
문제
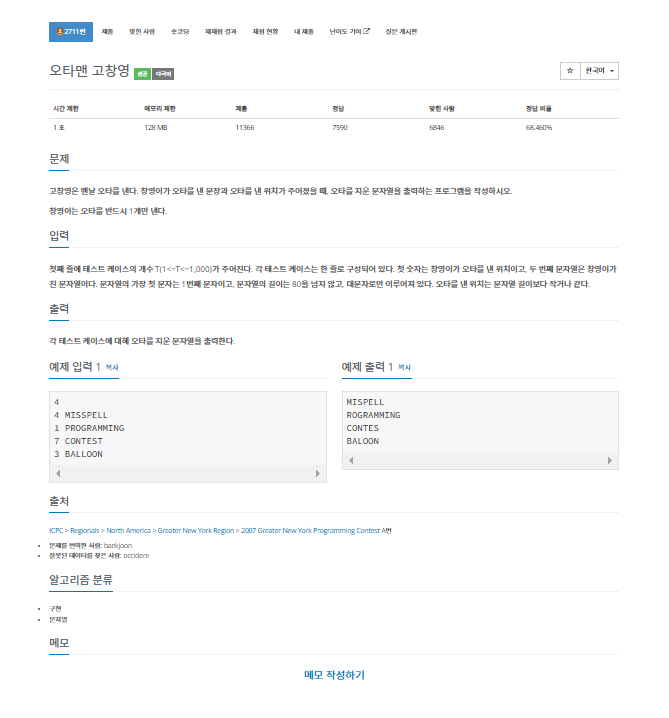
내가 생각했을때 문제에서 원하는부분
첫째 줄에 테스트 케이스의 개수 T(1<=T<=1,000)가 주어진다.
각 테스트 케이스는 한 줄로 구성되어 있다.
첫 숫자는 창영이가 오타를 낸 위치이고,
두 번째 문자열은 창영이가 친 문자열이다.
문자열의 가장 첫 문자는 1번째 문자이고,
문자열의 길이는 80을 넘지 않고,
대문자로만 이루어져 있다.
오타를 낸 위치는 문자열 길이보다 작거나 같다.
각 테스트 케이스에 대해 오타를 지운 문자열을 출력한다.내가 이 문제를 보고 생각해본 부분
BufferedReader를 사용하여 입력을 빠르게 읽어준다.
첫번째 줄에서 테스트 케이스의 개수를 읽는다.
오타제거
각 테스트 케이스에 대해 오타가 발생한 위치와 문자열을 읽는다.
위치는 1부터 시작하므로 0-based 인덱스로 변환하기 위해 -1을 한다.
substring 메서드를 사용하여 오타를 제거한 문자열을 생성한다.
모든 결과를 StringBuilder에 추가하고 마지막에 한번에 출력해준다.코드로 구현
package baekjoon.baekjoon_24;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
// 백준 2711번 문제
public class Main837 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
int T = Integer.parseInt(br.readLine());
for(int i = 0; i < T; i++) {
String line = br.readLine(); // 각 테스트 케이스 입력
String[] parts = line.split(" ");
int position = Integer.parseInt(parts[0]) - 1; // 1-based to 0-based index
String str = parts[1];
String corrected = str.substring(0, position) + str.substring(position + 1); // 오타를 지운 문자열 생성
sb.append(corrected).append("\n"); // 결과에 추가
}
System.out.print(sb.toString()); // 결과 출력
br.close();
}
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer