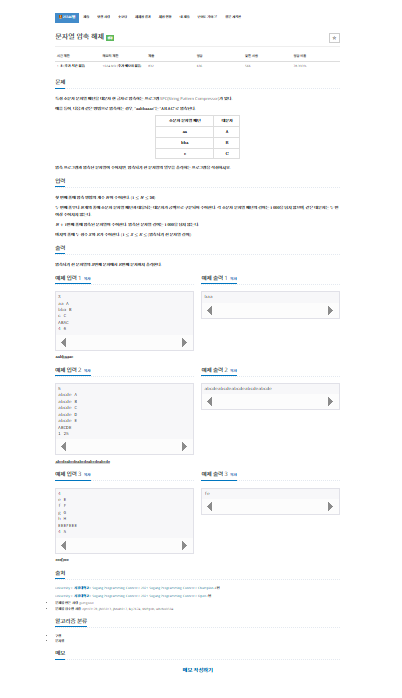
내가 생각했을때 문제에서 원하는부분
첫 번째 줄에 압축 방법의 개수 N이 주어진다. (1 ≤ N ≤ 26)
두 번째 줄부터 N개의 줄에 소문자 문자열 패턴과 대응되는 대문자가 공백으로 구분되어 주어진다.
각 소문자 문자열 패턴의 길이는 1000을 넘지 않으며, 같은 대문자는 두 번 이상 주어지지 않는다.
N+1번째 줄에 압축된 문자열이 주어진다. 압축된 문자열 길이는 1000을 넘지 않는다.
마지막 줄에 두 정수 S와 E가 주어진다. (1 ≤ S ≤ E ≤ (압축되기 전 문자열 길이))
압축되기 전 문자열의 S번째 문자에서 E번째 문자까지 출력한다.내가 이 문제를 보고 생각해본 부분
BufferedReader 초기화:
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedReader는 대량의 입력을 효율적으로 읽어올 때 사용한다.
N 값 읽기:
int N = Integer.parseInt(br.readLine());
첫 번째 줄에 주어지는 압축 방법의 개수 N을 읽어 정수형으로 변환한다.
압축 규칙을 저장할 Map 생성:
Map<Character, String> decompressionMap = new HashMap<>();
여기서는 HashMap을 사용했어요. HashMap은 키-값 쌍을 저장하는 데 최적화된 자료구조이다.
키(Character)는 압축된 대문자, 값(String)은 해당 대문자가 해제되는 소문자 문자열 패턴이 된다.
N개의 압축 규칙 Map에 저장:
for (int i = 0; i < N; i++) { ... }
N번 반복하면서 각 압축 규칙을 읽는다.
String[] parts = br.readLine().split(" "); : 한 줄에 "소문자 패턴 대문자"가 공백으로 구분되어 있으므로, split(" ")를 이용해 공백 기준으로 나누어 parts 배열에 저장한다.
String lowercasePattern = parts[0]; : 배열의 첫 번째 요소가 소문자 패턴이다.
char uppercaseChar = parts[1].charAt(0); : 배열의 두 번째 요소는 대문자이므로, 첫 번째 문자만 char 형태로 가져온다.
decompressionMap.put(uppercaseChar, lowercasePattern); : 이제 이 대문자와 소문자 패턴 쌍을 decompressionMap에 저장한다.
이렇게 하면 나중에 대문자를 보고 어떤 소문자 패턴으로 해제해야 하는지 빠르게 찾을 수 있다.
압축된 문자열 읽기:
String compressedString = br.readLine();
모든 규칙을 저장한 후, 압축된 대문자 문자열을 읽어온다.
StringBuilder로 해제된 문자열 생성 준비:
StringBuilder decompressedStringBuilder = new StringBuilder();
해제된 문자열은 원래 길이가 매우 길어질 수 있다 (최대 1000 * 1000 = 1,000,000 글자). 자바에서 String을 + 연산자로 반복해서 이어 붙이면 성능 저하가 발생하기 때문에, 문자열을 효율적으로 조작할 수 있는 StringBuilder를 사용하는 것이 일반적이다.
압축 해제 과정:
for (char c : compressedString.toCharArray()) { ... }
압축된 문자열 compressedString을 문자(char) 배열로 변환한 후, 각 문자를 순회한다.
decompressedStringBuilder.append(decompressionMap.get(c));
현재 순회 중인 대문자 c를 decompressionMap의 키로 사용하여 해당하는 소문자 패턴(String 타입)을 가져온다.
가져온 소문자 패턴을 decompressedStringBuilder에 뒤에 이어 붙인다.
이 과정이 compressedString의 모든 문자에 대해 반복되면, 완전하게 해제된 문자열이 decompressedStringBuilder 안에 만들어진다.
S와 E 값 읽기:
String[] se = br.readLine().split(" ");
마지막으로 출력 범위인 시작 인덱스 S와 끝 인덱스 E를 읽어 정수형으로 변환한다.
부분 문자열 추출 및 출력:
System.out.println(decompressedStringBuilder.substring(S - 1, E));
문제에서 S와 E는 1-기반 인덱스로 주어졌지만, 자바의 String (그리고 StringBuilder)의 substring 메서드는 0-기반 인덱스를 사용한다.
substring(startIndex, endIndex)는 startIndex부터 endIndex-1까지의 부분을 반환한다.
따라서 1-기반 S를 0-기반 S-1로, 1-기반 E는 substring의 두 번째 인자인 endIndex에 그대로 E를 넣어주면 된다 (이는 E번째 문자 바로 다음까지를 의미하기 때문이다).
예를 들어, 1-번째부터 3-번째까지(S=1, E=3)를 원하면 substring(0, 3)을 사용하면 0, 1, 2번째 문자가 추출된다.
최종적으로 원하는 부분 문자열을 추출하여 출력한다.
BufferedReader 닫기:
br.close();
자원 관리를 위해 사용했던 BufferedReader를 닫아준다.코드로 구현
package baekjoon.baekjoon_31;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
// 백준 23746번 문제
public class Main1255 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 1. 압축 방법의 개수 N 읽기
int N = Integer.parseInt(br.readLine());
// 2. 소문자 문자열 패턴과 대응되는 대문자를 저장할 맵 선언
// (대문자 -> 소문자 패턴) 형식으로 저장합니다.
Map<Character, String> decompressionMap = new HashMap<>();
// 3. N개의 압축 방법 읽어서 맵에 저장
for (int i = 0; i < N; i++) {
String[] parts = br.readLine().split(" ");
String lowercasePattern = parts[0]; // 소문자 문자열 패턴
char uppercaseChar = parts[1].charAt(0); // 대응되는 대문자
decompressionMap.put(uppercaseChar, lowercasePattern);
}
// 4. 압축된 문자열 읽기
String compressedString = br.readLine();
// 5. 압축 해제된 전체 문자열을 생성하기 위해 StringBuilder 사용
// 문자열이 길어질 수 있으므로 효율적인 StringBuilder를 사용합니다.
StringBuilder decompressedStringBuilder = new StringBuilder();
// 6. 압축된 문자열을 순회하며 해제된 문자열 생성
for (char c : compressedString.toCharArray()) {
decompressedStringBuilder.append(decompressionMap.get(c));
}
// 7. 시작 인덱스 S와 끝 인덱스 E 읽기
String[] se = br.readLine().split(" ");
int S = Integer.parseInt(se[0]); // 1-기반 시작 인덱스
int E = Integer.parseInt(se[1]); // 1-기반 끝 인덱스
// 8. 압축 해제된 문자열의 S번째부터 E번째까지의 부분 문자열 추출 및 출력
// 자바의 substring은 (beginIndex, endIndex)로, beginIndex는 포함, endIndex는 포함하지 않습니다.
// 따라서 1-기반 S, E를 0-기반으로 변환해야 합니다. (S-1 부터 E까지)
System.out.println(decompressedStringBuilder.substring(S - 1, E));
br.close();
}
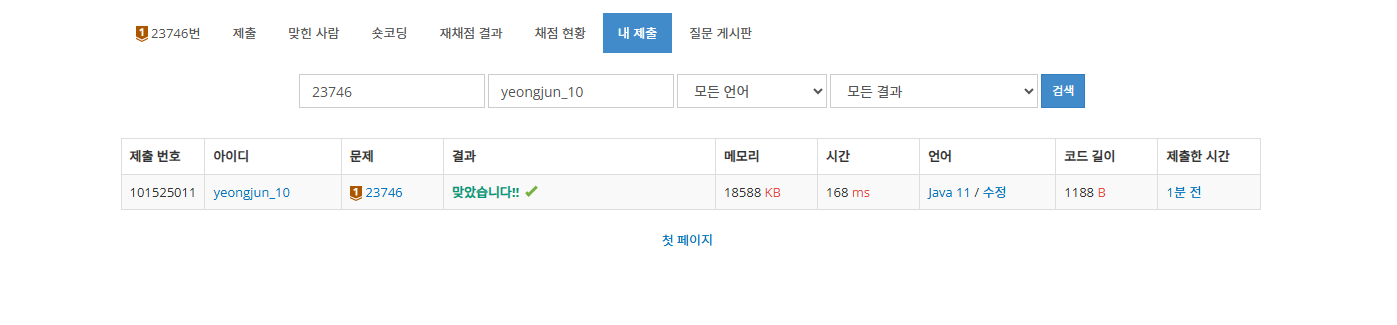
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer