
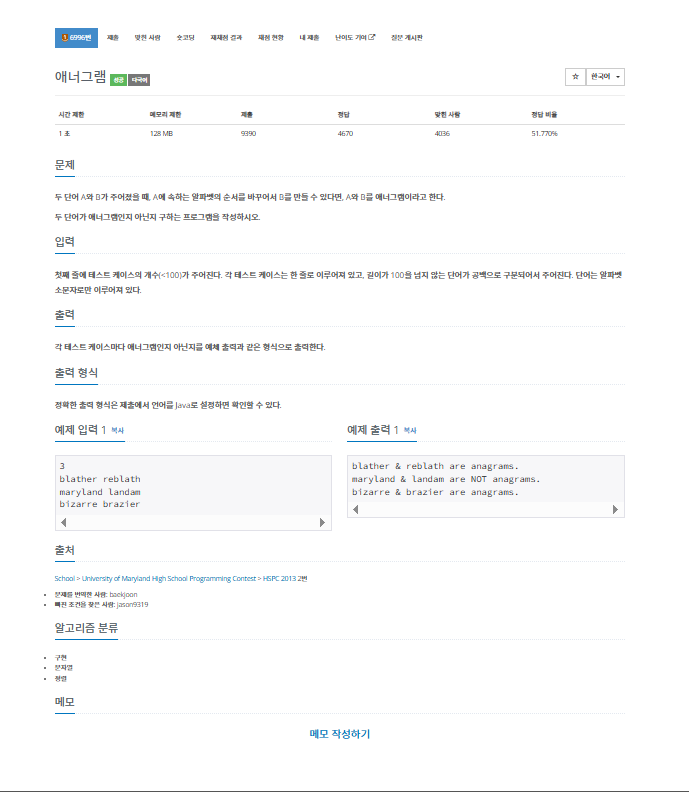
문제
내가 생각했을때 문제에서 원하는부분
첫째 줄에 테스트 케이스의 개수(<100)가 주어진다.
각 테스트 케이스는 한 줄로 이루어져 있고, 길이가 100을 넘지 않는 단어가 공백으로 구분되어서 주어진다.
단어는 알파벳 소문자로만 이루어져 있다.
각 테스트 케이스마다 애너그램인지 아닌지를 예체 출력과 같은 형식으로 출력한다.
정확한 출력 형식은 제출에서 언어를 Java로 설정하면 확인할 수 있다.내가 이 문제를 보고 생각해본 부분
입력 처리: BufferedReader를 사용하여 입력을 빠르게 처리한다.
테스트 케이스 수 입력: 첫 번째 줄에서 테스트 케이스의 개수를 읽는다.
단어 비교: 각 테스트 케이스마다 두 단어를 읽고, 각각의 문자를 정렬하여 비교한다.
결과 저장: StringBuilder를 사용하여 결과를 한 번에 저장하고, 마지막에 출력한다.코드로 구현
package baekjoon.baekjoon_27;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// 백준 6996번 문제
public class Main979 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
int t = Integer.parseInt(br.readLine().trim());
for(int i = 0; i < t; i++) {
String line = br.readLine();
String[] words = line.split(" ");
String wordA = words[0];
String wordB = words[1];
// 알파벳 배열로 변환 후 정렬
char[] arrayA = wordA.toCharArray();
char[] arrayB = wordB.toCharArray();
Arrays.sort(arrayA);
Arrays.sort(arrayB);
// 정렬된 결과 비교
if(Arrays.equals(arrayA, arrayB)) {
sb.append(wordA).append(" & ").append(wordB).append(" are anagrams.\n");
} else {
sb.append(wordA).append(" & ").append(wordB).append(" are NOT anagrams.\n");
}
}
// 결과 출력
System.out.print(sb.toString());
br.close();
}
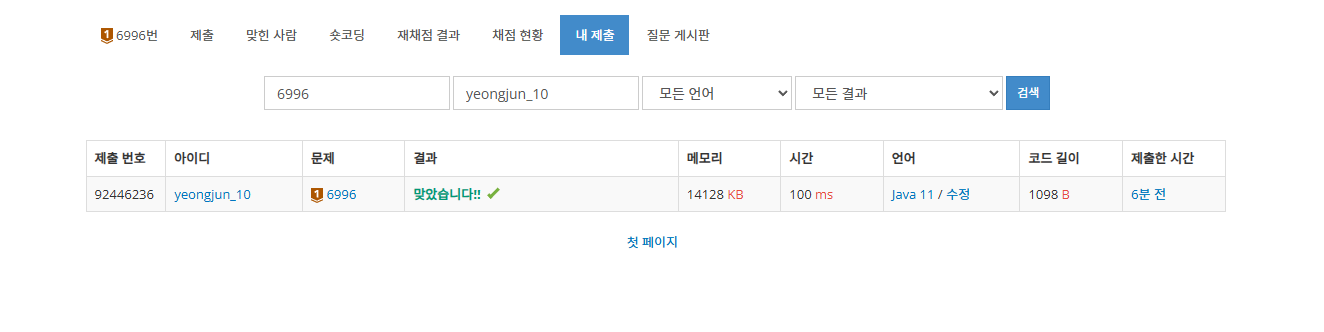
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer