File and File System
File
명명되어 저장된 관련 정보 - A named collection of related information
- 일반적으로 비휘발성의 보조기억장치(Disk...)에 저장
- 운영체제는 다양한 저장 장치를 관리하기 위해서 file이라는 논리적 단위를 사용
File Operation
- open - close : metadata를 memory에 올려(내려)놓는 과정
- create - delete
- read - write
- reposition(lseek) : file 접근 중인 위치 수정
File Attribute (metadata)
파일 자체 내용이 아니라, 파일 관리를 위한 각종 정보
File System
OS에서 파일을 관리하는 부분
파일 및 파일의 metadate, 디렉토리 정보 관리
Directory and Logical Disk
Directory
파일의 메타데이터 중 일부를 보관하고 있는(내용으로 갖는) 일종의 특별한 파일
Directory Operation
- file search, create a file, delete a file
- list a directory, rename a file, traverse the file system.
Partition (Logical Disk)
- OS가 바라보는 Disk
- 하나의 디스크 안에 여러 파티션을 두는게 일반적
- 여러 개의 물리적 디스크를 합쳐 하나의 파티션으로 구성하기도 함
- (물리적) 디스크를 파티션으로 구성한 뒤 각 파티션에 file system 깔거나 swapping 등 다른 용도로 사용 가능
open()
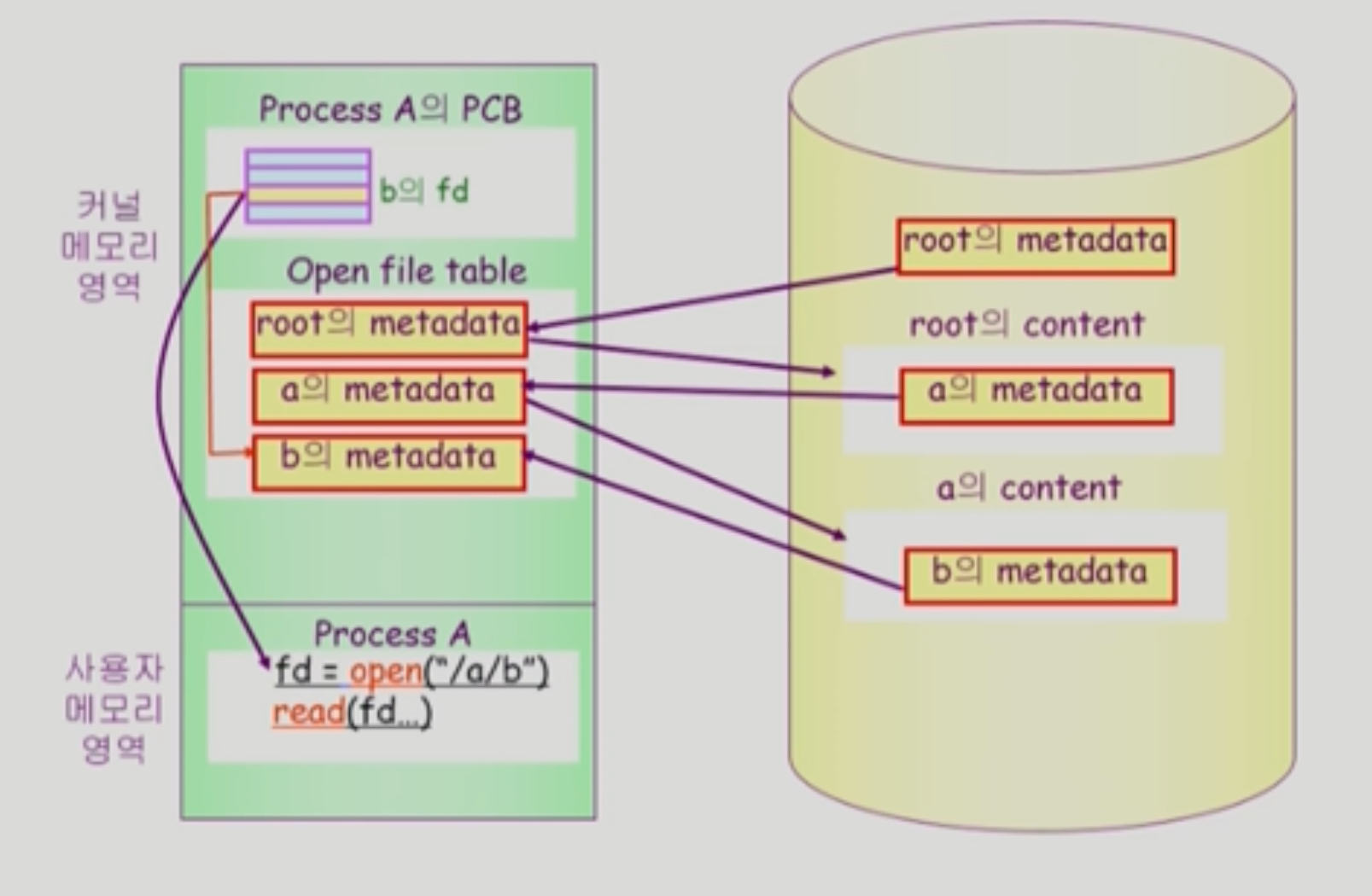
open("/a/b/c")
- root directory 부터 차근차근 탐색
- root directory "/" open 하여 file "a" 위치 획득
- file "a" open 하여 file "b" 위치 획득
- file "b" open 하여 file "c" 위치 획득
- file "c" open
- 매번 read 할 때마다 Disk 접근해서 file 위치를 root부터 찾는 건 몹시 비효율적이다.
- fd = open("/a/b") 에서 b의 path를 return하여 PCB에 기록해둔다.
- 이후 read, write 에서는 fd(file descriptor)를 통해 더 빠르게 찾을 수 있다.
- b의 content는 커널 메모리에 복사해두었다가, 이를 사용자 메모리로 전달해준다.
- 이후 다시 b의 content를 참조하면 사용자 메모리에 저장된 값을 사용한다. (Buffer-Caching)
File Protection
File Protection
파일은 여러 프로그램이 사용 가능.
각 파일에 대해 누구에게 어떤 유형의 접근을 허락할 것인가?Access Control Matrix
행렬의 형태로 파일에 대한 프로그램들의 권한 작성
Overhead가 몹시 큼.
- Access Control List : 파일 별로 누구에게 어떤 접근 권한이 있는지 표시
- Capability List : 사용자별로 자신이 접근 권한을 가진 파일, 권한 표시
Grouping
전체 User를 owner, group, public 세 그룹으로 구분
각 파일에 대해 세 그룹의 접근 권한을 3비트 씩 표현
일반적 사용 방법.
- 예시) rwx r-- r--
Password
파일마다 password를 두는 방법
접근 권한 별로 password 따로 설정해야 함 : 암기 문제, 관리 문제 발생
Access Methods
시스템 제공하는 파일 정보의 접근 방식.
순차 접근 (Sequential Access)
- 카세트 테이프 사용 방식처럼 접근
- A 방문 후 C 방문 희망 시 B를 무조건 방문해야 함.
직접 접근 (Direct Access, Random Access)
- LP 레코드 판과 같이 접근
- File 구성 레코드를 임의의 순서로 접근 가능
Allocation of File Data in Disk
Disk 상에 File Data 어떻게 저장할까?
이에 따라서 접근 방식에도 영향이 간다.Contiguous Allocation
하나의 파일이 디스크 상에 연속해서 저장되는 방식
파일의 크기에 따라 디스크 내 연속된 block에 저장
- 장점
- 빠른 file I/O (연속되어 존재하므로 한 번의 seek면 충분)
- Process의 Swapping Area용 (영속 공간 X, 임시 공간 O)으로 적합 (메모리는 다소 낭비해도 빠른 접근 가능)
- Direct(random) Access 가능
- 단점
- 외부 조각이 발생함 (파일 크기가 균일하지 않으므로)
- File Grow가 어려움
- 파일 크기가 커질 수도 있는데, 파일의 크기를 키우는 일이 어렵다.
- 파일이 커질 것을 대비하여 미리 빈 공간을 확보해두어야 할 수도 -> 낭비(내부 조각) 발생
Linked Allocation
Contiguous의 hole 발생 문제
비어있는 공간이면 할당하고, 다음 file block 위치를 가리키도록 Link
- 장점
- 외부 조각 발생 안함
- 단점
- 직접 접근이 불가능
- 한 block 참조 위해서는 이전 block 모두 check 필요
- Reliability 문제 발생
- 중간 sector 고장나면 이후 block에 접근할 방법이 없음. 데이터 유실 발생
- Pointer를 위한 공간이 block의 일부가 되어 공간 효율성 떨어짐
- 다음 위치를 가르키는 pointer를 위해 공간 할당 필요
- 변형 : File-Allocation Table(FAT) 시스템
Indexed Allocation
직접 접근이 가능하도록.
directory 에 파일이 산재된 block index 정보를 담은 block index를 가르키도록.
index block만 살펴보면, 중간 block에 접근 가능.
- 장점
- 외부 조각 발생하지 않음.
- 직접 접근 가능
- 단점
- 작은 파일의 경우 공간 낭비 (index block 무조건 필요)
- Too Large file은 하나의 index block으로 index 저장이 불가.
- 해결 방안
- linked scheme (index block 마지막은 또 다른 index block 가르키도록)
- multi-level index
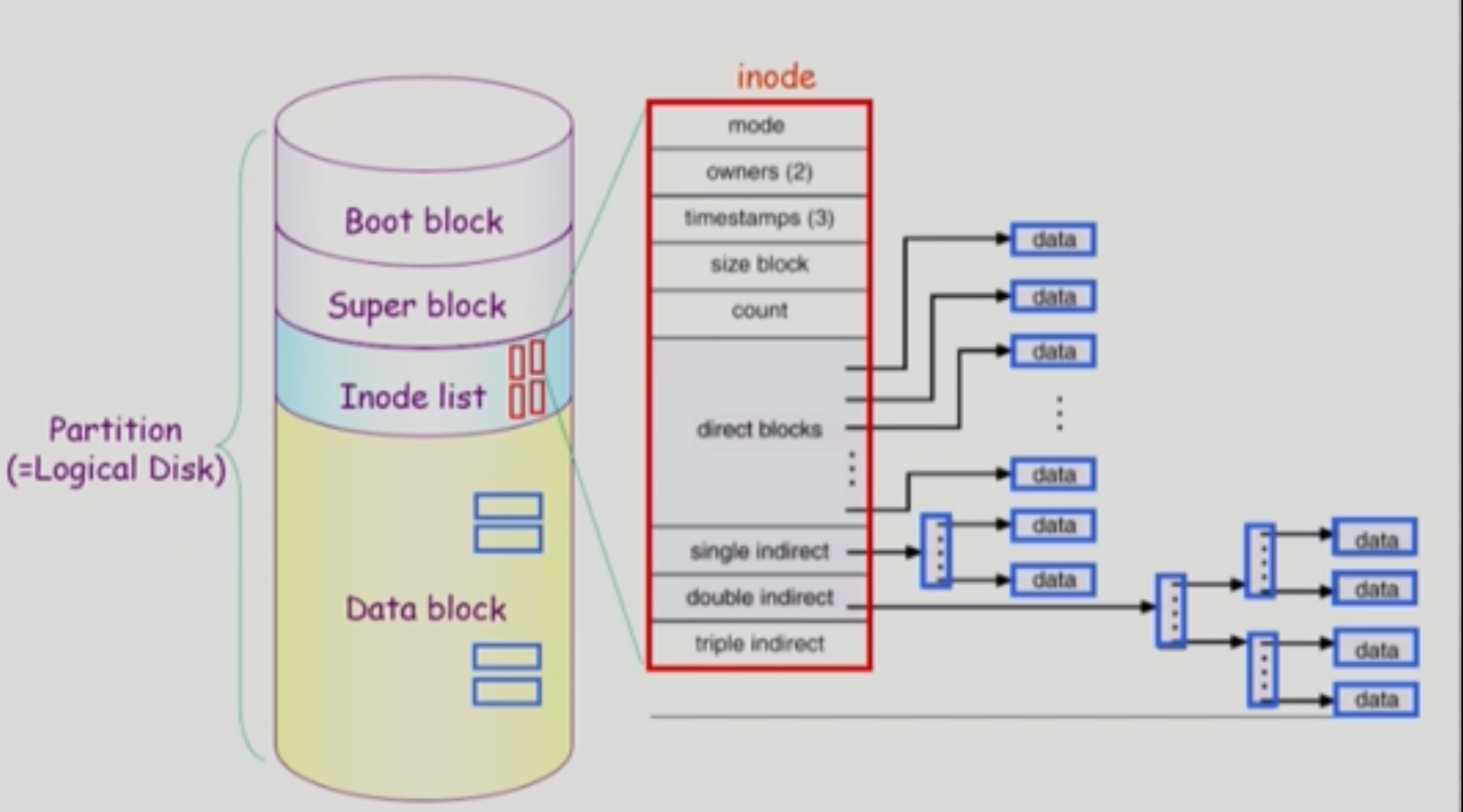
UNIX File System Structure
Partition (Logical Dist)의 구성
- 네 부분 (Boot Block, Super Block, Inode list, Data Block)으로 구성
- Boot Block
- 모든 File System 맨 앞에 존재하도록 규약
- Booting 에 필요한 정보 (Bootstrap Loader)
- Super Block
- 파일 시스템에 관한 총체적 정보 소유
- 어디가 empty? 인지, 어디까지 Inode?, Data block
- Inode List
- 파일의 메타 데이터 보관.
- Directory에도 보관하지만 메타데이터 일부분만 보관
- Inode List에 file의 메타데이터 보관
- file의 이름은 directory 보관. 나머지는 Inode list 에서 보관
- 작은 파일은 direct blocks, 큰 파일은 single(double) indirect로 보관.
- Data block
- 파일의 실제 데이터 보관.
FAT File System
Boot block + FAT + Root directory + Data Block 으로 구성
- File의 metadata 일부 (위치 정보)를 FAT에 보관.
- 나머지 metadata는 Data block이 보관.
- File의 첫 위치는 Data block이 제공, 나머지 연결 정보는 FAT에서 보관.
- Data block에서는 다음 인덱스를 가리키는 byte를 표시하지 않아도 됨 (Pointer 위한 공간을 block에서 제거)
- 직접 접근 가능 (FAT 에서 연결 정보 확인하고 바로 접근)
- FAT은 다음 위치 연결 정보를 보관
- 중요하므로 위치 연결 정보를 여러 copy로 저장
- Reliability 개선
Free Space Management
비어 있는 block 어떻게 관리함?
bit map / bit vector
각 Block 별로 bit 두어서 비어있는지 여부를 binary로 표시
- Bit map은 부가적인 공간을 필요로 함
- 연속적인 빈 block 탐색에 효과적
Linked List
모든 free block을 연결해놓음
- 연속적 free block 탐색 쉽지 않음
- 공간의 낭비 없다.
Grouping
Linked List 방법의 변형
Indexed Allocation 처럼 빈 block 활용
- 첫 번째 free block이 n 개의 포인터를 가짐
- n - 1 개의 pointer는 free data block 가리킴
- 마지막 pointer는 다시 N 개의 free data block을 가리키는 free block을 가리킨다.
Counting
연속적 free block 탐색에 효과적
first free block # + 연속적 free block 수를 같이 저장.
Directory Implementation
디렉토리 구현 방법
디렉토리란?
디렉토리 아래 file의 metadata를 관리하는 file
Linear List
- <file name, file metadata>의 list
- 구현이 간단하다.
- 디렉토리 내 특정 파일이 있는지 찾기 위해서는 linear search 필요 (time-consuming)
Hash Table
- Linear List + Hashing
- Hash table은 file name을 이 파일의 linear list의 위치로 변환.
- search time 없음.
- Collision 발생 가능 (Hash Function의 문제)
File의 metadata 보관 위치
- 디렉토리 내에 직접 보관
- 디렉토리에는 포인터를 두고 다른 곳에 보관 (inode, FAT)
Long file name의 지원
- <file name, file metadata>의 list에서 각 entry는 일반적으로 고정 크기
- file name이 고정 크기의 entry 크기보다 길어지는 경우 entry 마지막 부분에 이름의 뒷부분이 위치한 곳에 포인터를 두는 경우.
- 이름의 나머지 부분은 동일한 directory file 일부에 존재
VFS and NFS
VFS (Virtual File System)
서로 다른 다양한 file system에 대해 동일한 system call interface (API)를 통해 접근할 수 있도록 해주는 OS의 layer
NFS (Network File System)
분산 시스템에서는 네트워크를 통해 파일이 공유될 수 있음
NFS는 분산 환경에서의 대표적인 파일 공유 방법
local이 아닌 network로 원격에 존재하는 disk 접근
clinent / server 딴에 각각 NFS module 필요
Page Cache and Buffer Cache
Page cache
Virtual Memory의 paging system에서 사용하는 page frame을 caching의 관점에서 설명하는 용어
(backing store 보다 빠르다.)
Memory Mapped I/O를 쓰는 경우 file I/O에서도 page cache 사용
Replacement Algorithm : LRU, LFU X, clockwise OMemory Mapped I/O
file의 일부를 virtual memory에 mapping
이후 mapping 영역에 대한 연산은 파일의 입출력 수행Buffer Cache
파일 시스템을 통한 I/O 연산은 메모리의 특정 영역인 buffer cache 사용
File 사용의 locality 활용 (한 번 읽어온 block 후속 요청 시 buffer cache에서)
OS의 kernel memory에 data를 copy 해두기 때문에
모든 프로세스가 공용으로 사용
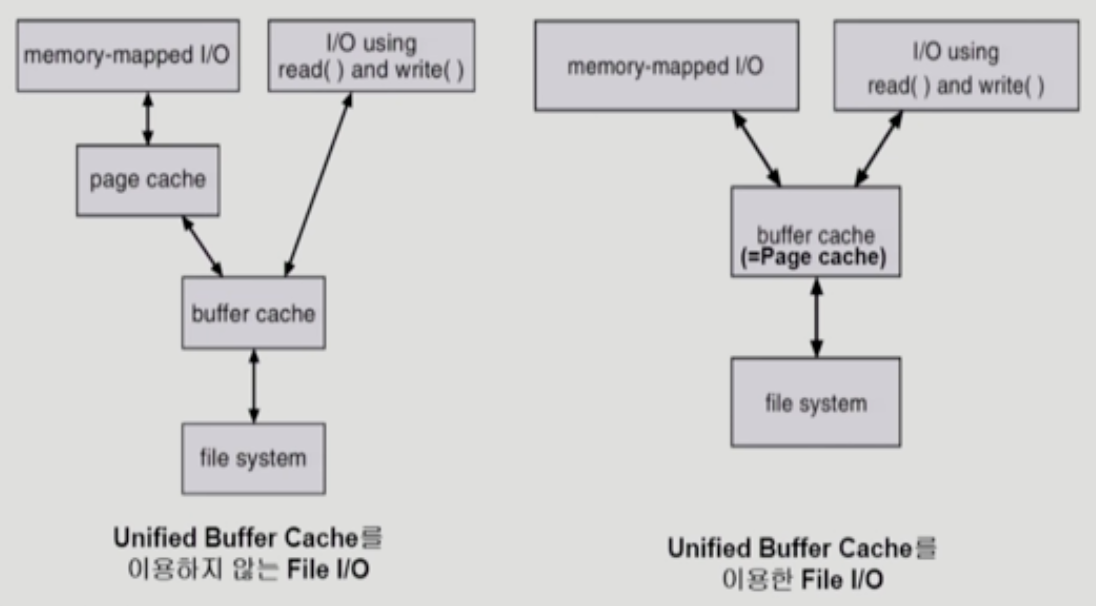
Replacement Algorithm : LRU, LFU OUnified Buffer Cache
Buffer Cache를 page 단위로 관리
Unified Buffer Cache를 사용하지 않는 I/O
- I/O using read() and write()
- file system - buffer cache 에서 사용자 프로그램으로 copy
- 이후 같은 내용 참조 시 buffer cache 참조. OS 도움 필요.
- memory-mapped I/O
- Disk에서 page cache로 가져와 사용
- 이후 같은 내용 참조 시 page cache 참조. OS 도움 필요 없음.
Unified Buffer Cache를 사용하는 I/O
buffer cache를 따로 할당하지 않고 필요에 따라 프로그램 주소 영역 할당해서 cache로 사용
Disk I/O 수행 후 사용자 프로그램의 주소영역에 page cache mapping
buffer cache가 별도로 존재하지 않음.