
문제
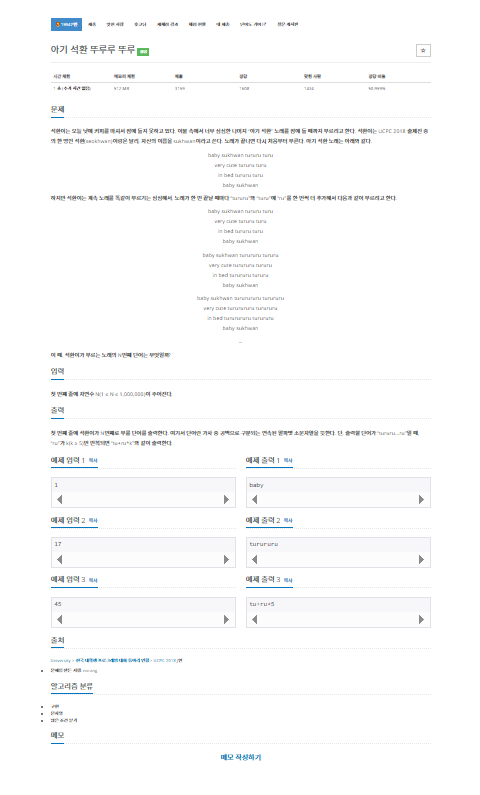
내가 생각했을때 문제에서 원하는부분
첫 번째 줄에 자연수 N(1 ≤ N ≤ 1,000,000)이 주어진다.
첫 번째 줄에 석환이가 N번째로 부를 단어를 출력한다.
여기서 단어란 가사 중 공백으로 구분되는 연속된 알파벳 소문자열을 뜻한다.
단, 출력할 단어가 “tururu...ru”일 때, “ru”가 k(k ≥ 5)번 반복되면 “tu+ru*k”와 같이 출력한다.내가 이 문제를 보고 생각해본 부분
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));:
BufferedReader 객체를 생성하여 표준 입력(키보드 입력)으로부터 데이터를 읽을 준비를 한다.
InputStreamReader는 바이트 스트림( System.in)을 문자 스트림으로 변환해 준다.
int N = Integer.parseInt(br.readLine());:
첫 번째 줄에서 입력되는 N 값을 읽어 정수형으로 변환하여 N 변수에 저장한다.
br.readLine()은 한 줄을 읽어오고, Integer.parseInt()는 이를 정수로 변환한다.
String[] words = { ... };:
아기 석환 노래의 기본 단어들을 순서대로 저장한 String 배열이다.
여기서 tururu와 turu는 실제 변하는 단어의 "형태"를 나타내기 위한 플레이스홀더(자리표시자) 역할을 한다.
이 단어들은 뒤에서 실제 반복 횟수에 따라 문자열을 구성할 것이다.
int N_idx = N - 1;:
문제에서 주어진 N은 1부터 시작하는 순서(1-based index)이므로, 배열 인덱스처럼 0부터 시작하는 순서(0-based index)로 변환하기 위해 N-1을 계산하여 N_idx에 저장한다.
int cycle_idx = N_idx / 14;:
N_idx를 노래의 한 사이클 길이(14)로 나눈 몫은 현재 N번째 단어가 몇 번째 사이클에 속하는지를 알려준다.
예를 들어, N_idx가 0~13이면 cycle_idx는 0, 14~27이면 cycle_idx는 1이 된다.
이 cycle_idx가 'ru'의 추가 반복 횟수를 결정하는 중요한 값이다.
int word_in_cycle_idx = N_idx % 14;:
N_idx를 14로 나눈 나머지는 현재 N번째 단어가 사이클 내에서 몇 번째 단어인지(0부터 13까지)를 알려준다.
이 값은 words 배열에서 어떤 기본 단어를 선택할지 결정하는 데 사용된다.
String currentWord = words[word_in_cycle_idx];:
word_in_cycle_idx를 사용하여 words 배열에서 해당 위치의 기본 단어를 가져온다.
if (currentWord.equals("tururu")) { ... }:
현재 단어가 "tururu"의 형태일 경우를 처리한다.
int ruCount = cycle_idx + 2;: "tururu"는 기본적으로 'ru'가 2번 반복되므로, cycle_idx 값에 2를 더하여 총 'ru' 반복 횟수를 계산한다.
if (ruCount >= 5) { System.out.println("tu+ru*" + ruCount); }: 만약 계산된 ruCount가 5 이상이라면, 특별 출력 규칙인 "tu+ru*k" 형태로 출력한다.
else { ... }: ruCount가 5 미만인 경우, 'ru'를 ruCount 횟수만큼 붙여서 "tururu..." 형태의 문자열을 직접 생성하여 출력한다.
StringBuilder를 사용하여 문자열을 효율적으로 구성한다.
else if (currentWord.equals("turu")) { ... }:
현재 단어가 "turu"의 형태일 경우를 처리한다.
"tururu"와 동일한 로직을 따르되, ruCount 계산만 다르다.
int ruCount = cycle_idx + 1;: "turu"는 기본적으로 'ru'가 1번 반복되므로, cycle_idx 값에 1을 더하여 총 'ru' 반복 횟수를 계산한다.
나머지 출력 로직은 "tururu"와 동일한다.
else { ... }:
"tururu"나 "turu" 계열 단어가 아닌, "baby", "sukhwan" 등과 같은 고정 단어일 경우를 처리한다.
System.out.println(currentWord);: 이 경우 단어는 변하지 않으므로, words 배열에서 가져온 currentWord를 그대로 출력한다.
br.close();:
더 이상 입력을 받을 필요가 없으므로 BufferedReader를 닫아 자원을 해제한다.코드로 구현
package baekjoon.baekjoon_30;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
// 백준 15947번 문제
public class Main1145 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
// 14개 단어로 이루어진 한 사이클의 단어들을 배열에 저장
// (단, tururu와 turu는 가변적이므로 placeholder처럼 사용)
String[] words = {
"baby", "sukhwan", "tururu", "turu",
"very", "cute", "tururu", "turu",
"in", "bed", "tururu", "turu",
"baby", "sukhwan"
};
// N은 1부터 시작하므로, 0부터 시작하는 인덱스로 조정 (N-1)
int N_idx = N - 1;
// 현재 N번째 단어가 속한 사이클 인덱스 계산 (0, 1, 2...)
// 예: N=1~14 -> cycle_idx=0, N=15~28 -> cycle_idx=1
int cycle_idx = N_idx / 14;
// 현재 N번째 단어의 사이클 내에서의 인덱스 계산 (0~13)
int word_in_cycle_idx = N_idx % 14;
// 해당 인덱스의 기본 단어를 가져옴
String currentWord = words[word_in_cycle_idx];
// "tururu" 또는 "turu" 계열 단어인지 확인하여 길이 조정
if(currentWord.equals("tururu")) {
// "tururu"는 기본 'ru'가 2개 있으므로, cycle_idx만큼 추가
int ruCount = cycle_idx + 2;
if(ruCount >= 5) {
System.out.println("tu+ru*" + ruCount);
} else {
StringBuilder sb = new StringBuilder("tu");
for(int i = 0; i < ruCount; i++) {
sb.append("ru");
}
System.out.println(sb.toString());
}
} else if(currentWord.equals("turu")) {
// "turu"는 기본 'ru'가 1개 있으므로, cycle_idx만큼 추가
int ruCount = cycle_idx + 1;
if(ruCount >= 5) {
System.out.println("tu+ru*" + ruCount);
} else {
StringBuilder sb = new StringBuilder("tu");
for(int i = 0; i < ruCount; i++) {
sb.append("ru");
}
System.out.println(sb.toString());
}
} else {
// 고정 단어인 경우 그대로 출력
System.out.println(currentWord);
}
br.close();
}
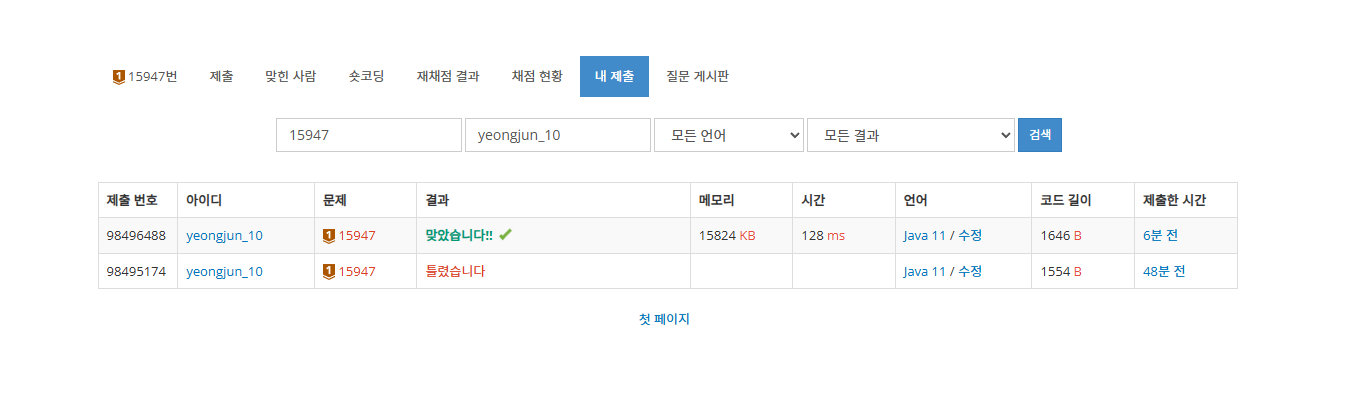
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer