1. Background
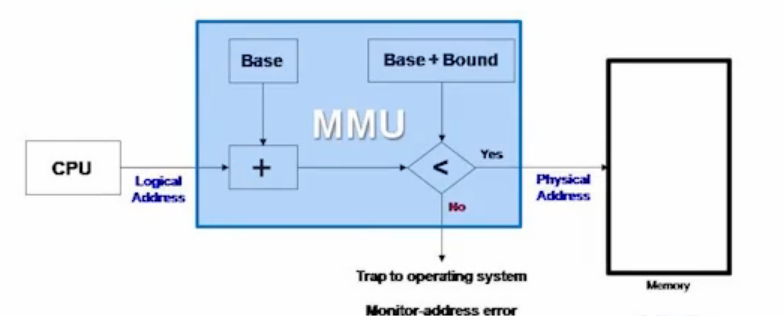
메모리는 OS 영역과 User Process 영역으로 구분합니다. User Process는 독립된 메모리 공간을 갖고, 다른 프로세스 메모리 공간에 접근할 수 없습니다. 이를 위해 시작 물리 주소인 Base, 프로세스 크기를 담는Limit Register를 사활용합니다. 즉, 메모리를 참조할 때마다 Base + Limit register 값을 넘는지 체킹합니다. 만약 잘못된 메모리 영역을 접근한다면 Trap Interrupt를 걸어 오류를 막습니다.
2. Address Binding
프로세스 메모리 주소 결정 시기가 언제냐에 따라 세 가지로 분류합니다.
[1] Compile Time
- 컴파일/링킹하는 과정에서 메모리 주소가 결정됩니다. 주소 설정이 매우 간단하지만 임의의 프로그램이 동시에 로드 할 수 없고 항상 고정된 주소에만 로드 해야 되서 컴파일 환경이 바뀌면 다시 컴파일 합니다.
- 예를 들어, 게임을 만드는 회사에서 PC를 고려 안하고, A부터 B까지의 메모리 영역을 사용함을 정하는것은 말이 안됩니다. 또한, 멀티 프로그래밍같이 프로세스 메모리 위치가 자주 바뀌는 상황에서도 적절치 않습니다.
- 따라서, 자신의 프로그램만 동작하는 환경에서만 사용합니다.
- Ex) Com 확장자/ Kernal Code / 아두이노
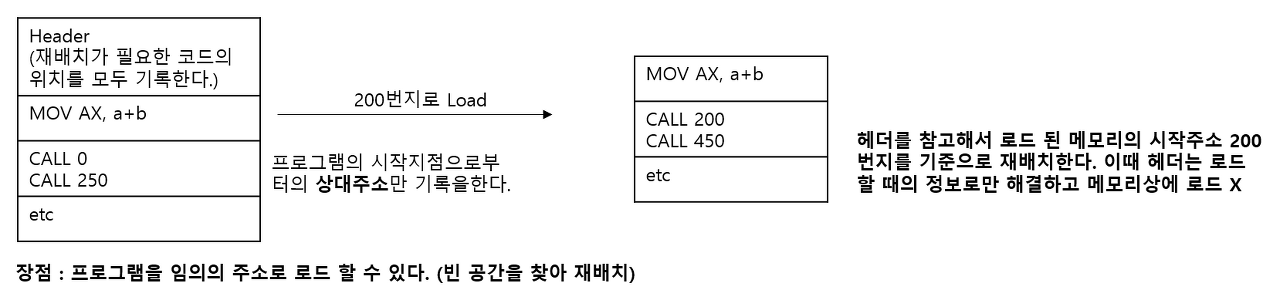
[2] Load Time
프로그램을 메모리로 로드시 주소가 결정됩니다. 컴파일 과정에서 메모리 주소를 필요로하는 인스트럭션 주소를 결정하는 것이 아니라, 이런 부분은 표시만 하고 (상대주소) 프로그램 실행을 위해 메모리로 로드되는 시점에 인스트럭션 주소를 확정 짓도록 코드를 수정합니다.
이 방식은 Compile Time Address Binding의 문제를 해결한 것으로 멀티 프로그래밍이 가능합니다. 하지만 메모리에 프로그램을 로드할 때마다 메모리 참조 명령어를 모두 바꿔야 해서 메모리 로딩시 너무 시간이 오래걸리는 단점이 있습니다.
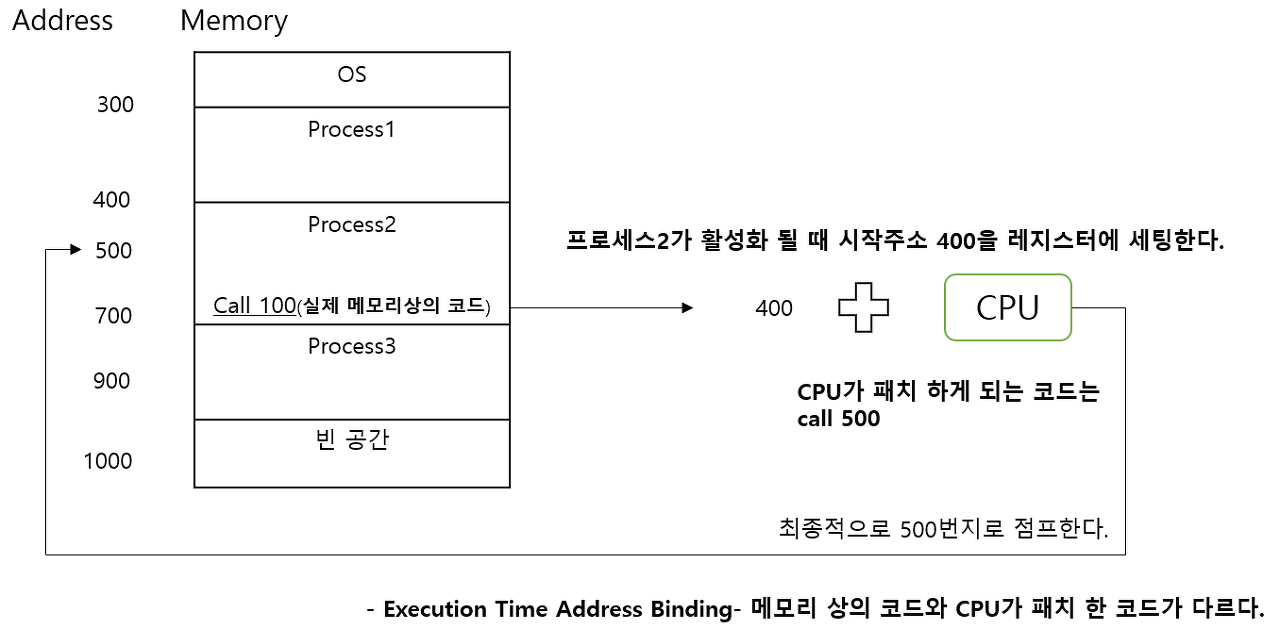
[3] Execution Time
CPU가 해당 인스트럭션을 실행시키는 시점(패치 바로 직전)에 주소를 결정합니다. 아래와 같이 동작하는데 추가 연산으로 인해 속도가 느려 MMU HW 지원을 필요로합니다.
- Relocation Register : 프로세스 시작 주소를 저장하며, 프로세스가 활성화 될 때마다 해당 프로세스의 시작주소를 OS에 의해 저장합니다.
- Compiler : 0번지에서 시작하는 주소 값으로 Call Insturction을 컴파일합니다.
- CPU : IR 패치시 메모리 참조 IR인 경우 항상 주소 값을 레지스터 값과 더해서 가져옵니다.
※ MMU (Memory Management Unit)란?
CPU 코어 안에 탑재되어 가상주소를 실제 메모리 주소로 변환 해주는 장치입니다.
3. Process Hole
프로세스를 빈 공간 중 어디에 넣을지 고민합니다.
- First Fit : 가장 최초로 발견되는 빈 공간에 할당합니다. 속도는 빠르지만 메모리가 낭비됩니다.
- Best Fit : 빈 공간을 모두 비교하며 자투리가 가장 좋은 곳에 넣습니다. 속도는 느리지만 메모리 낭비가 적습니다.
- Worst Fit : 빈 공간이 가장 큰 공간에 넣습니다.
시뮬레이션 결과 메모리 측면에서 Worst Fit이 좋지 않고, 속도 측면에서 First Fit이 적합합니다.

4. Fragmentation
프로세스들이 메모리에 적재되고 제거되는 일이 반복되면 프로세스들이 차지하는 메모리 틈 사이에 사용하지 못할 만큼의 작은 자유 공간들이 늘어는데 이를 단편화라고 합니다.
- Internal Fragmentation : 프로세스가 필요한 양보다 더 크게 할당 받아 남는 경우를 말합니다.
- External Fragmentation : 메모리 할당/해제가 빈번히 일어나 중간 중간에 사용 못 하는 짜잘짜잘한 메모리 영역이 존재합니다. 손실 정도는 외부 단편화가 내부 단편화보다 큽니다.
단편화 문제를 해결하고자 Compaction을 이용 하기도 합니다. 이는 작은 공간들을 모두 한곳으로 모으는 것으러 메모리 관점에서는 확실한 방법이지만 작업 효율이 좋지 않습니다. 따라서 보통 Paging, Segmentation을 이용합니다.
5. Paging
[1] Paging이란
하나의 프로세스가 사용하는 메모리가 연속적일 필요는 없는 메모리 관리 방법입니다. 물리 메모리는 Frame이라는 고정 크기로, 프로세스의 논리 공간은 페이지라 불리는 고정크기의 블록으로 구분합니다. 이때 페이지, 프레임 모두 같은 크기로 나누고, 이 둘을 맵핑 시켜주는 page table이 존재합니다. Page Table은 논리 주소 Index와 물리 주소 Index를 맵핑 시켜줍니다. 이 방식은 내부 단편화가 존재하지만 외부 단편화를 해결한 방법으로 메모리 공간을 좀 더 효율적으로 사용할 수 있습니다.
Logical Address는 page number과 offset 값으로 구성합니다. 먼저 page number를 참조하여 물리 메모리의 몇번째 페이지인지를 탐색하고, offset 값으로 해당 페이지 안에서 어느 부분을 참조하는지 파악합니다.

[2] TLBS (Translation Look Asides Buffers)
페이징으로 메모리 주소를 접근할 때, 물리 주소를 접근할 때 Page Table을 참조하는데 한 번, 실제 메모리에 접근하는데 한 번을 더하여 총 두 번이 필요합니다. 메모리 접근은 충분한 Overhead로 간주하여 캐싱을 활용한 TLBS를 도입했습니다. 이는 페이지 테이블 정보를 캐시하여 메모리 접근 횟수를 줄입니다. 쉽게 말하면 TLBS는 Page Table Cache라고 생각하면 됩니다.

[3] Page Table Structure
- 페이지 테이블 크기가 증가하여 연속 공간 할당의 문제가 발생했습니다. 따라서 메모리를 조금 더 쓰고, 메모리를 조금 더 쓰더라도 '연속'된 공간의 페이지 테이블을 쓰는것이 아닌 '트리'구조를 활용하여 페이지 테이블 자체를 분리하는 방식을 도입 했습니다.
- 프로세스 당 페이지 테이블을 두어 중첩된 페이지 테이블을 무분별하게 사용하여 공간의 낭비가 발생합니다. 이를 공유 페이지 테이블을 두어 문제를 해결하기도 합니다. 물론 프로세스당 페이지 테이블을 두는것보다 원하는 인덱스를 추출하는데 시간이 오래걸리는 단점이 추가됩니다.
- 페이지 테이블에서 해당 인덱스를 찾는데 시간이 오래 걸립니다. 이를 선형 탐색이 아닌 'Hashing'을 사용하기도 합니다.

※ 32bit와 64bit의 차이점
CPU는 레지스터와 함께 데이터를 처리합니다. 32bit 컴퓨터는 레지스터의 크기가 32bit이고, 64bit는 레지스터의 크기가 64bit입니다. 레지스터 크기 차이로 한 번에 데이터를 처리하는 양이 달라집니다. 따라서 64bit 컴퓨터가 데이터 처리 능력이 더 좋습니다. 또한, 레지스터 크기가 달라지면 램 사용량이 달라집니다. 참고로 2^32는 4GB까지 표현 가능하고 그 이상은 표현 불가합니다. 따라서 4GB 이상의 메모리를 쓰는 컴퓨터는 32bit를 사용하지는 못합니다.
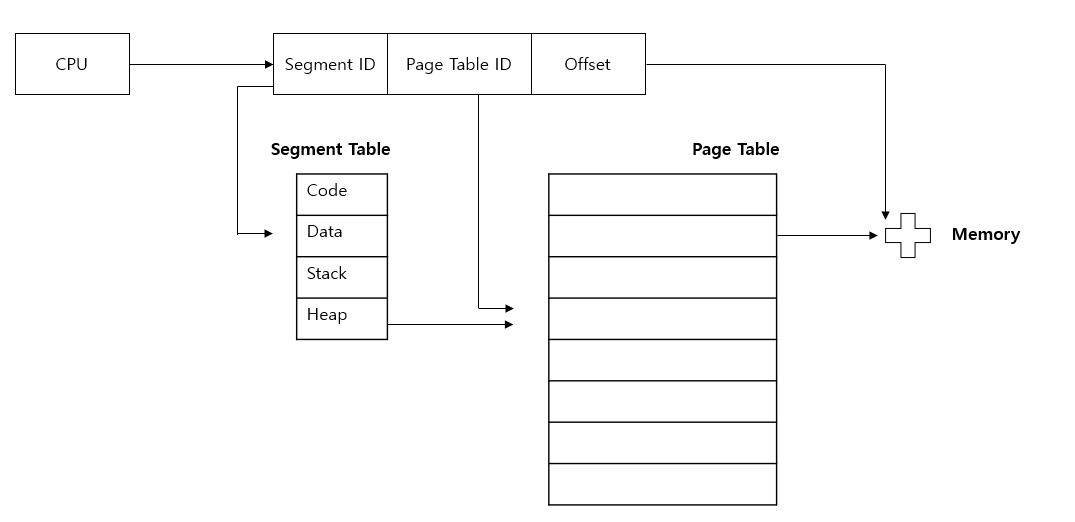
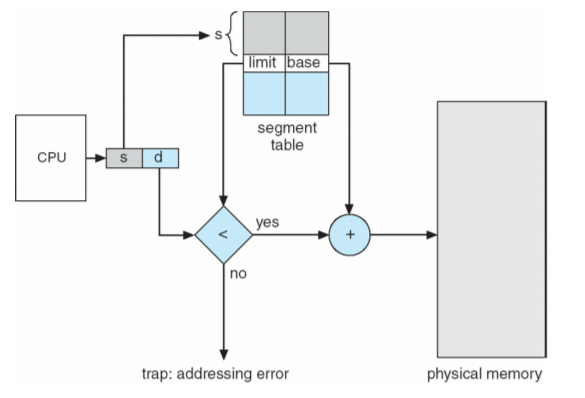
6. Segmentation
같은 크기의 물리적 공간으로 구분하는 것이 아닌, 크기다 다르더라도 논리적 단위로 구별하는 방식을 말합니다. 이에 따라 내부 단편화 문제는 해결했지만 외부 단편화 문제는 존재 합니다. 이때, 세그먼트마다 크기가 달라 다른 프로세스의 영역을 침범할 가능성이 높아 에러체크는 필수입니다. 에러체크는 Segment Table을 통해 진행합니다. (base : 항목 별 세그먼트 시작 주소 / Limit : 항목별 세그먼트 길이)
예를 들어, 개발자는 자신의 프로그램을 물리적 특성이 강한 페이지로 인식하기 보다는 함수는 함수로, 클래스는 클래스로 즉 모듈별로 인식합니다. 또한 같은 프로그램을 사용하고 내부 데이터가 다른 프로세스를 사용하는 경우에서는 필요 부분의 세그먼트 공유가 가능하여 메모리를 효율적으로 사용할 수 있습니다. 또한 데이터, 힙 영역과 같이 주요 데이터는 '정보 보호'를 통해 보안에 신경 쓸 수 있습니다.
즉, 의미있는 단위로 나누게 되어 정보 보호와 정보 공유의 이점이 존재합니다.
7. Segmentation과 Paging을 혼합한 메모리 관리
현재는 Sementation과 Paging을 혼합하여 각각이 가진 장점을 활용합니다.
먼저 프로세스를 세그먼트 단위로 잘라, 의미있는 단위로 구분합니다. 이에 따라 '정보 보호', '공유'의 이점이 생깁니다. 하지만 외부 단편화 문제가 생길 수 있습니다. 따라서 우리는 잘라진 세그먼트를 다시 페이지 단위로 구분하는 페이징을 취합니다. 이 경우 외부 단편화 문제 또한 해결할 수 있습니다. 하지만 테이블을 두번 거쳐 속도의 단점이 발생합니다.