26A21b
1,000노드 규모의 대규모 인프라에서 Cilium Native Mode와 BGP, ECMP를 조합해 사용하신다면, 네트워크 스택의 복잡도가 상당히 높을 것으로 예상됩니다. 특히 Asymmetric Routing(비대칭 라우팅)이나 ECMP Hashing 불일치가 간헐적 장애의 주범일 가능성이 큽니다.
요청하신 대로 수신 측(Receiver) 관점에서 패킷이 NIC을 거쳐 커널의 tcp_check_req에서 드랍되기까지의 구조와 주요 지점을 짚어드리겠습니다.
1. 수신측 패킷 처리 구조 (NIC to Kernel TCP)
Native Routing 환경에서는 캡슐화(VXLAN) 과정이 없기 때문에 패킷이 표준 리눅스 네트워킹 스택을 더 깊게 활용합니다.
① 하드웨어 레벨: NIC & Driver
- RSS (Receive Side Scaling): 패킷이 들어오면 NIC 하드웨어가 5-tuple 해싱을 통해 특정 RX 큐에 패킷을 할당합니다. ECMP 환경에서는 스위치단에서 이미 해싱되어 들어오지만, 본딩(Bonding)된 NIC 내부에서도 어떤 슬레이브로 들어오느냐가 결정됩니다.
- SoftIRQ (NAPI): 커널이 CPU를 할당하여 RX 큐에서 패킷을 꺼내
sk_buff(skb) 구조체로 만듭니다.
② Cilium & eBPF 계층 (Host Routing)
- XDP/tc BPF: Cilium은
tc(traffic control) 훅에 eBPF 프로그램을 붙여 패킷을 처리합니다. Native 모드이므로 BGP로 전파된 라우팅 테이블을 보고 패킷이 로컬 포드용인지, 다른 노드로 포워딩할지 결정합니다. - Connection Tracking (CT): Cilium은 자체 BPF CT 테이블을 관리합니다. 여기서 상태가 어긋나면 커널 스택으로 넘기기 전에 드랍되는데, 사용자님의 경우 Cilium Monitor에 안 찍히므로 이 단계는 통과한 것입니다.
③ IP Stack & Netfilter
ip_rcv&nf_hook: 패킷이 커널 네트워킹 스택으로 진입합니다.iptables의 PREROUTING 훅이 여기서 실행됩니다.fib_validate_source(중요 - RP Filter): BGP+ECMP 환경에서 가장 위험한 구간입니다. 패킷이 들어온 인터페이스가 커널 라우팅 테이블상 "해당 소스 IP로 나갈 때 사용하는 인터페이스"와 다르면 비대칭 라우팅으로 간주하고 드랍합니다.
④ TCP Stack: tcp_v4_rcv -> tcp_check_req
tcp_v4_rcv: 패킷의 목적지가 로컬 소켓임을 확인하고 TCP 프로토콜 프로세서로 넘깁니다.tcp_check_req(드랍 지점): TCP 3-way handshake의 마지막ACK를 검증하는 핵심 함수입니다.SYN을 받았을 때 생성된request_sock(Mini-socket)과 들어온ACK를 대조합니다.
2. 왜 tcp_check_req에서 드랍될까? (전문가적 진단)
Native Mode, BGP, ECMP 환경을 고려할 때 가장 유력한 시나리오는 다음과 같습니다.
시나리오 A: ECMP에 의한 비대칭 라우팅 (Asymmetric Routing)
- 현상: 클라이언트가 보낸
SYN은 노드 A로 들어왔는데, 마지막ACK는 ECMP 경로 최적화나 스위치의 해싱 변경으로 인해 노드 B로 들어오는 경우입니다. - 결과: 노드 B는 해당 세션에 대한
request_sock정보가 없으므로 "듣도 보도 못한 ACK"라 판단하고tcp_check_req에서 드랍합니다. Clustermesh를 사용 중이라면 노드 간 라우팅 경로가 꼬일 확률이 더 높아집니다.
시나리오 B: Request Sock 타임아웃
- 현상: 서버가
SYN-ACK를 보냈으나, 네트워크 지연으로 클라이언트의ACK가 서버의TCP_TIMEOUT_INIT내에 도착하지 못한 경우입니다. - 결과: 서버 커널은 이미
request_sock을 해제(GC)했고, 뒤늦게 온ACK는 매칭되는 정보가 없어 드랍됩니다.
시나리오 C: SYN Cookie 오작동
- 현상: BGP를 통한 대규모 트래픽 유입으로 노드의
Accept Queue가 순간적으로 차오르면SYN Cookie가 발행됩니다. - 결과: 클라이언트가 보낸
ACK에 포함된 쿠키 값이 커널의 현재 계산값과 미세하게 어긋나면 검증에 실패합니다.
3. 플랫폼 엔지니어를 위한 심화 디버깅 가이드
현재 상황에서 "범인"을 검거하기 위해 다음 순서로 확인을 권장합니다.
-
비대칭 라우팅 확인 (가장 의심됨):
- 드랍이 발생하는 노드에서
sysctl net.ipv4.conf.all.rp_filter값을 확인하십시오. - BGP 환경이라면
2 (Loose)모드로 설정되어 있어야 비대칭 경로를 허용합니다. 만약1 (Strict)라면 즉시 드랍 사유가 됩니다.
- 드랍이 발생하는 노드에서
-
nstat를 통한 커널 통계 분석:# 드랍 발생 시점 전후로 카운트 변화 관찰 nstat -az | grep -E 'TcpExtListenDrops|TcpExtTCPMinisocksDrop|TcpExtTCPACKSkipped'TcpExtListenDrops가 올라간다면 큐 부족 문제입니다.TcpExtTCPMinisocksDrop이 올라간다면request_sock단계에서의 상태 불일치(비대칭 라우팅 등)입니다.
-
Cilium BGP 경로 안정성:
- BGP 피어링이 간헐적으로 떨리거나(Flapping), ECMP 경로가 재계산되는지 스위치 로그와 함께 확인이 필요합니다.
결론적으로 제 제안은 이렇습니다.
pwru가 드랍을 잡았다는 것은 패킷이 물리적으로는 도착했다는 증거입니다. 하지만 tcpdump가 못 잡는 이유는 보통 rp_filter에 의한 초기 드랍이거나 본딩 인터페이스의 캡처 지점 문제입니다. 우선 노드의 rp_filter 설정을 2로 바꾸어 보시고, 현상이 해결되는지 확인하는 것이 가장 빠른 길입니다.
추가로 nstat 결과에서 특정 카운터가 유독 높게 나온다면 공유해 주세요. 바로 다음 단계를 짚어드리겠습니다.
===
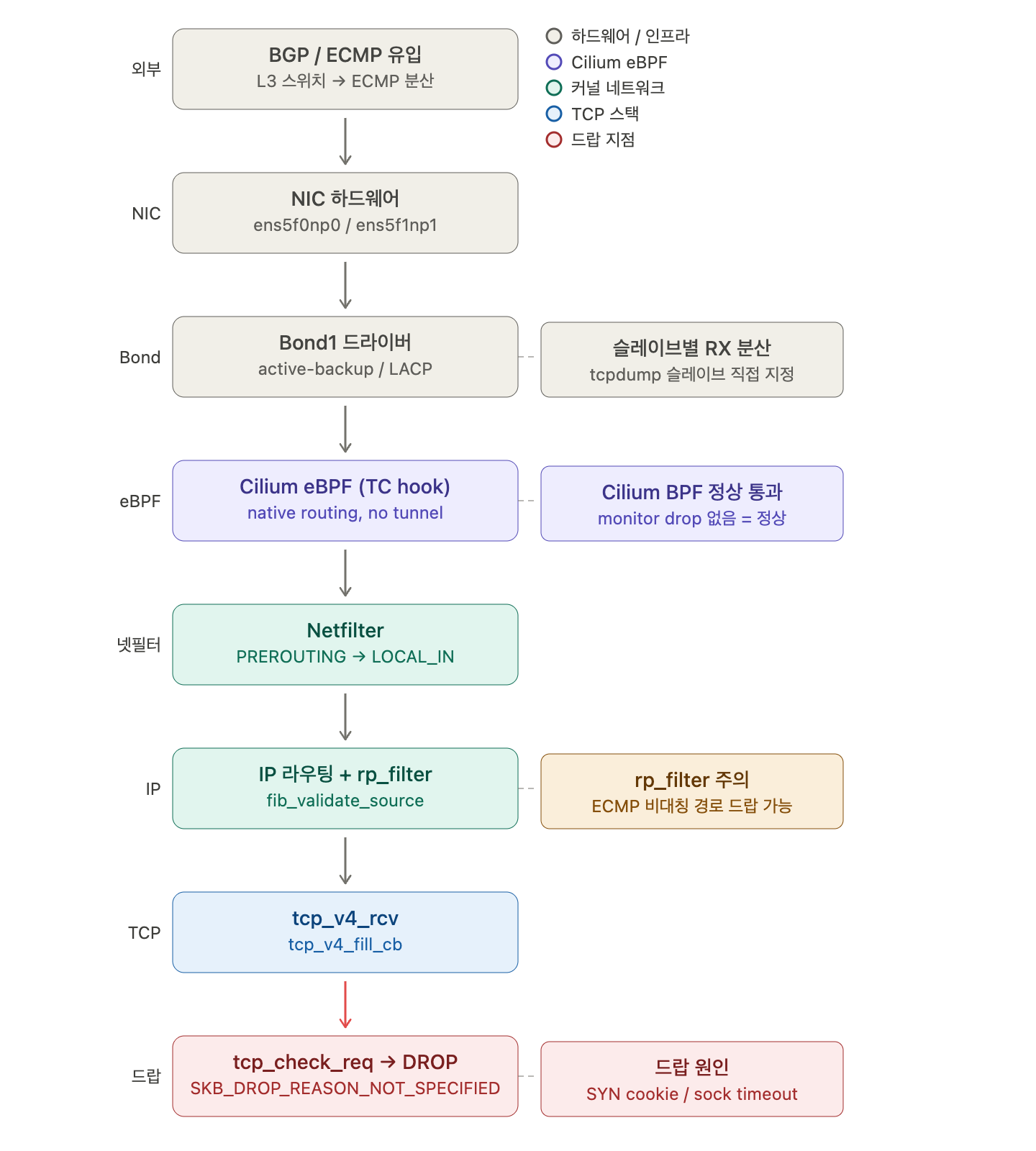
각 레이어를 클릭하면 세부 질문을 바로 이어서 보낼 수 있도록 인터랙티브 다이어그램으로 만들었습니다.각 박스를 클릭하면 해당 레이어에 대한 심층 질문으로 바로 이어집니다. 이제 각 레이어별 구조를 설명드리겠습니다.
1. BGP / ECMP 유입 — 외부 경로 결정
ClusterMesh + BGP 환경에서는 각 노드가 자신의 Pod CIDR을 L3 스위치에 BGP로 광고합니다. 문제는 ECMP(Equal-Cost Multi-Path)가 활성화된 경우, 같은 플로우의 SYN과 ACK가 서로 다른 경로로 들어올 수 있다는 것입니다. 스위치 레벨의 ECMP 해싱이 5-tuple 기반이면 안전하지만, 구현에 따라 패킷 단위로 분산되기도 합니다.
2. NIC 하드웨어 — RSS 및 오프로딩
ens5f0np0 / ens5f1np1에서 받은 패킷은 RSS(Receive Side Scaling)에 의해 특정 CPU 큐로 배분됩니다. GRO(Generic Receive Offload)가 활성화되어 있으면 작은 패킷을 합쳐 커널로 올리는데, SYN/ACK 같은 소형 제어 패킷은 이 과정에서 타이밍이 미묘하게 영향받을 수 있습니다.
3. Bond1 드라이버 — tcpdump가 안 보이는 핵심 이유
active-backup 모드라면 RX는 항상 active 슬레이브(예: ens5f1np1) 하나에서만 올라오고, bond1 인터페이스에는 나타나지 않는 경우가 있습니다. LACP(802.3ad) 모드에서는 수신이 특정 슬레이브에 고정되므로, tcpdump -i bond1 대신 tcpdump -i ens5f1np1로 캡처해야 패킷이 보입니다.
4. Cilium eBPF (TC hook) — 이 레이어는 정상 통과
Cilium은 tc ingress에 eBPF 프로그램을 붙여 패킷을 처리합니다. Native routing 모드에서는 VXLAN 없이 직접 커널 라우팅 테이블을 활용합니다. cilium monitor에 drop이 찍히지 않는다는 것은 Cilium의 보안 정책, LB 로직, conntrack 레벨에서는 모두 허용됐다는 의미입니다. 즉, 문제는 이 레이어 아래에 있습니다.
5. Netfilter (PREROUTING → LOCAL_IN)
nf_hook_slow가 호출되며 체크섬 검사(nf_checksum)와 등록된 netfilter 룰을 통과합니다. pwru 트레이스상 이 단계에서 DROP 흔적이 없으므로 방화벽/iptables 문제는 배제됩니다.
6. IP 라우팅 + rp_filter — ⚠️ 잠재적 드랍 지점
fib_validate_source가 호출되며 여기서 rp_filter(Reverse Path Filter)가 작동합니다. ECMP 비대칭 라우팅 상황에서 SYN-ACK는 bond1을 통해 나갔는데 클라이언트의 ACK가 다른 슬레이브나 다른 경로로 들어오면, rp_filter Strict 모드(sysctl net.ipv4.conf.all.rp_filter=1)가 이를 스푸핑으로 간주해 드랍할 수 있습니다. 단, pwru 트레이스에서 이 단계를 통과했다면 현재 케이스의 직접 원인은 아닙니다.
7 & 8. tcp_v4_rcv → tcp_check_req → DROP — 실제 드랍 지점
tcp_v4_rcv가 패킷을 받으면 tcp_v4_fill_cb로 TCP 제어 블록을 채운 뒤, LISTEN 소켓이 관리하는 request_sock과 ACK를 대조하는 tcp_check_req로 진입합니다. 여기서 드랍되는 두 가지 핵심 경로는 다음과 같습니다.
경로 A — SYN Cookie 검증 실패: SYN 큐가 꽉 찼을 때 커널이 SYN cookie를 발행하는데, 클라이언트의 최종 ACK에 포함된 쿠키 값이 서버의 재계산 결과와 불일치하면 드랍됩니다. nstat -az | grep SyncookiesFailed 카운터로 확인 가능합니다.
경로 B — request_sock 타임아웃 후 ACK 도착: 서버가 SYN-ACK를 보내고 request_sock(반만 열린 연결 대기 구조)에서 클라이언트 ACK를 기다리는데, L3 스위치 구간의 순간적 지연으로 ACK가 늦게 도착하면 request_sock이 이미 expire되어 "알 수 없는 ACK"로 처리, 드랍됩니다. nstat -az | grep TcpExtListenDrops로 확인합니다.
이 두 경로 중 어느 쪽인지 확정하려면 nstat -az | grep -E 'SyncookiesFailed|ListenDrops|TCPMinisocksDrop' 결과에서 어떤 카운터가 올라가는지 공유해 주시면 바로 다음 단계를 짚어드릴 수 있습니다.
