1. Spring Batch란?
- Spring Batch는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 리소스 관리 등 대용량 레코드 처리에 필수적인 기능을 제공한다. 또한 최적화 및 파티셔닝 기술을 통해 대용량 및 고성능 배치 작업을 가능하게 하는 고급 기술 서비스 및 기능을 제공한다.
- Spring Batch에서 배치가 실패하여 작업 재시작을 하게 된다면 처음부터가 아닌 실패한 지점부터 실행을 하게 된다.
- 또한 중복 실행을 막기 위해 성공한 이력이 있는 Batch는 동일한 Parameters로 실행 시 Exception이 발생하게 된다.
Spring Batch vs Scheduler?
- Spring Batch는 Scheduler가 아니기에 비교 대상이 아니다.
- Spring Batch는 Batch Job을 관리하지만 Job을 구동하거나 실행시키는 기능은 지원하고 있지 않는다. Spring에서 Batch Job을 실행시키기 위해서는 Quartz, Scheduler, Jenkins등 전용 Scheduler를 사용하여야 한다.
2. Spring Batch 용어
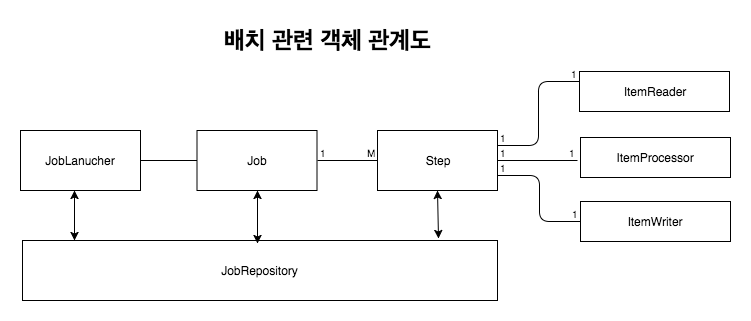
[1] Job
- Job은 배치 처리 과정을 하나의 단위로 만들어 놓은 객체다. 또한 배치 처리 과정에 있어 전체 계층 최상단에 위치한다.
[2] JobInstance
- JobInstance는 Job의 실행 단위를 나타낸다. Job을 실행시키면 하나의 JobInstance가 생성된다. 예를 들어 하나의 Job을 1월 1일 실행하고, 1월 2일에 실행을 하게 된다면, 각각의 JobInstance가 생성된다. 만약 1월 1일에 실행한 JobInstance가 실패하여 다시 실행을 시키더라도, 이 JobInstance는 1월 1일에 대한 데이터만 처리하게 된다.
[3] JobParameters
- JobInstance는 Job의 실행 단위라고 했다. 그렇다면 각각의 JobInstance는 어떻게 구별할까? 이는 JobParameters 객체로 구분하게 된다. JobParameters는 JobInstance 구별 외에도 개발자 JonInstance에 전달하는 매개변수 역할도 하고 있다.
- JobParameters는 String, Double, Long, Date 4가지 형식만을 지원하고있다.
[4] JobExecution
- JobExecution은 JonInstance에 대한 실행 시도에 대한 객체다. 1월 1일에 실행한 JobInstance가 실패하여 재실행을 하여도 동일한 JobInstance를 실행시키지만 이 2번에 실행에 대한 JobExecution은 개별로 생기게 된다. JobExecution는 이러한 JobInstance 실행에 대한 상태, 시작시간, 종료시간, 생성시간 등의 정보를 담고있다.
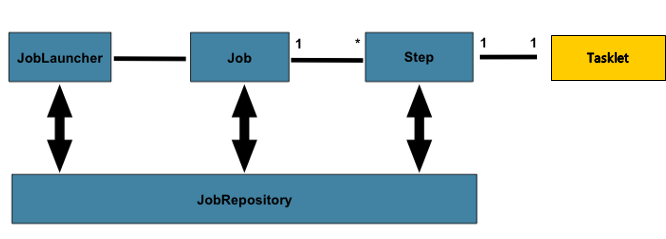
[5] Step
- Step은 Job의 배치 처리를 정의하고 순차적인 단계를 캡슐화한다.
- Job은 최소 1개 이상의 Step을 가지며, Job의 실제 일괄 처리를 제어하는 모든 정보가 들어있다.
[6] StepExecution
- StepExecution은 JobExecution과 동일하게 Step 실행 시도에 대한 객체를 나타낸다. 하지만 Job이 여러개의 Step으로 구성되어 있을 경우 이전 단계의 Step이 실패하게 되면 다음 단계가 실행되지 않음으로 실패 이후 StepExecution은 생성되지 않는다. StepExecution 또한 JobExecution과 동일하게 실제 시작이 될 떄만 생성된다.
- StepExecution에는 JobExecution에 저장되는 정보 외에 read 수, write 수, commit 수, skip 수 등의 정보들도 저장된다.
[7] ExecutionContext
- ExecutionContext란 Job에서 데이터를 공유 할 수 있는 데이터 저장소다. Spring Batch에서 제공하는 ExecutionContext는 JobExecutionContext, StepExecutionContext 2가지 종류가 있으나 이 두가지는 지정되는 범위가 다르다.
- JobExecutionContext의 경우 Commit 시점에 저장되는 반면 StepExecutionContext는 실행 사이에 저장이 되게 된다.
- ExecutionContext를 통해 Step간 Data 공유가 가능하며 Job 실패시 ExecutionContext를 통한 마지막 실행 값을 재구성 할 수 있다.
[8] JobRepository
- JobRepository는 위에서 말한 모든 배치 처리 정보를 담고있는 매커니즘이다. Job이 실행되면 JobRepository에 JobExecution과 StepExecution을 생성하게 되며 JobRepository에서 Execution 정보들을 저장하고 조회하며 사용하게된다.
[9] JobLauncher
- JobLauncher는 Job과 JobParameters를 사용하여 Job을 실행하는 객체다.
[10] ItemReader
- ItemReader는 Step에서 Item을 읽어오는 인터페이스다. ItemReader에 대한 다양한 인터페이스가 존재하며 다양한 방법으로 Item을 읽어 올 수 있다.
[11] ItemWriter
- ItemWriter는 처리 된 Data를 Writer 할 때 사용한다. Writer는 처리 결과물에 따라 Insert가 될 수도 Update가 될 수도 Queue를 사용한다면 Send가 될 수도 있다. Writer 또한 Read와 동일하게 다양한 인터페이스가 존재한다. Writer는 기본적으로 Item을 Chunk로 묶어 처리하고 있다.
[12] ItemProcessor
- Item Processor는 Reader에서 읽어온 Item을 데이터를 처리하는 역할을 하고 있다. Processor는 배치를 처리하는데 필수 요소는 아니며 Reader, Writer, Processor 처리를 분리하여 각각의 역할을 명확하게 구분하고 있다.
3. Spring Batch 사용하기
- Spring Batch에서의 Job은 여러가지 Step의 모음으로 구성되어 있으며, Job은 순차적인 Step을 수행하며 Batch를 수행하게 된다.
- Step은 Tasklet 처리 방식과 Chunk 지향 처리 방식을 지원하고 있다.
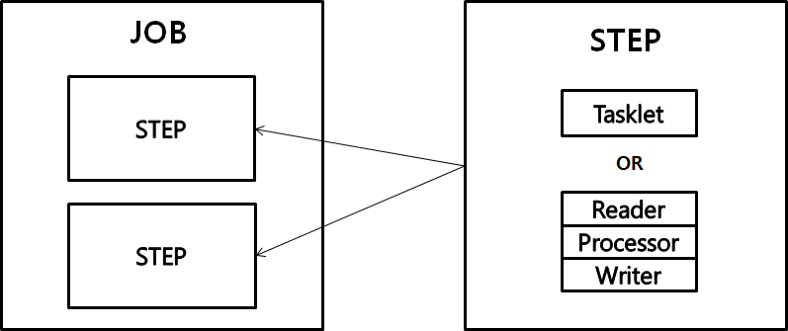
[2] Tasklet
- Tasklet은 하나의 메서드로 구성 되어있는 간단한 인터페이스다.
- 이 메서드 는 실패를 알리기 위해 예외를 반환 하거나 throw할 때까지 execute를 반복적으로 호출하게된다 .
- Taslket에서는 @BeforeStep, @AfterStep을 통해 execute 배치 실행 전 후에 Event를 등록하여 실행 시킬 수 있다.
- 일반적으로 리소스를 삭제하거나 쿼리를 실행하는 것과 같은 단일 태스크를 호출하는 시나리오에 사용된다.
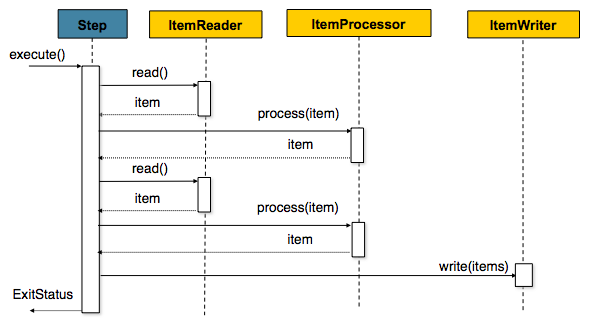
[3] Chunk
- Spring Batch에서 Chunk란 처리 되는 커밋 row 수를 의미한다. Batch 처리에서 커밋 되는 row 수라는 건 chunk 단위로 Transaction을 수행하기 때문에 실패시 Chunk 단위만큼 rollback이 되게 된다.
- Chunk 지향 처리에서는 다음과 같은 3가지 시나리오로 실행된다
- Read : Database에서 배치처리를 할 Data를 읽어온다
- Processing : 읽어온 Data를 가공,처리를 한다 (필수사항X)
- Write : 가공,처리한 데이터를 Database에 저장한다.
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read()
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items);적절한 Paging Size와 Chunk Size에 관하여..
- Spring Batch에는 다양한 IremReader, ItemWriter가 조재한다. 대용량 배치 처리를 하게되면 Item을 읽어 올 때 Paging 처리를 하는게 효과적이다.
- Spring Batch Reader에서는 이러한 Paging 처리를 지원하고 있다. 또한 적절한 Paging 처리와, Chunk Size(한번에 처리 될 트랜잭션)를 설정하여 더욱 효과적인 배치 처리를 할 수 있다.
- Paging Size가 5이며 Chunk Size가 10일 경우 2번의 Read가 이루어진 후에 1번의 Transaction이 수행된다. 이는 한번의 Transaction을 위해 2번의 쿼리 수행이 발생하게 된다.
- 따라서 Read 쿼리 수행시 1번의 Transaction을 위해 두 설정의 값을 일치를 시키는게 가장 좋은 성능 향상 방법이며 특별한 이유가 없는 한 Paging Size 와 Chunk Size를 동일하게 설정하는 것을 추천한다.
PagingReader 사용 시 주의사항
- 페이징 처리 시 각 쿼리에 Offset과 Limit를 지정해 주어야 하는데 이는 PageSize를 지정하면 Batch에서 Offset과 Limit를 지정해준다. 하지만 페이징 처리를 할 때 마다 새로운 쿼리를 실행하기 때문에 데이터 순서가 보장 될 수 있도록 반드시 Order By를 사용하여야 한다.
- 참고로 Chunk Size는 한번에 처리될 트랜잭션 단위이며, Page Size는 한번에 조회할 Item 양을 의미한다.
4. Spring Batch 관련 페이징 참고
- 디비에서 데이터를 읽는데 20개씩 끊어서 읽어오고 싶다. 그렇다고
limit문법으로 20개씩 끊어서 데이터를 읽는다면 처음에는 괜찮지만 후반부에는 성능이 풀스캔과 비슷하게 성능이 나빠진다. 따라서 Spring Batch에서 제공하는 paging 기법을 활용하여, 틀정 컬럼의Where조건절로 데이터 조건절을 계속해서 줄이고 limit 0, 20으로 초반부 데이터만 읽게한다. - Spring Batch를 통해 페이지를 끊어서 읽는데, 이는 하나의 커넥션을 너무 길게 가져가는 걸 방지한다. 그런데 1억개의 데이터를 읽는데 Page를 2000개씩 끊는다면 I/O가 너무도 빈번할 것이다. 물론 BE개발자 입장에서 쿼리에 비즈니스 로직을 담는건 막고 싶지만 성능이 나쁜것은 어쩔 수 없다. 따라서 이러한 경우엔 group by 등 쿼리 단에서 처리가 필요할 것이다.

성장하는 개발자가 되고싶어요