
문제
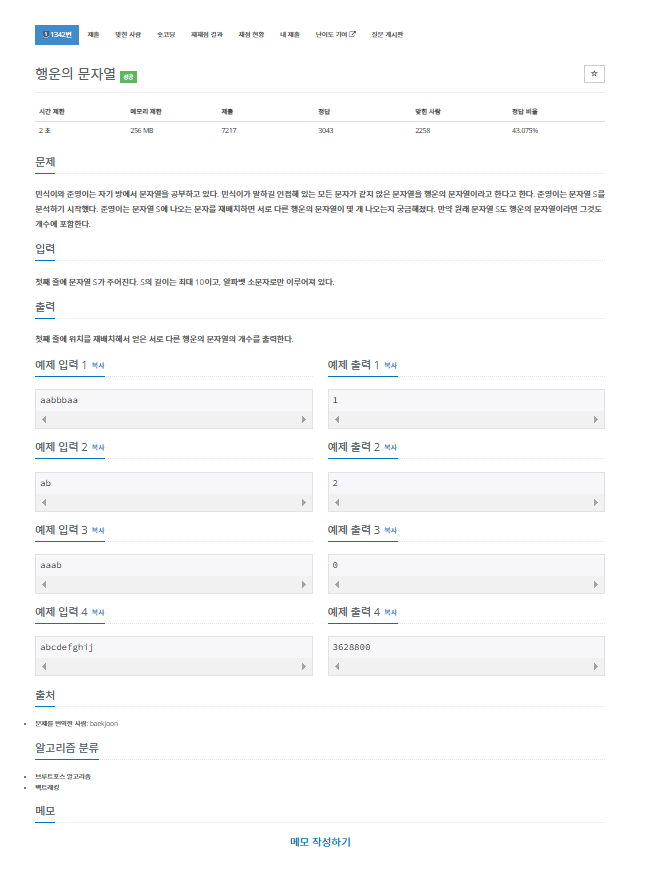
내가 생각했을때 문제에서 원하는부분
첫째 줄에 문자열 S가 주어진다.
S의 길이는 최대 10이고, 알파벳 소문자로만 이루어져 있다.
첫째 줄에 위치를 재배치해서 얻은 서로 다른 행운의 문자열의 개수를 출력한다.내가 이 문제를 보고 생각해본 부분
전역 변수 선언:
alphabet: 알파벳 문자의 빈도를 저장하는 배열이다.
인덱스 0부터 25까지는 'a'부터 'z'까지의 문자를 저장하고, 인덱스 26은 사용되지 않는다.
count: 행운의 문자열의 개수를 세기 위한 변수이다.
length: 입력 문자열의 길이를 저장한다.
BufferedReader를 사용하여 입력 문자열을 받는다.
length에 문자열의 길이를 저장한다.
for 루프를 통해 각 문자의 빈도를 alphabet 배열에 저장한다.
예를 들어, 'a'는 alphabet[0], 'b'는 alphabet[1]에 저장된다.
dfs(0, ' ')를 호출하여 깊이 우선 탐색(DFS)을 시작한다.
여기서 0은 현재 인덱스, ' '는 이전 문자를 의미한다.
DFS가 끝난 후, count를 출력한다.
DFS 메서드:
index: 현재 문자열의 인덱스이다.
pre: 이전에 추가한 문자이다.
if(index == length): 현재 인덱스가 문자열의 길이에 도달하면 (즉, 모든 문자를 사용한 경우) count를 증가시키고 반환한다.
for 루프를 통해 알파벳 배열의 각 문자에 대해 반복한다.
if(alphabet[i] == 0): 해당 문자가 더 이상 사용되지 않으면 건너뛴니다.
if(pre != (char) (i + 'a')): 이전 문자와 같지 않은 경우에만 해당 문자를 추가한다.
alphabet[i]--: 해당 문자를 사용하고 빈도를 감소시킨다.
dfs(index + 1, (char)(i + 'a')): 다음 인덱스로 이동하여 재귀 호출한다.
alphabet[i]++: 재귀 호출 후에 문자를 복원한다.코드로 구현
package baekjoon.baekjoon_25;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
// 백준 1342번 문제
public class Main874 {
static int[] alphabet = new int[27];
static int count;
static int length;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String str = br.readLine();
length = str.length();
for(int i = 0; i < str.length(); i++) {
alphabet[str.charAt(i) - 'a']++;
}
dfs(0,' ');
System.out.println(count);
br.close();
}
static void dfs(int index, char pre) {
if(index == length) {
count++;
return;
}
for(int i = 0; i < 27; i++) {
if(alphabet[i] == 0) {
continue;
}
if(pre != (char) (i + 'a')) {
alphabet[i]--;
dfs(index + 1, (char)(i + 'a'));
alphabet[i]++;
}
}
}
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer