1. 모놀리틱 서비스 분해
기존의 코드를 포함한 모놀리식 시스템을 어떻게 분해하면 좋을까?
[1] 코드의 '경계'를 찾자.
- 코드를 설계할 때 우리는 응집력이 높고, 각 컴포넌트간 느슨히 결합되는 서비스를 원한다. 하지만 모놀리틱 서비스는 함께 변결될 가능성이 높은것들을 함께 모으기 보단, 모든 종류의 코드를 가져와 이어 붙이는 경향이 있다. 물론 의존성을 잘 설계했더라면 응집력 높은 코드 베이스를 유지하지만 시간이 지나면서 이런 관리를 신경 안 쓸 가능성이 높다.
- 경계의 기준은 코드 베이스의 나머지 부분에 영향을 주지 않는 격리된 코드를 의미한다. 자바에선 package가 있다.
- 따라서 함께 변경될것같은 컴포넌트들을 한 패키지에 모아 놓는 작업부터 시작하는데, 한번에 모든 것들을 바꾸기 보단 한꺼번에 변경할 때 발생하는 피해를 최소화하기 위해 조금씩 점진적으로 변경하자.
- 막상 분리하면 각 패키지는 뒤엉킨 의존성을 가지며 cycle이 생긴다. 원인은 대부분 데이터베이스에 의존하기 때문이다.
[2] 데이터베이스와의 경계를 어떻게 '끊을것'인가?
- 다른 컨텍스트의 테이블에 직접 접근하기보단, 해당 컴포넌트의 API를 통해 데이터를 노출하자. 물론 성능 이슈(rest api 통신)가 있을 수 있지만, 이건 도메인에 따라 수용 가능한지 판단해보자.
- 외부키 관계가 사라지면서 트랜잭션과 같은 제약조건 사라졌고, 데이터의 일관성을 보장하기 힘들어진다. 만약 강한 트랜잭션 결합이 중요한 경우엔 기존 서비스를 따르거나 트랜잭션을 보장할 새로운 방법을 기획하고 아닌 경우 분리하는걸 고려해보자.
참고) 공유 데이터
- StringUtils, enum, 국가 테이블 등 공유 데이터 처리
- 하드 코딩, 디비 테이블 관리가 있다.
- 테이블을 각 패키지에 복제하는 경우 당연히 일관성이 깨지고, 모든 컴포넌트에서 하나의 테이블에 접근하는 경우 의존성이 몰리는 현상이 발생한다. 이를 api를 두고 일관성은 유지하면서 의존성을 관리할 수 있다.
- 두 개 이상의 서비스에서 하나의 테이블에 CURD한다면
- 각각의 서비스에 맞게 테이블을 분리하거나
- 해당 테이블을 다른 추상화된 서비스를 분리하고, 이를 API(id)로 호출
[3] 데이터베이스 분리
- 모놀리틱 서비스 안에 여러 서비스가 하나의 테이블 스키마를 바라보는 상황에서, 이제 각각의 테이블로 분리하고, 분리된 테이블에 따라 서비스도 분리한다.
- 스키마가 분리되면 단일 작업을 수행하는 디비의 호출 횟수가 증가할 수 있다. 또한, 트랜잭션의 일관성 역시 깨질 수 있다.
- 서비스를 분리하는 순간 단일 트랜잭션이 제공하는 안전성이 깨진다. 즉, 데이터의 일관성이 분리 되는데, 이를 위해, 작업의 결과를 큐나 로그 파일에 푸시하고 나중에 재시도 하는 방법도 있다. 이렇게 향후 특정 시점에 시스템이 스스로 일관성을 유지하는 상태가 되로록 허용하는데, 이를 최종적 일관성이라한다. 이렇게 비지니스 작업들이 오래 걸리는 경우 유용하다.
- 다른 방안은 전체 연산 작업을 중지하는데(rollback) 이것마저 실패한다면 굉장히 복잡해진다. 일관성이 유지되기 바라는 작업이 한 두개가 아니라 많다면 굉장한 리소스가 소모될 것이다.
- 2단계 커밋으로 이루어진 분산 트랜잭션 도입한다. 분산 트랜잭션 매니저는 해당된 하위 트랜잭션으로부터 진행 가능 여부를 받고, 하나라도 안되면 롤백한다. 관련된 알고리즘이 많아 사용하면 되는데, 문제가 있다. 분산 트랜잭션 매니저가 다운되거나, 하나라도 투표 결과를 받지 못하면 모든것이차단된다.
- 정말 일관된 데이터가 필요하다면 처음부터 그 상태가 유지되도록 새로운 도메인을 만드는것도 고려해보자.
[4] 리포팅
- 모놀리틱 서비스 아키텍처에서 모든 데이터는 거대한 단일 디비에 저장하여 이를 리포팅하기 굉장히 쉽다. 이때, 리포팅 쿼리가 메인 시스템에 영향을 끼치지 않게 하기 위해, replica 디비에서 처리한다.(relica 디비는 메인 디비와 주기적으로 sync 맞춤)
- 하지만 운영 디비 스키마를 그대로 사용하여 추출을 위한 리포팅 디비 스키마를 변경할 수 없다. 리포팅을 위해 운영 디비 스키마를 변경하는건 말이 안된다. RDB의 한계이기도 하면 로깅 처리도 힘들다. 당연히 리포팅을 위한 최적화도 어렵다.
- 리포팅시스템에서 각각의 원본 시스템으로 API를 통해 데이터를 추출하면, 많은 양의 데이터를 가져와야 되며, 서비스 트래픽이 폭파될 가능성이 있다.
- 따라서 주기적으로 배치 프로그램으로 데이터를 가져올 수 있는데, 이는 실시간성 처리가 힘든 단점이 있다. ex) 일주일간/한달간 디비 쿼리 성능 분석을 노티
- 따라서 이벤트 기반의 통신이 일어날 때 각 서비스에서 리포팅 시스템으로 데이터를 전달하는 방법도 있다. 즉, 매 통신마다 해당 스트림셋 혹은 하둡으로 직접 전송하거나 파일비트로 로그를 떨구는 등의 작업으로 처리한다. ex) 중요 데이터를 통신마다 적재하여 사용
2. 배달의 민족 마이크로서비스 여행기
MSA로의 전환은 기술의 선택이 아닌, 생존의 전략.
- 이전엔 프론트 서버, 회원/인증, 리뷰, 주문, 정산, 쿠폰 등 한곳에서 관리하는 단일 서비스 형태였다. 하나의 디비에 약 700여개의 테이블, 스토어드 프로시저는 4,000개로 거대한 모놀리틱 시스템이었다.
- 그러던 중 리뷰 테이블에 어떤 문제가 생겨 DB 전체에 문제가 발생했으며, 사실 리뷰가 발생해도 다른 서비스엔 영향이 없어야한다.
- 따라서 점진적으로 각각의 서비스를 분리하느 작업(디비를 분리)을 시작하기로 한다.
- 또한, 기존엔 법적으로 IDC에서 서버를 관리하였는데, 이를 Cloud 시스템으로 AWS 형태로 이동하기 시작한다. 이게 왜 중요하냐면 서버의 증설이 매우 편리하며, 이러한 서버 관리를 어느정도 인프라 회사로 넘길 수 있어 트래픽을 유동적으로 처리할 수 있다.
- 조회쪽 처리 디비를 RDB -> NoSQL로(용량관리) 이동했으며, write/read 데이터 싱크는 1~5분 주기로 배치 작업으로 처리하여 부하를 줄였다.
- 주문 시스템은 주문 완료시 리뷰, 광고 등 다양한 시스템의 api를 호출하는데 이걸 이벤트 기반 데이터 전달 방식으로 변경했다. 리뷰, 광고 시스템 등이 장애시 주문 시스템도 의존성이 요쪽에 있기 때문에 영향이 가하며 새로운 시스템과 연동할때마다 주문 시스템은 고통이된다. 따라서 주문 시스템 완료시 특정 토픽에 produce하고, 각각의 다른 팀들이 이를 consume하는 방향으로 이동한다. 또한, 특정 작업의 손실 없이 안정적인 점도 있다.
- CURS 도입
- 기존 시스템에선 명령 시스템을 사용하는 컴포넌트 문제시 다른 서비스에도(조회) 영향이 가해지며, 특정 컴포넌트에선 조회가 급격히 폭파할때가 있다. 즉, 대용량 트래픽을 대응해야하며, 특정 서비스에서 장애가 나도 다른 서비스는 유지해야 한다. 따라서 명령과 조회 서비스를 분리하여 이를 어느정도 해결할 수 있지만, 데이터 동기화 작업이 필요하다.
- Command and Query Responsibility Segregation
- 사장님 사이트에 의해 데이터가 변경(명령)하는 작업과 조회하는 컴포넌트를 분리하고, 이를 Event-Driven 방식 Producer/Consumer 구조로 사용한다. 명령 데이터를 토픽에 넣고, 조회 서비스에서 이를 조회한다. 약간의 데이터 지연이 있지만 최종적으로 데이터의 sync가 맞는다.
- 이때 이벤트 드라이븐 전달시 id만을 전달하는데 이는 변경되는 데이터의 순서보단 데이터의 최종 결과물만 관심이 있기 때문이다. id에 해당하는 데이터는 그 이후에 각각 호출하여 데이터 싱크를 맞춘다.
- 조회쪽 디비는 ES, Redis, MongoDB와 같이 조회가 빠른 것 / 사장님 서비스는 안정성이 중요하므로 RDB로 사용한다.
시스템이 커지고, 트래픽이 커지고 규모의 경제가 가능해지는 순간에 MSA가 필요하다. 단순하게 테이블을 조인하면 될걸 데이터 싱크하고 맞추는 과정에서 비용이 10배는 더 든다. 이를 상쇄하고도 남는 경우에만 MSA로 넘어간는것이 맞다는 조언.
3. 의존성 관리 - 우아한 객체지향
[1] 의존성을 이용한 설계
- 설계란 코드를 어떻게 '배치'할 것인지에 대한 의사결정이다. 어떤 코드를 class, package, project 등에 배치할지 고민한다.
- 핵심은 '변경'이다. 같이 변경되는 얘들을 같은 클래스, 패키지에 모아 놓는다. 따라서 의존성에 따라 설계가 바뀌기 때문에 설계의 핵심은 의존성이다.
- A가 B에 의존한다는 의미는, B가 변경될때 A도 함계 변경될 여지가 있다는 의미다. 즉, 변경에 의한 영향을 받을 수 있는 '가능성'이 있다와 같은 의미이다.
[2] 클래스 의존성 종류
Association
- 강한 결합으로, A에서 B로 이동할 수 있다는 의미다.
- 연관관계는 빈번하게 협력할 때 사용하며, 영구적 관계를 맺는다. 구현 방법 중 하나는 객체 참조다.
class A { private B b; }
Dependency
- 파라미터, 리턴 타입, 메서드 안에 타입이 생성된다면 의존관계가 성립된다.
- 일시적 관계를 맺는다.
public B method(B b) { return new B(); }
Inheritance
- 상속관계는 B가 바뀔 때 A가 변경될 수 있는데, 구현이 변경되면 영향을 받는다.
class A extends B { }
Reliaization
- 실체화 관계는(인터페이스) 인터페이스가 바뀌면 (구현x) 영향을 받는다.
class A implements B { }
패키지 의존성
- package 레벨이며, 간단히 import에 다른 객체가 존재하면 의존성을 가진다고 생각할 수 있다.
[3] 설계 가이드
- 양방향 의존성을 피하자.
- A <-> B : A가 바뀔 때 B가 바뀌고, A가 또 바뀔 수 있다.
- 이는 한 클래스를 억지로 분리한 것으로 생각할 수 있다.
- 성능 이슈 및 여러 문제점이 발생할 여지가 있다.
- 다중성이 적은 방향을 선택하라.
- 컬렉션을 인스턴스 변수로 갖지 않도록 한다. 이는 성능 이슈 등 다양한 이슈가 생길 수 있다.
class A { private Collection<B> bs; } + class B { } x class A {} + class B { private A a; } o
- 컬렉션을 인스턴스 변수로 갖지 않도록 한다. 이는 성능 이슈 등 다양한 이슈가 생길 수 있다.
- 의존성이 필요없다면 제거하자.
- 패키지 사이의 의존성 사이클을 제거하자.
- 의존성이 양방향이면 같이 바뀌니까 하나의 패키지로 만드는 것이 낫다.
- 패키지 3개가 한 싸이클이면 하나의 패키지로 보는것이 맞다.
[3] 설계 개선하기
- 설계를 개선하는 방법을 고민할 때는, 하나의 클래스를 파악하기 보단, 객체의 협력을 파악해야한다. 즉, 설계를 개선할려면 객체간 '의존성'을 봐야한다.
- 조영호님은 반드시 의존성을 그려본다고 한다. 초반에는 일단 구현해보고, 설계를 개선하는것도 괜찮은 방법이다.
1) 추상화
- 보통 추상화를 떠올리면 추상 클래스나 인터페이스를 떠올리는데, 개발에서 추상화는 '잘 안변하는 것이다'
- A, B 패키지가 있을 때 서로 양방향 의존성을 가진다면 추상 객체를 두어 의존성을 끊을 수 있다.
- A -> B 에 특정 객체를 참조할 때 A 패키지에 추상 객체를 두고 B에서 A의 추상 객체로 convert하는 메소드를 둔 후, B에서 A로 넘길 때 convert한 값을 넘겨 의존성을 끊을 수 있다.
- 여기선 OptionGroup, Option으로 (잘 변하지 않을) 추상화한다.
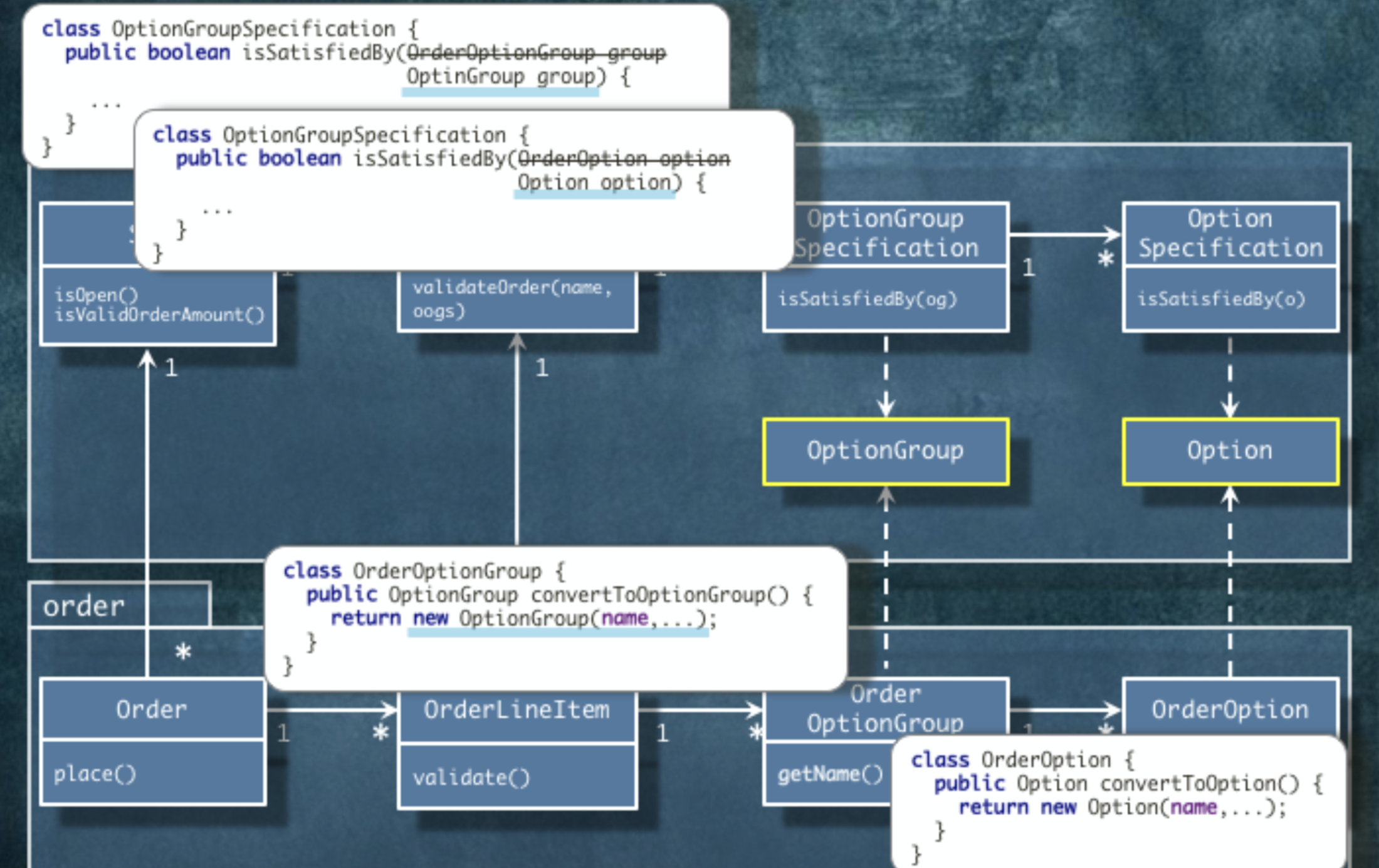
2) 강한 결합의 경계
- ORM 상황의 강한 결합의 경우 '어디까지 조회할 것인가'에 대한 문제가 생긴다. 대표적으로 lazy 로딩문제가 있다.
- 도메인 규칙을 함께 적용해야하는 객체의 범위는? 에대한 궁금증도 생기고, 이는 곧 '트랜잭션의 경계는 어디까지인가?'의 문제로 이어진다. 즉, "어떤 테이블에서 어떤 테이블까지 하나의 단위로 잠금할 것인가?" 고민된다.
- 객체 참조는 어디로든 갈 수있어 '편리함'은 있지만 이는 곧 모든 것들을 연결하는 문제가 있다. 어느 객체라도 접근 가능하다고 생각한다. 따라서 필요한 경우가 아니라면 객체 참조는 모두 끊어버려야한다.
3) 다른 도메인의 데이터 조회
- A 도메인에서 B 도메인의 내용이 궁금할 때 B도메인을 강한 결합으로 가져오기 보단, 인터페이스를 통해 B에 접근한다. 좀 더 결합을 약하게한다.
- 이때, 다른 도메인의 디비에 직접 접근하기 보단, id를 통해 접근한다. 즉, 한방 쿼리를 도메인 마다 분리하여 비지니스 로직을 쿼리에 모두 담지 않는다.
- 그렇다면 어떤 객체들을 묶고, 어떤 객체들을 분리할 것인가?
- 함께 생성되고, 변경되고, 삭제되는 객체끼리 묶는다.
- 도메인 제약사항을 공유하는 객체끼리 묶는다. (객체를 묶는 기준은 서비스마다 다르다.)
- 트랜잭션 안에 있는 것은 같이 변경되는 것들이 있어야한다.
- 즉, 객체를 분리한 단위가 트랜잭션 단위가 되고 조회 단위가 된다. 같은 경계안에 있는 객체끼리는 한 번에 조회가 되고 Lazy 로딩을 할 수 있다.
4) Event Driven
- 실시간이 꼭 필요한 경우가 아니라면 producer / consumer 구조를 가져가 작업을 큐에 넣고 대상자가 이를 가져가는 방식을 활용한다.
- 이 경우 producer와 consumer간 결합력이 굉장히 낮아지는 효과가 발생한다.
[4] 의존성과 시스템 분리
- 레이어 단위로 아키텍처를 꾸리면, 초기에는 간단하지만 시간이 지나면서 하나의 변경이 여러 레이어를 이동하며 수정할 수 있다.
- 도메인 단위로 아키텍처를 꾸리면, 페키지간(도메인간) 의존성 관리가 초기에 어려움이(영역 침범) 있으나 이를 지킬 경우 레이어 아키텍처보단 의존성 관리가 좀 더 수월해진다.
- 추가로, 도메인 단위로 분리할 경우 도메인(비지니스)끼리 비동기적인 메시지를 가지고 통신하는 경우가 많다. 만약 동기적으로 한다면 시스템이 한번에 다 터질 수 있는 위험이 있기 때문에, 약간의 delay를 허용한다면 굉장히 비동기 방식을 생각해보자.
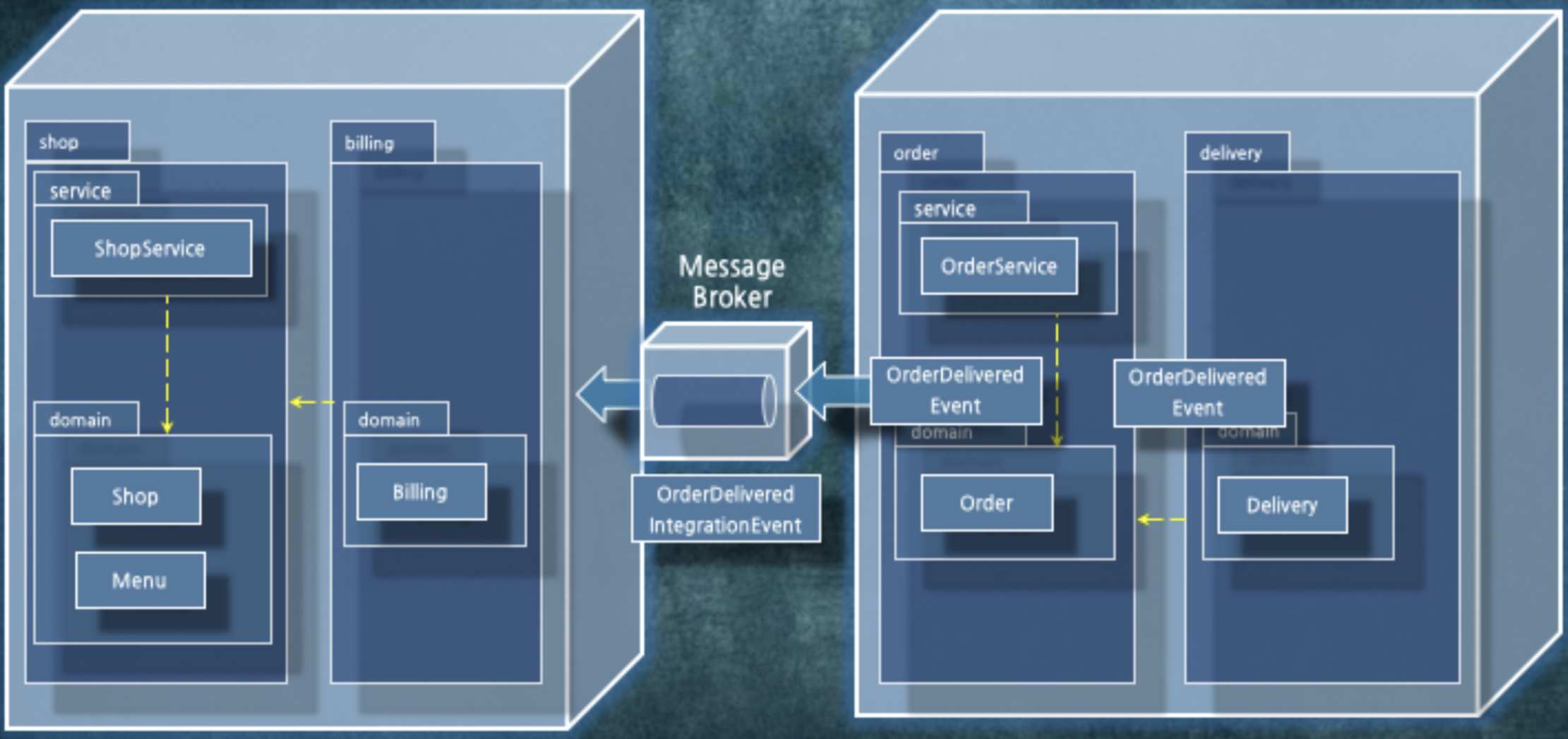
시스템을 볼 때는 의존성을 보고, 의존성에 따라 시스템을 진화시켜라!

성장하는 개발자가 되고싶어요