프로그래머스 가운데 글자 가져오기 콜라 문제 (99클럽 코딩테스트 15일차 TIL)
0

목표
오늘 문제중에 한 문제는 설명이 짧고 한 문제는 설명이 길다. 설명이 긴 문제를 자주 풀어서 긴 문제가 나와도 겁내지 않고 바로 풀수있게 만들기 위해서이다.
문제
내가 생각했을때 문제에서 원하는부분
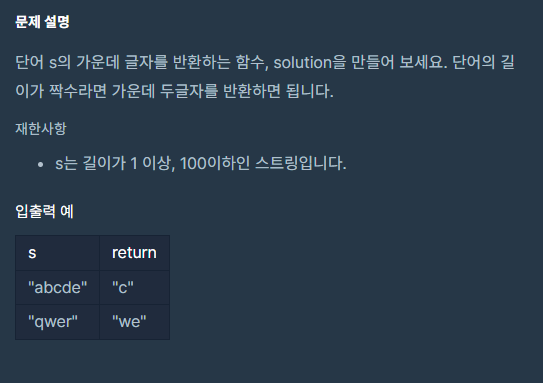
단어 s의 가운데 글자를 반환하는 함수
단어의 길이가 짝수라면 가운데 두글자를 반환하면 된다.내가 이 문제를 보고 생각해본 부분
주어진 단어 s의 길이를 확인한다.
단어 s의 길이가 홀수인 경우에는 가운데 글자를 반환한다.
예를 들어 "abcde"의 가운데 글자는 c 이다.
단어 s의 길이가 짝수인 경우에는 가운데 두 글자를 반환한다.
예를 들어 "qwer"의 가운데 글자는 we 이다.
반환할 문자열의 길이는 최대 2글자이다.
s의 길이는 1 이상 100 이하의 정수이다.
이 문제는 주어진 단어의 가운데 글자 혹은 가운데 두 글자를 반환하는 함수를 구현하는 문제이다.
길이에 따라 반환할 문자열이 달라진다.코드로 구현
class Solution {
public String solution(String s) {
String answer = "";
int length = s.length();
if(length % 2 == 0) {
answer = s.substring(length / 2 - 1, length / 2 + 1);
} else {
answer = s.substring(length / 2, length / 2 + 1);
}
return answer;
}
}s의 길이를 length 변수에 저장
짝수/홀수를 판단할 때 length 변수를 사용
substring() 메소드를 사용해 가운데 글자/두 글자 추출
answer 변수에 추출한 문자열 저장시간복잡도는 O(1)이다.
장점
코드가 간결하고 이해하기 쉽다.
주어진 조건을 정확하게 구현했다.
시간 복잡도가 O(1)로 효율적이다.
단점
입력 값에 대한 validation 체크가 없다.
예를 들어, s의 길이가 1 미만 또는 100 초과인 경우 처리 X
추후 요구사항 변경시 확장성이 떨어질 수 있다.
중간 N개의 문자 반환하는 등의 추가 기능 어려움.

내가 생각했을때 문제에서 원하는부분
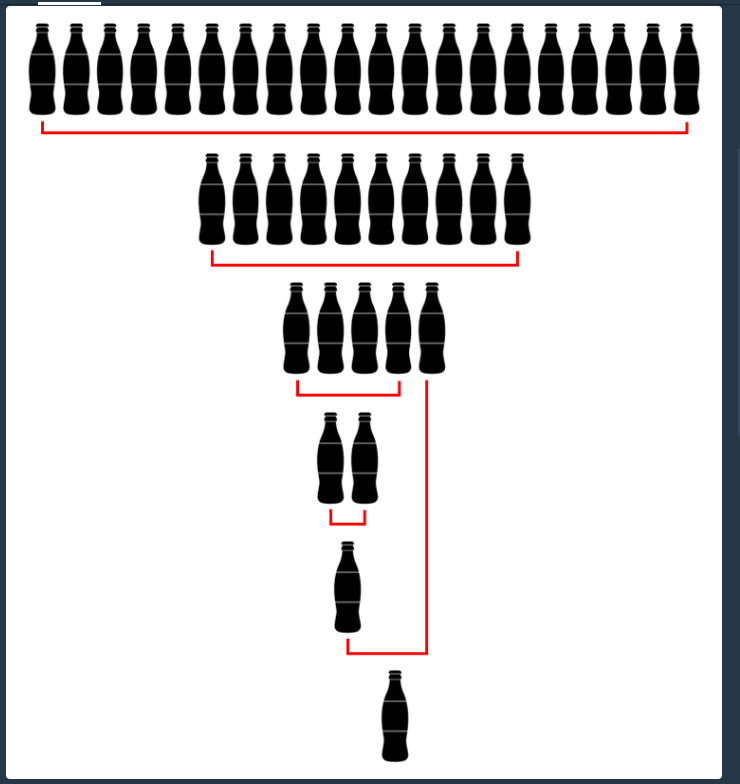
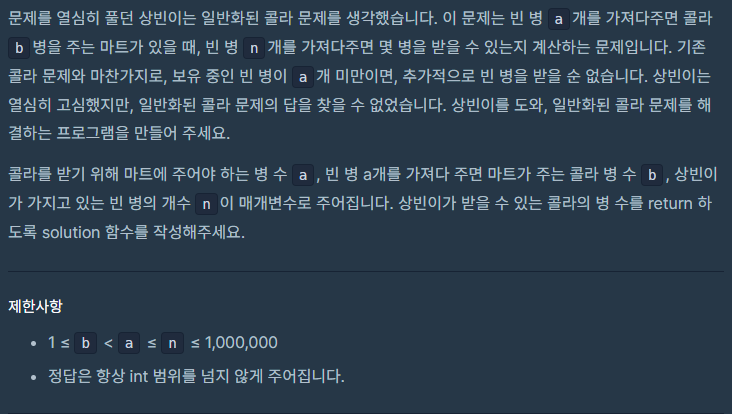
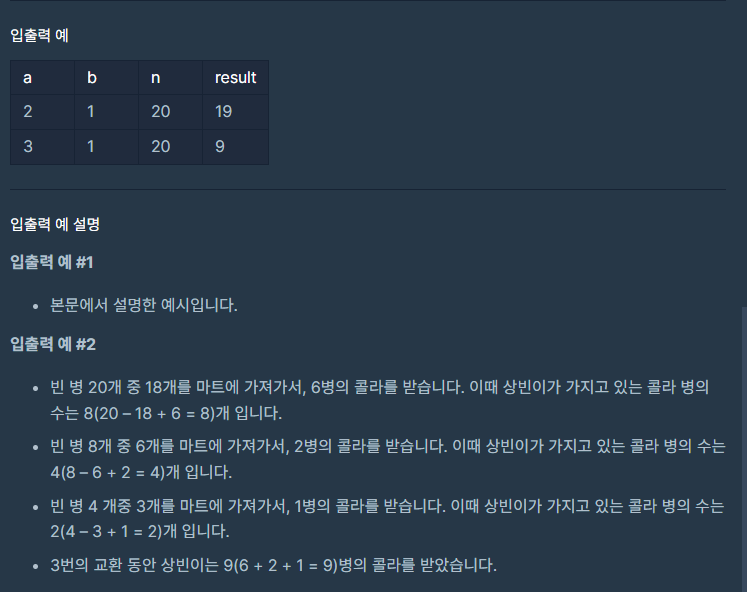
마트에서 빈 병 a개를 가져가면 콜라 b병을 줍니다.
상빈이가 가진 빈 병의 수 n과 마트의 규칙 a, b가 주어졌을 때,
상빈이가 최대로 받을 수 있는 콜라 병의 수를 계산하는 프로그램을 작성하라는 문제이다.내가 이 문제를 보고 생각해본 부분
입력으로 a, b, n이 들어오면 최대한으로 콜라를 교환할 수 있는 방법을 찾아 그 결과로
얻을 수 있는 콜라 병의 총수를 return 한다.코드로 구현
class Solution {
public int solution(int a, int b, int n) {
int answer = 0;
int bottle = n;
while(bottle >= a) {
int exchange = bottle / a * b;
answer += exchange;
bottle = bottle % a + exchange;
}
System.out.println(answer);
return answer;
}
}bottle 변수에 현재 가진 빈 병 수를 저장
bottle이 a 보다 크면 계속 반복
교환 가능한 만큼 콜라를 교환
얻은 콜라 수 누적
남은 빈 병 수 업데이트
반복문 탈출 후 누적된 콜라 수 리턴시간복잡도는 O(N)이다.
장점
입력 데이터의 크기가 커져도 효율적으로 동작한다.
선형 시간복잡도이기 때문에 입력값 증가에 따른 성능 저하가 적다.
코드가 단순하고 이해하기 쉽다.
단점
데이터 크기가 매우 커지면(예: 1억 개) 성능이 떨어질 수 있다.
빅오 표기법은 데이터 크기에 따른 경향만 보여주기 때문이다.
입력 데이터를 한 번 순회할 때마다 교환 로직을 반복하므로 일정 수준의 오버헤드가 발생한다.
마무리
오늘도 두 문제를 풀면서 여러가지로 생각할 수 있는 계기가 된것같다. 문제 풀면서 어렵게 느껴졌지만 조금씩 익숙해지는것같다. 자연스럽게 먼저 시간복잡도라던지 문제를 어떻게 풀어야할지 등등을 조금더 생각해보는것같다.

Junior backend developer