1. Thread
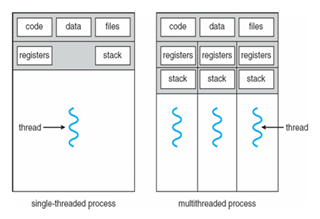
프로세스는 프로그램을 실제로 실행시킨것으로 작업의 단위입니다. 반면 스레드는 프로세스 안에서 실행 단위로로 실행의 흐름을 제어합니다. 이때, 한 프로세스 안에 여러 스레드가 존재할 수 있습니다. 같은 프로세스에 있는 스레드들은 Code, Data, Files(I/O), Heap 영역을 공유하지만 Register, Stack을 별도로 가집니다.
-
스택은 함수 파라미터, 리턴 주소 값, 지역 변수 등 함수 관련 정보가 담겨져있습니다. 스택을 별도로 가지기 때문에 독립적 함수 호출이 가능하며 이는 독립적 실행 흐름을 가질 수 있습니다.
-
레지스터를 별도로 가지는 이유는 스레드마다 어디까지 인스트럭션을 수행 했는지 나타내는 PC를 저장하기 위해서입니다. 따라서 Context Swiching시 다음 인스트럭션을 보다 빠르게 수행할 수 있습니다.
2. Multi Processing vs Multi Threading
[1] 공통점
멀티 프로세싱, 멀티 스레딩 모두 '동시에' 여러 프로그램을 실행시킨다는 관점에서 동일하다. 여기서 말하는 '동시성'은 사람이 인지하지 못하게 매우 빠른 속도로 프로그램을 전환시켜, 동시에 여러 프로그램이 수행한다고 착각하게 만드는 기법이다.
[2] 멀티 스레딩의 장점
Rosource 경량화
프로세스 내의 스레드들은 code, data, heap etc 영역을 공유하고 별도로 스택, 레지스터를 가집니다. 따라서 공유 영역 만큼의 리소스가 적게 필요합니다.
빠른 Context Swithcing
공유 영역 만큼의 Context를 따로 저장하고 복구할 필요가 없습니다.
정보 교환
프로세스들 사이의 정보 교환은 IPC로 커널의 개입이 있어 오버헤드가 발생합니다. 하지만 같은 프로세스 내의 스레드간 정보 교환은 공유 데이터 영역을 읽고 씀으로 문제를 해결할 수 있습니다.
프로세스 내의 스레드들은 code, data, heap etc 영역을 공유하고 별도로 스택, 레지터를 가집니다. 따라서 공유 영역 만큼의 리소스가 적게 필요합니다.
또한 Context Switching시 공유 영역만큼의 Context를 따로 저장할 필요가 없습니다 뿐만 아니라
뿐만 아니라 프로세스들 사이의 정보 교환은 IPC로 커널의 개입이 있어 소요시간의 오버헤드가 발생한다. 하지만 같은 프로세스 내의 스레드간 정보 교환은 공유 데이터 영역을 읽고 씀으로 문제를 해결할 수 있다.
[3] 멀티 스레딩의 단점
공유 데이터에 스레드들이 동시에 접근하는 경우 '동기화' 문제가 발생할 수 있다.
같은 프로세스 내 스레드들은 공유 데이터를 사용함과 동시에, 동기화, 데드락, Trap 등의 이유로 한 스레드에 문제 발생시 다른 스레드에게도 영향을 끼칠 수 있다. 이전 Explore창에서 한 개의 탭이 문제가 발생하면 다른 탭들도 함께 종료되는 것이 한 예시이다.
[4] 결론
계산기와 메모장처럼 서로 완전히 별개의 프로그램이라면 독립적인 프로세스를 구성해야되고, 서로 관련된 기능들은 멀티 스레드로 구현하는것이 좋다.
[3] 멀티 스레딩의 단점
- 공유 데이터에 스레드들이 동시에 접근하는 경우 동기화 문제가 발생할 수 있습니다. 이를 해결하고자 데드락, 트랩 등을 사용하기도 하는데, 이때 한 스레드에 문제가 다른 스레드에게도 영향을 끼치기도합니다
- 예를 들어 이전 Explore 창에서 한 개의 탭이 문제가 발생하면 다른 탭들도 함께 종료되는 경우가 있습니다.
[4] 결론
계산기와 메모장처럼 서로 완전히 별개의 프로그램이라면 독립적인 프로세스를 구성해야되고, 서로 관련된 기능들은 멀티 스레드로 구현하는것이 좋습니다.
3. Thread Pool
웹 서버에서 멀티 스레딩을 구현한다고 가정해봅니다. 매 요청마다 스레드를 만들면 런타임 때 소요되는 시간이 길어지고 무한정 많이 스레드를 만들면 메모리 한계도 존재합니다. 이러한 문제를 해결하는 방법에는 Thread Pool이 존재합니다.
프로세스가 시작할 때 일정 수의 스레드를 미리 풀에 여러개 생성합니다. 이후 생성된 스레드들이 대기하고 있다 요청이 들어오면 풀에서 사용 가능한 스레드를 선택하여 요청을 처리합니다. 이후 작업을 완료하면 풀 영역에 다시 들어갑니다.
장점
- 스레드를 미리 생성하여 Runtime 때 스레드 생성 비용을 줄입니다.
- 스레드의 갯수를 제한하여 Context Switching의 비용을 줄일 수 있습니다.
