
문제
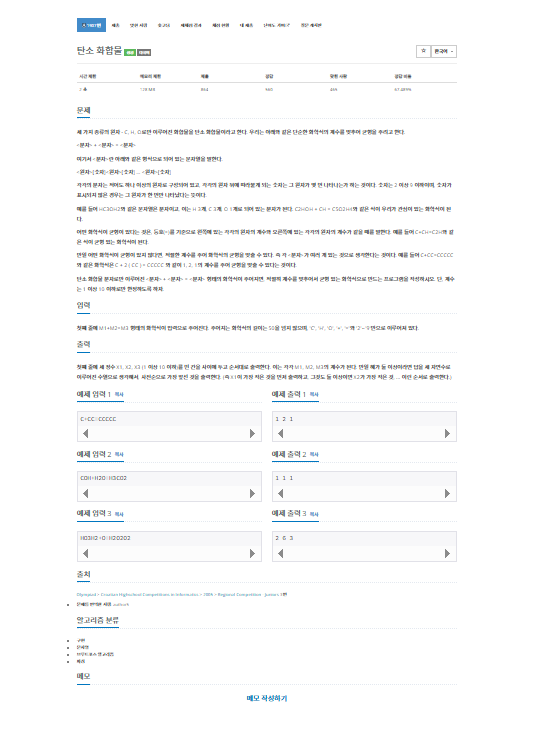
내가 생각했을때 문제에서 원하는부분
첫째 줄에 M1+M2=M3 형태의 화학식이 입력으로 주어진다.
주어지는 화학식의 길이는 50을 넘지 않으며, 'C', 'H', 'O', '+', '='와 '2'∼'9'만으로 이루어져 있다.
첫째 줄에 세 정수 X1, X2, X3 (1 이상 10 이하)를 빈 칸을 사이에 두고 순서대로 출력한다.
이는 각각 M1, M2, M3의 계수가 된다. 만일 해가 둘 이상이라면 답을 세 자연수로 이루어진 수열으로 생각해서, 사전순으로 가장 앞선 것을 출력한다. (즉 X1이 가장 작은 것을 먼저 출력하고, 그것도 둘 이상이면 X2가 가장 작은 것, ... 이런 순서로 출력한다.)내가 이 문제를 보고 생각해본 부분
parseMolecule(String molecule) 함수:
이 함수는 C3OH2처럼 문자와 숫자가 섞인 분자 문자열을 받아서, 그 안에 'C', 'H', 'O' 원자가 각각 몇 개씩 들어있는지 세어주는 역할을 한다.
결과는 int 배열로 반환하는데, [C 원자 개수, H 원자 개수, O 원자 개수] 순서로 담겨있다.
초기 설정: 'C', 'H', 'O' 각 원자의 개수를 세기 위해 HashMap을 하나 만든다.
처음에는 모두 0개로 설정해둔다.
문자열 순회:
분자 문자열을 왼쪽부터 한 글자씩 살펴보면서 원자와 그 개수를 파악한다.
원자 식별:
현재 보고 있는 문자가 'C', 'H', 'O' 중 하나라면, 이 문자가 어떤 원자인지 파악한다.
개수 파악:
일단 원자 뒤에 숫자가 안 붙어 있으면 기본적으로 1개라고 가정한다. (예: H는 H 1개)
만약 원자 바로 뒤에 숫자가 붙어있다면(예: C2에서 '2'), 이 숫자를 읽어서 해당 원자의 개수로 사용한다.
이때 Character.isDigit()으로 다음 글자가 숫자인지 확인하고, 해당 문자를 정수로 변환하는 특별한 방법('2' - '0' -> 2)을 쓴다.
숫자를 읽었으니 다음 글자로 넘어갈 때 이 숫자는 건너뛰어야겠죠? 그래서 인덱스 i를 추가로 증가시킨다.
개수 합산:
파악된 원자의 개수를 HashMap에 누적해서 저장한다.
결과 반환:
모든 분석이 끝나면, 최종적으로 계산된 'C', 'H', 'O'의 개수를 int 배열에 담아서 돌려준다.
main 함수:
입력받은 화학식을 분석하고, parseMolecule 함수를 활용해서 각 분자의 원자 개수를 알아낸 다음, 브루트포스(무차별 대입) 방식으로 정답 계수를 찾아 출력한다.
화학식 입력:
BufferedReader를 사용해서 C+CC=CCCCC와 같은 형태의 화학식을 읽어온다.
분자 분리:
입력받은 화학식 문자열을 "+"와 "=" 기호를 기준으로 M1, M2, M3 세 부분으로 나눈다.
input.split("[+=]") 메서드가 이 작업을 깔끔하게 처리해준다.
원자 개수 추출:
분리된 M1, M2, M3 문자열을 각각 parseMolecule 함수에 넘겨준다.
그러면 각 분자에 'C', 'H', 'O' 원자가 몇 개씩 있는지 배열 형태로 얻게 된다.
이걸 m1Counts, m2Counts, m3Counts 같은 변수에 저장한다.
계수 무차별 대입 (Brute-Force):
계수 X1, X2, X3가 각각 1부터 10까지라는 비교적 작은 범위 안에 있기 때문에, 컴퓨터는 모든 가능한 조합을 시도해 볼 수 있다.
그래서 X1, X2, X3에 대해 각각 1부터 10까지 반복하는 세 개의 중첩된 for 반복문을 사용한다.
화학적 균형 확인: 각 (X1, X2, X3) 조합에 대해서, 아래 세 가지 조건을 모두 만족하는지 확인한다.
cBalanced:
(M1의 C 개수 * X1) + (M2의 C 개수 * X2)가 (M3의 C 개수 * X3)와 두 값이 서로 같은지 확인하는 것이다.
hBalanced:
(M1의 H 개수 * X1) + (M2의 H 개수 * X2)가 (M3의 H 개수 * X3)와 두 값이 서로 같은지 확인하는 것이다.
oBalanced:
(M1의 O 개수 * X1) + (M2의 O 개수 * X2)가 (M3의 O 개수 * X3)와 두 값이 서로 같은지 확인하는 것이다.
정답 출력 및 종료:
만약 'C', 'H', 'O' 원자 개수가 모두 균형을 이룬다면 (cBalanced && hBalanced && oBalanced가 참이라면), X1, X2, X3는 문제의 조건을 만족하는 올바른 계수 조합이다.
이때 System.out.println()을 사용해서 찾은 X1, X2, X3를 출력한다.
그리고 매우 중요하게 return; 문으로 프로그램을 즉시 종료한다.
왜냐하면 for 반복문이 X1을 1부터, 그 다음 X2를 1부터, 그 다음 X3를 1부터 순서대로 증가시키기 때문에, 가장 먼저 찾아낸 답이 바로 "사전순으로 가장 앞서는" 정답이 되기 때문이다.
더 이상 다른 답을 찾아볼 필요가 없다.
자원 정리:
br.close()를 호출해서 사용했던 입력 스트림 자원을 깔끔하게 닫아준다.코드로 구현
package baekjoon.baekjoon_32;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
// 백준 1907번 문제
public class Main1280 {
// 각 원소의 개수를 세는 함수 (C, H, O 순서로 반환)
private static int[] parseMolecule(String molecule) {
Map<Character, Integer> counts = new HashMap<>();
counts.put('C', 0);
counts.put('H', 0);
counts.put('O', 0);
int i = 0;
while (i < molecule.length()) {
char atom = molecule.charAt(i);
int count = 1; // 숫자가 없으면 1개
if (i + 1 < molecule.length() && Character.isDigit(molecule.charAt(i + 1))) {
count = molecule.charAt(i + 1) - '0'; // 문자를 숫자로 변환
i++; // 숫자만큼 인덱스 이동
}
counts.put(atom, counts.get(atom) + count);
i++;
}
return new int[]{counts.get('C'), counts.get('H'), counts.get('O')};
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String input = br.readLine();
// 화학식을 M1, M2, M3로 분리
String[] parts = input.split("[+=]");
String m1Str = parts[0];
String m2Str = parts[1];
String m3Str = parts[2];
// 각 분자의 원소 개수를 파싱
int[] m1Counts = parseMolecule(m1Str);
int[] m2Counts = parseMolecule(m2Str);
int[] m3Counts = parseMolecule(m3Str);
// 계수 (X1, X2, X3)를 1부터 10까지 브루트포스 탐색
for (int x1 = 1; x1 <= 10; x1++) {
for (int x2 = 1; x2 <= 10; x2++) {
for (int x3 = 1; x3 <= 10; x3++) {
// C, H, O 원소별 개수 확인
boolean cBalanced = (m1Counts[0] * x1) + (m2Counts[0] * x2) == (m3Counts[0] * x3);
boolean hBalanced = (m1Counts[1] * x1) + (m2Counts[1] * x2) == (m3Counts[1] * x3);
boolean oBalanced = (m1Counts[2] * x1) + (m2Counts[2] * x2) == (m3Counts[2] * x3);
// 모든 원소가 균형을 이뤘다면 정답 출력 후 종료
if (cBalanced && hBalanced && oBalanced) {
System.out.println(x1 + " " + x2 + " " + x3);
br.close();
return; // 첫 번째로 찾은 답이 사전순으로 가장 앞선 답
}
}
}
}
br.close();
}
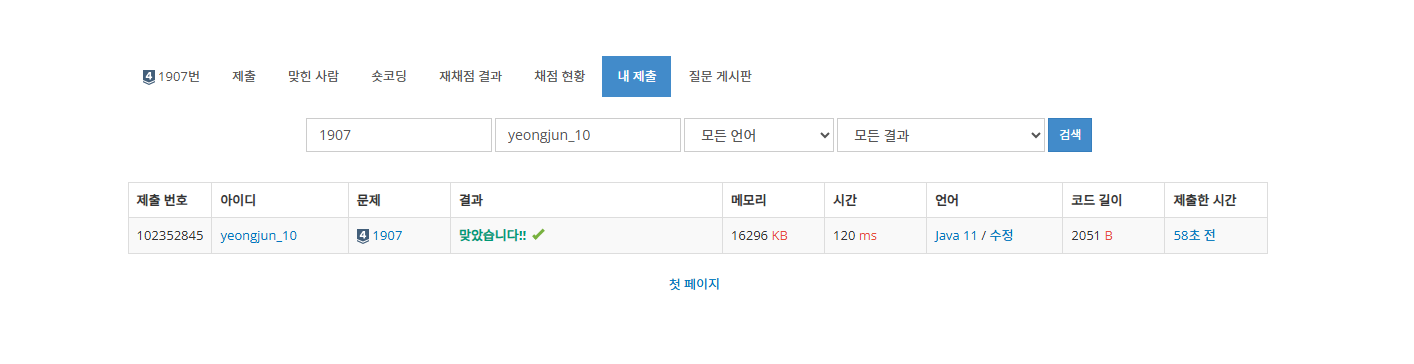
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer