1. For a Read Heavy System - Consider using a Cache
읽기가 많은 시스템의 경우 캐시를 고려해보세요.
- 읽기 요청이 올 때마다 메인 저장소를 들리는게 아니라 메인 저장소의 자주 접근하는 데이터를 캐시에 올리면, 메인 저장소의 부하도 줄이고 읽기 속도도 향상된다.
- 캐시를 처리할 경우 데이터 용량도 고려해야하며, 어쩔 수 없이 메인 저장소 <-> 캐시 사이의 sync가 맞지 않는 케이스가 발생할 수 있다. 따라서 필요한 데이터만을 캐시에 올리고 데이터 갱신 주기를 고려해야한다.
- 저장소 속도 예시) 분산 서버 당 Local Cache(Memory) -> External In-Memory(외부 서버의 Memory) -> DISK 조회 시스템(MySQL, Oracle, MongoDB etc) -> Hive(Hadoop)
- 결국 캐시에 데이터를 어떻게 올릴지가 고민된다. 복잡한 연산일 경우 배치로 올릴 수 있고 혹은 특정 이벤트를 받을 때 올릴 수도 있다. 이 부분은 상황에 맞게 판단하자.
- 몇가지 예시
- 사용자 테이블에서 자주 조회하는 유저의 데이터는 Redis에 올린다. 특정 사용자의 정보 변경시 해당 레디스에도 데이터를 업데이트한다.
- 메인 홈페이지의 방문자 수를 획득하는 API가 있다. 해당 페이지의 접근이 많아 매번 레디스에 데이터를 업데이트하기엔 레디스에 부하가 있다. 방문자 수가 꼭 정확하지 않아도 된다면 분마다 메인 저장소에서 레디스에 데이터를 업로드 후, 방문자 수 획득 API는 레디스에서 처리한다.
- 자주 사용하는 데이터(직업 코드 값)를 LocalCache에 업로드 하고, 10분마다 데이터를 갱신한다.
MainDB vs Read DB
- 반드시 캐시가 아니어도 RDBMS에서 ReadDB를 구축함으로 읽기 작업을 향상시킬 수 있다. Create/Read/Update/Delete 작업을 Main DB에서 처리하되 Only Read DB들을 별도로 구축한다.
- Read DB는 주기적으로 Main DB에서 데이터를 동기화 받고, 여러개로 Load Balancing하게 구축하면 읽기 작업을 여러 Read DB서버에서 처리하여 Main DB의 부하도 줄이고 읽기 작업도 크게 향상된다.
- 단, 데이터의 sync가 어느정도 부정확해도 괜찮은 시스템에서 허용한다.
대부분의 시스템은 읽기 작업이 많고, 자주 읽는 데이터를 빠른 저장소에 올려서 요기에 접근하자.
2. For a Write-Heavy System - Use Message Queues for async processing
쓰기가 많은 시스템의 경우 - 비동기 처리를 위해 메시지 큐 사용
Write 작업을 비동기로 처리한다면?
- 메인 작업과 write 작업을 분리하면 메인 작업의 응답 시간이 개선된다. 무거운 write 작업을 큐에 던지고 응답하기 때문이다. write 작업과 메인 작업을 분리 했으니, 각각의 부하가 심한 시스템만 개별적으로 확장이 가능하다.
- write 작업에 이슈가 발생해도 메인 작업에 영향이 없고, 메시지 큐에 저장된 것을 다시 consume 하여 write하면되니 데이터 손실 역시 최소화 할 수 있다.
- write 작업 뿐만 아니라 전체 시스템에서 sync로 처리 하지 않아도 되는 무거운 작업(혹은 불안정한 시스템에 의존성 있는 것)은 별도로 비동기로 처리하는게 좋다. 하나의 작업에 무거운 여러 작업이 있다면 각 작업에 coupling이 강해 각 무거운 job에 의한 장애, 개별적인 확장 등에 어려움이 있다.
메시지 큐
- 메시지 큐란 각 컴포넌트 간에 비 동기적으로 메시지를 교환하는 방식이다.
- Producer, MessageQueue, Consumer로 구성된다.
- Producer : 메시지를 생성하고, 메시지 큐로 보내는 주체다.
- MessageQueue : 메시지가 일시적으로 저장되는 큐다.
- Consumer : Message Queue에서 메시지를 소비하는 주체다.
- Producer가 Consumer한테 메시지를 직접 보내느게 아니라 Message Queue를 거쳐서 보냄으로, Producer, Consumer가 느슨하게 결합된다.
- Consumer에 이슈가 발생해도 Producer는 신경쓰지 않고 MessageQueue에 produce하면된다. 만약 producer에 트래픽이 폭주하더라도 Message Queue에 데이터가 쌓이지, consumer는 필요한만큼만 메시지를 consume하면된다. 이로써 각 컴포넌트는 독립적으로 확장할 수 있고, 변경할 수도 있다.
- 즉, producer/consumer는 서로의 내부 사정을 신경 쓰지 않고 메시지 큐만 바라본다. 특정 서비스에서 여러 서비스와 연동돼있고 coupling이 심하다면 유지보수, 확장 시 신경쓸게 너무 많다. 하지만 메시지 큐를 사용한다면 모든 연관부서는 데이터 연동시 메시지 큐만 바라보고 produce/consume하면 된다.
- 그렇다고 메시지 큐가 은총알은 아니다. 데이터 복구 기한은 메시지 큐에 데이터가 얼마나 보관되냐에 달려있다. 또한 메시지큐에 무한정 데이터를 저장할 수 없기 때문에 lag가 쌓이면 고것도 어떻게 처리할지 고려해야한다. 또한, 비동기적으로 데이터를 consume하다보니 예상치 못한 시나리오도(대표적으로 트랜잭션 처리) 발생하고, 동기적으로 처리가 필요한 케이스에서는 consume 시점에 lock을 고려하기도 한다.
- Ex) RabbitMQ, Kafka, Amazon SQS, ActiveMQ
결국 쓰기와 같이 무거운 작업 혹은 불안정한 시스템에 의존하는 모듈은 별도로 뺴서 비동기로 처리하는게 유지보수/확장 관점에서 유리하다. 예상치 못한 시나리오(ex 트랜잭션)가 발생할 수 있다. 이때, 비동기로 데이터를 보내는 방식 중 하나가 메시지 큐다.
3. For a Low Latency Requirement - Consider using a Cache and CDN
짧은 지연 시간이 필요한 경우 - 캐시 및 CDN 사용을 고려하세요.
Content Delivery Network
- CDN은 여러 지역 서버에 원본 서버의 컨텐츠를 캐시한다. 사용자가 컨텐츠르 요청하면 CDN은 해당 요청을 받아 지리적으로 가장 가까운 CDN 서버에서 캐시된 컨텐츠를 제공한다. 먼 원본 서버로 가지 않고 캐시된 데이터를 제공하니 응답 속도도 좋아지고 원본 서버의 네트워크 트래픽을 줄여준다.
- 이 역시 원본 서버의 캐시된 데이터를 사용하니 sync가 맞지 않다. original 서버의 컨텐츠 변경 시 데이터를 갱신하거나 일정 주기로 데이터를 갱싱해야한다.
- Ex) image, css 등 자주 바뀌지 않으나 자주 접근하는 컨텐츠
이미지, 문구 와 같이 자주 바뀌지 않으나 여러 지역에서 자주 접근하는 컨텐츠는 CDN 서비스를 활용하자.
4. Need Atomicity, Consistency, Isolation, Durability Compliant DB - Go for RDBMS/SQL Database
정합성, 일관성, 격리성, 내구성 준수 DB가 필요한 경우 - RDBMS로 이동합니다.
- Atomicity(정합성) : 저장된 데이터가 규칙/제약 조건을 준수함을 의미한다. 즉, 이상한 데이터 없이, 안전한 데이터다. RDBMS는 각 컬럼마다 하나의 데이터를 저장할 수 있는데 해당 컬럼의 '제약조건', 'PK', '외래키'등으로 데이터 정합성을 유지할 수 있다. 예를 들어, data type, size, 특정 데이터만 insert, not null, 정규화를 통한 일관된 데이터 제공 등이 있다.
- Consistency(일관성) : 트랜잭션으로 여러 작업을 묶어, 데이터의 일부만 변경됨을 방지한다. 만약 중간에 이슈가 발생하면 전체가 롤백되고, 모든 작업 성공시 커밋된다. ex) 은행 송금 처리
- Isolation(격리성) : 여러 트랜잭션이 동시에 실행되고 하나의 테이블에서 CRUD할 때, 각 트랜잭션이 다른 트랜잭션에게 영향을 최소화 할 수 있다. Isolation Level에 따라 성능 <-> 격리성을 trade-off 할 수 있다.
- Durability(내구성) : 시스템이 고장나더라도 데이터는 영구적으로 보관된다. data 이중화를 통해 데이터를 안전하게 보관한다.
잘못된 데이터가 들어가지 않게, 엄격한 데이터 관리가 필요할 경우 RDBMS를 고려하자.
5. Have unstructed data - Go for NoSQL Database
비정형 데이터 보유 - NoSQL DB로 이동한다.
- JSON 포맷과 같이 비정형 데이터는 NoSQL을 활용한다. 데이터 포맷이 달라지더라도 저장 포맷을 변경할 필요 없다. 키에 맞는 데이터를 노출하여 단순 insert, select 시 성능이 좋다.
- 정규화된 데이터를 제공하지 않아 일부 데이터만 update할 수 있어 신뢰성 있는 데이터 제공이 힘들다.
'데이터 포맷'이 자주 변경되는 비정형 데이터의 경우 '엄격한 데이터' 관리가 필요하지 않다면 NoSQL 제공도 훌륭한 방식이다.
6. Have Complex Data (Videos, Images, Files) - Go for Blob / Object Storage
복잡한 데이터 (동영상, 이미지, 파일)가 있는 경우 블롭/객체 스토리지로 이동한다.
- Blob(Binary Large Object)은 주로 동영상, 이미지, 파일과 같이 크기가 크고 구조화된 파일/데이터를 의미한다.
- blob 객체 스토리지는 데이터를 객체로 저장하며, 각 객체는 고유한 식별자, 데이터, 메타 데이터를 가진다. 이는 대량의 비정형 데이터를 저장하고 관리하기 위해 제작된 클라우드 기반 스토리지 서비스다.
- 예를 들어, 파일을 저장할 때 blob 객체 스토리지 서비스에 파일을 올리고 해당 url을 db 에 저장한다.
파일과 같이 크기가 큰 데이터를 blob 객체 스토리지 서비스를 이용하자.
7. Complex Pre Computation - Use Message Queue & Cache
복잡한 사전 계산이 필요한 경우 - 메시지 큐 및 캐시를 사용하세요
- 여기서 말하는 복잡한 사전 계산이란 시간이 오래 걸리거나 많은 자원이 필요로 하는 처리를 의미한다. ex) 대용량 데이터를 읽어서 처리하거나 복잡한 알고리즘을 처리한다. 이렇게 리소스가 많이 드는 작업을 기존 시스템에서 처리하면 영향도가 커지고 앞으로 복잡해지기만 한다. 따라서 부하가 심한 job을 백그라운드에서 처리하면 기존 시스템의 영향도를 최소화할 수 있다.
- 이렇게 계산한 결과를 캐시에 저장하여 이후에 동일한 계산이 요청됐을 때 다시 계산하지 않고 캐시된 데이터를 사용하여 성능을 향상 시킬 수 있다. 꼭 메시지 큐 뿐만 아니라 사전에 데이터 계산이 가능할 경우 일/월/년 배치로 미리 작업을 계산하고 캐시에 데이터를 넣어 시스템의 성능을 향상시킬 수 있다.
무거운 작업은 백그라운드에서 처리하고, 키를 잘 정의해서 캐시에 올리면 매번 계산할 필요가 없어진다.
8. High-Volume Data Search - Consider Search Index, Tries or Search Engine
대용량 데이터 검색 - RDBMS Index, Tries 자료구조, Search Engine 서비스를 고려하세요.
Index
- RDBMS를 사용한다면 샤딩, 인덱스를 적용시켜 검색 속도를 향상시킬 수 있다.
- '책 목차'처럼 인덱스를 적용시켜 검색을 위한 별도의 테이블을 생성할 수 있다. 물론 모든 검색에 우위가 있는 건 아니고, 데이터 중복도가 낮은것 / prefix가 적용된 케이스에서 좋다. 인덱스 특성에 따라 다르겠지만 내부적으로 B tree로 구현된 시스템이라면 비슷하다. 애매하면 query plan에서 인덱스가 잘 타는지확인하면 된다.
- join절에서 자주 발생하는 컬럼에 인덱스를 추가하면 좋고, PK는 Clustered Index로 기적용된다.
- 인덱스라는건 결국 인덱스트 테이블을 생성하기 때문에, 데이터를 더 사용하고 대용량의 인덱스를 추가할 경우 오랜 시간이 걸리기도한다.
Tries 자료구조
- 문자열을 저장하고 효율적으로 탐색하기 위한 '트리'형태의 자료구조다.
- 우리가 검색할 때 볼 수 있는 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화되어있는 자료구조라고 한다.
Search 엔진
- 대량의 데이터에서 원하는 정보를 검색하고 반환하는 SW다. 다양한 기술을 사용하여 데이터를 색인하고 검색 쿼리를 처리한다. ex) Elastic Search
9. Scaling SQL Database - Implement Database Sharding
SQL DB 확장 - DB 샤딩을 구현합니다.
- 샤딩은 대량의 데이터를 특정 규칙에 따라 '수평'으로 분할하여 여러 서버에 분산 저장하는 기술을 말한다. 샤딩을 통해 DB의 부하를 분산시키며, 수평으로 분할하여 확장에 용이하다. 다음은 사용 예시다.
- 로그성 데이터를 일자별로 분할하여 저장한다. 조회 일자만 알면(샤딩 키) 빠르게 데이터를 조회할 수 있고, 파티션별로 주기적으로 데이터를 삭제할 수 있다.
- USER 라는 테이블에서 유저의 지역별로 분산 저장할 수 있다. 혹은 자주 조회하는 데이터를 분산 저장할 수 있다. ex) 자주 검색되는 연예인 정보
- 그렇다고 샤딩이 무조건 좋은건 아니다. 데이터를 분산 저장하여 추가 인프라 관리가 필요하다. 여러 샤드에 걸쳐 있는 데이터를 조회할 경우 데이터를 'join'하는데 복잡성이 늘어날 수 있다. 샤딩된 데이터 조회/조인시 반드시 샤딩 키를 지정해줘야 데이터 조회 속도가 향상된다.
SQL DB 사용시 '부하 분산', '확장' 에 용이하기 위해 샤딩을 사용하자. 단, 샤딩된 데이터 조회시 샤딩 키를 반드시 지정해주자.
10. High Availability, Performance, & Throughput - Use a Load Balancer
고가용성, 성능 및 처리량 - 로드 밸런서를 사용하세요.
- 로드밸런서란 요청 작업을 균등하게 분배하는 시스템이다. job을 균등하게 서버에 분배하여 각 서버의 트래픽을 관리한다. 만약 요청량이 많아지면 job을 처리할 서버를 추가 등록하여(수평확장에 용이) 처리량을 높일 수 있다. 만약 요청량이 적다면 로드밸런서에 등록한 서버를 제거하면 된다.
- 만약 특정 job에 문제가 있다면 로드밸런서에서 해당 서버에 job을 주지 않아 고가용성 역시 높일 수 있다.
- DNS 서버, 프록시 서버, API Gateway 등에서 사용될 수 있다.
'고가용성', '분산 처리를 통한 높은 처리량'을 위해 로드 밸런서를 활용하자.
11. Global Data Delivery - Consider using a CDN
글로벌 데이터 전송 - CDN 사용을 고려하세요
- 전 세계 여러 지역에 위치한 서버를 통해 캐시된 데이터를 제공하여, 지리적으로 성능 향상을 이끌며 원본 서버의 부하를 분산시켜준다.
- 물론 캐시된 데이터를 제공하니 sync가 안맞는 문제는 여전히 발생할 수 있다.
12. Graph Data (data with nodes, edges, and relationships) - Utilize Graph Database
그래프 데이터(노드, 에지 및 관계가 있는 데이터) - 그래프 DB를 활용하세요
- Graph Data란 Node, Edge로 구성된 데이터로, Node는 객체를 나타내고 Edge는 Node 사이의 관계를 나타낸다. 예를 들어, SNS에서 사용자가 노드고, 친구 관계가 에지로 표현될 수 있다.
- Graph DB는 노드와 에지의 관계를 효율적으로 저장하고, 노드간의 관계를 손쉽게 파악할 수 있다. 예를 들어, 특정 사용자의 친구 목록을 조회하거나, 두 사용자 간의 거리(친구를 통해 얼마나 떨어져있는지)를 계산하는 등의 작업을 수행할 수 있다.
- EX) SNS 분석, 지리 정보 시스템, 네트워크 분석(Routing)
13. Scaling Various Components - Implement Horizontal Scaling
다양한 컴포넌트 스케일링 - 수평 스케일링을 구현합니다
- 애플리케이션의 성능을 향상 시키는데 수평 스케일링, 수직 스케일링이 있다. 컴포넌트를 스케일링할 때 비용, 고 가용성을 위해 수평 스케일링을 권장한다.
Horizontal Scaling (수평)
- 시스템의 성능을 높이기 위해 여러 인스턴스를 추가하여 부하를 분산하는 방법이다. 이는 단일 인스턴스의 성능 합계를(H/W 업그레이드) 초과하거나 시스템의 고가용성을 높이기 위해 사용된다. 이를 위해 새로운 서버 등록/삭제 수행 시 로드밸런서에 등록/삭제 하면 된다.
- 다만 요청 처리를 분리된 서버에서 진행하다보니 복잡성이 증가할 수 있다. 각 서버에서 로컬 캐시를 사용할 때 sync가 안맞는 문제, 각 서버의 모니터링 등의 복잡성 문제, 로드밸런서가 이중화되지 않았을 때의 단일지점 장애 포인트가된다.
Vertical Scaling (수직)
- 시스템의 성능을 높이기 위해 단일 서버의 H/W 성능을 업그레이드 함을 의미한다. 서버의 CPU, 메모리, 디스크 등의 H/W를 업그레이드하여 단일 서버에서 더 많은 부하를 처리할 수 있다.
- 복잡하진 않지만, 물리적으로 업그레이드에 한계가 있고 서버 장애 시 시스템 전체가 영향을 받을 수 있다.
성능을 높이기 위해 '고가용성', '비용' 측면에서 '수평 스케일링'을 활용하자.
14. High-Performing Database Queries - Use Database Indexes.
고성능 DB 쿼리 - DB 인덱스 사용하기
- RDBMS에서 검색이 필요로하는 쿼리 사용시 '인덱스'를 활용한다. 쿼리 실행시 테이블당 하나의 인덱스가 사용되며, 복합 인덱스 설정 시 필드 데이터 중복도가 높은 순서로 설정함을 권장한다. ex) age > name > id 예측한데로 인덱스가 안탈 수 있어, 쿼리 플랜에서 인덱스가 잘 타는지 꼭 확인해보자.
- 인덱스는 내부 구현이 B+Tree로 구현되 있어 'TEST%', 특정 필드의 join, column >= 10, column = 'test'과 같은 경우엔 인덱스가 탈 수 있지만 '%TEST', 테이블 row 양에 따라 안타는 경우도 있다.
- 인덱스 생성시 인덱스를 위한 테이블이 별도로 생성되니 무조건 만들기 보단, 적절한 인덱스 테이블 생성이 필요하다. 또한, 테이블 양에 따라 컬럼, 인덱스 수정에 많은 시간이 소요될 수 있다.
- 어드민에서 여러 검색 조건을 조합할 때 여러개의 인덱스 생성이 필요한데(검색 필드가 5개면 최대 2^5=32개) 이렇게 많은 인덱스를 생성하기엔 부하가 있다. 따라서 필드의 중복도가 높은것 (성별)은 굳이 인덱스를 추가 안해도 되며, 몇개 검색조건은 하나의 인덱스를 태울수 있도록 설정해도 좋다. 혹은 필요시 검색 조건을 제한하여 성능 제한을 둘 수도 있다. (특정 검색조건은 몇개월치만 데이터 조회) 즉, 인덱스가 굉장히 좋은 기술이지만, 무조건 만들기보단 필요한 것 위주로, 안된다면 제한조건을 두는것도 하나의 방법이다.
RDBMS에서 검색을 위해 인덱스를 활용한다. 단, 무조건적으로 인덱스 테이블을 생성하기보단 '중복도', '제한조건'도 함께 고려해보자.
15. Bulk Job Processing - Consider Batch Processing and Message Queues
대량 작업 처리 - 배치 처리 및 메시지 큐를 고려합니다
대량 작업이 필요한 경우 H/W 리소스도 많이 사용하고, 시간도 오래 걸릴 수 있다. 따라서 이러한 job들을 메인 서버가 아닌 백그라운드에서 처리한다.
Batch
- 주기적으로 대량 작업이 필요할 경우 메인 서버가 아닌 batch 서버에서 주기적으로 job을 처리한다. 예를 들어, 사용자의 하루 통계 데이터가 필요하다면 매일 새벽 1시에 스케줄러 job을 등록하고 job을 실행한다.
- spring batch는 보통 Read -> Process -> Write 작업 순으로 실행되는데 MySQL에서 Read할 때 한번에 너무 많은 데이터를 조회하면 timeout exception이 발생할 수 있다. 혹은 쿼리 join시 한번에 너무 많은 양을 조회하면 성능 이슈가 발생할 수도 있다. 따라서 'pagination'으로 끊어서 데이터 조회가 가능하다. 다만 끊는 데이터 양이 너무 작다면 데이터 통신이 빈번하게 일어나기 때문에, 적절한 paging 갯수를 설정하자.
- pagination을 구현할 때 limit으로 끊으면 limit의 번호가 끝으로 갈수록 성능 이슈가 발생할 수 있다. 따라서 WHERE 절에 이전에 읽은걸 방지하는 조건을 둠으로 성능을 향상시킬 수 있다.
Message Queue
- 주기적으로 job을 처리하는게 아니라 특정 이벤트에 의해 대량 작업을 처리한다면 메시지 큐를 활용한다. 메인 서버에서 처리하지 않고, message queue에 메시지를 푸시하고, 별도의 백그라운드 서버에서 consume해서 작업을 처리할 수 있다.
- 메인시스템과 대용량 작업 처리가 동기적으로 처리될 필요가 없다면 coupling을 끊는게 '영향도', '확장' 측면에서 좋다. 물론, 비동기적으로 처리되다보니 예상치 못한 시나리오가 발생할 수 있다. ex) 작업이 순서대로 실행되는게 아니라 뒤죽박죽 실행, 같은 트랜잭션으로 묶이지 않았기 때문에 일부만 롤백되는 케이스
- 만약 대용량의 데이터 작업이 필요하면 꼭 mysql이 아닌 하둡에 데이터를 적재하고 이를 mapreduce하는 spark-batch를 고려해 보는 것도 좋다.
대량 작업 처리시 백그라운드에서 처리하되, batch/message queue 시스템을 고려해보자.
16. Server Load Management & Preventing DOS Attacks - Use a Rate Limiter
서버 부하 관리 및 DOS 공격 방지 - 속도 제한기를 사용하세요
- 속도 제한기는 서버에 대한 '요청 속도'(단위 시간 당 요청량)를 제한함으로써 과도한 트래픽으로 인한 부하를 완화하고, 악의적인 공격을 방지하는데 도움이 된다. 참고로 DOS란 특정 서버에 트래픽을 강제로 몰리게 하여 서버를 마비시키는 공격이다.
- Rate Limiter 예시
- 서버에 도착하는 요청 속도를 제한함으로, 허용 가능한 속도 이상의 요청을 거부한다. 이를 통해 서버가 과도한 부하에 시달리는 것을 방지한다.
- 특정 IP 주소에서 너무 많은 요청이 발생하는 경우 해당 IP 주소를 차단하거나 요청을 거부하는 것이 좋다.
- User-Agent 헤더 또는 쿠키를 사용하여 클라이언트를 식별하고, 이를 통해 특정 사용자의 요청을 제한하는것이 가능하다.
- 사람이아닌 자동화된 스크립트로 DOS 공격이 올 수 있는데, 'CAPTCHA' 라는 기술로 사람/시스템의 부하를 구별할 수 있다.
- 당연히 지속적으로 서버의 트래픽을 모니터링하고, 감사와 로깅을 주기적으로 체크해야한다.
- 속도 제한기를 구현하는 방법은, 웹 서버에 내장된 기능으로 제한하거나 경우에 따라 특별한 애플리케이션을 추가 하기도한다. 혹은 특정 서비스 제공업체를 활용할수도 있다.
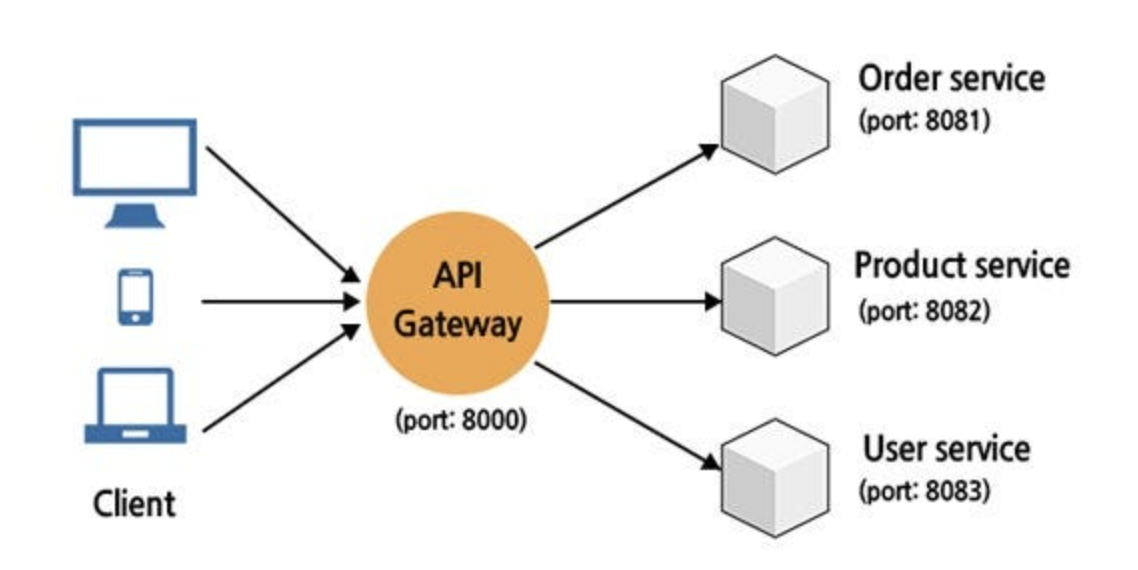
17. Microservices Architecture - Use an API Gateway
마이크로 서비스 아키텍처- API Gateway 사용 권장
Microservice
- MSA는 시스템을 독립적인 서비스로 분해하여, 개발하는 방식이다. 큰 모듈에서 작은 모듈로 분해하니, 작은 모듈의 '배포', '확장', '유지보수', 'R&R이 명확하니 기획/개발간 협업'의 장점이 있다.
- 이는 물론 각 서비스간 '의존성'과 '서비스의 경계'가 명확히 구별 했을 때의 장점이다. 이를 명확하지 않았을 경우 다른 팀의 '배포'에 영향 받고, 쉽게 유지 보수하기도 힘들다. 만약 분리된 서비스가 다른 팀이라면 협업도 힘들며 복잡성만 늘어난다.
API Gateway
- Gateway란 네트워크에서 서로 다른 프로토콜 간의 통신을 중개하거나 변환하는 장치다. 이는 두 개 이상의 시스템 또는 네트워크 간 통신을 가능하게 한다. API Gateway란 클라이언트와 여러 백엔드 서비스 간의 통신을 관리하는 서비스로 MSA 아키텍처에서 많이 사용된다.
- 클라이언트 <-> 각 서비스의 결합도 완화
- 클라이언트와 MSA 사이의 API Gateway를 둠으로써 분할된 MSA 정보를(ex 위치) 숨길 수 있다. 클라이언트는 모든 MSA에 대한 호출 대신 API Gateway에 대한 호출만을 관리한다. 또한 MSA 분할, 인스턴스 수 변화, 위치 등의 변화가 쉽다. 이는 Client와 MSA 간 결합도가 낮아 가능하다.
- 프로토콜/응답값의 decoupling
- 클라이언트와 MSA의 결합도가 낮아, 프로토콜이 달라도 API Gateway에서 변환할 수 있고, MSA의 응답값이 xml이여도 API Gateway에서 json으로 변환할 수 있다.
- 공통 로직
- API Gateway는 MSA에서 '단일 인증 포인트'다. 따라서 공통 로직을 API Gateway에서 처리하면 때문에 서비스 전체에 '표준화'된 공통 로직을 제공하며, 각 서비스의 중복 로직을 제거한다.
- 대표적으로 인증/인가 서비스가 있다.
- 인증 : 해당 사용자가 본인이 맞는지를 확인하는 절차
- 인가 : 인증된 사용자가 요청한 자원에 접근 가능한지를 확인하는 절차
- 메트릭 지표 수집
- 모든 요청이 API Gateway를 거치기 때문에, 로깅 및 데이터 수집이 용이하다.
- API Gateway가 단일 지점 포인트기 때문에, 단일 실패 지점이 될 수 있다. 이를 위해 이중화 등 고가용성을 위한 설정이 필요하다. [Q] API Gateway에 모든 인입점이 되는데 요 녀석이 모든 트래픽을 감당할 수 있나? 인증/인가 처리하는 등 공통 로직을 단순히 하면 오래 안걸리나?
- 파드, 쓰레드 당 요청 얼마나 받을 수 있는지
클라이언트와 MSA간 통신이 일어날 때, '결합도'를 낮추고 '표준화된 공통 로직'을 위해 'API Gateway'를 활용하자.
18. For Single Point Of Failure - Implement Redundancy
단일 장애 지점 - 이중화 구현
SPOF(Single Point Of Failure)
- 시스템 구성 요소중에서 동작하지 않으면 전체 시스템이 중단되는 요소를 말한다.
- 스위치/라우터와 같이 네트워크 통신에 의한 중단
- 데이터 센터의 전원 공급 장치에 의한 중단
- 단일 웹서버일 경우 해당 서버 인프라 장애 혹은 SW 버그에 의한 중단
- DB 서버 전체 장애 발생 시 해당 DB를 이용하는 전체 서비스가 중단
- 클라우드 서비스에서 단일 지점 포인트 (ex- API Gateway)가 장애 발생할 경우 해당 클라우드를 이용하는 전체 서비스가 중단된다.
이중화 (Redundancy / High Availability=HA)
- 고가용성이란 장애가 생기더라도 빠르게 복구할 수 있는 시스템을 말한다. 완벽히 중단 시간을 없게는 못하겠지만, 최대한 중단 시간 없이 운영할 수 있는 성질을 말한다.
- 이중화는 각종 자원(하드웨어, OS, 미들웨어, DB 등)을 중복으로 구현하여 시스템의 가용성을 높이는 방식이다. 시스템에 문제가 있어도, 문제 없는 다른 시스템으로 대체하여 고가용성을 높일 수 있다.
- 장애 또는 재해시(서비스의 일시적 중단이 발생) 재빠르게 교체하기 위해 사용한다. 혹은 일정량 이상의 트래픽을 처리할 경우 응답시간이 느려져, 원활한 서비스의 성능을 보장하기 위해 로드밸런싱을 목적으로 한다.
- 서버 이중화 전략 방식
- Active-Standby : 평소엔 특정 서버에서 서비스를 운영하고, 해당 서버 장애 발생 시 대기 중이던 서버를 사용하여 대응하는 전략이다. Active 서버는 데이터의 업데이트가 있을 때마다 Standby서버로 전달하여 데이터를 동기화하고 장애 발생 시 그 즉시 투입 가능한 상태를 유지한다.
- Active-Active : 서로 다른 서버가 모두 서비스를 운영하는데 어느 하나에 장애가 발생하면 나머지가 서비스를 제공하게 되는 구조다. Active Standby보다 높은 처리량과 고가용성을 제공하고, 비용이 더 많이 들어간다. (A-S는 하나가 down되있으나, A-A는 모두 ON 돼있음)
완전한 다중화
- 인프라 : 인프라 영역은 전력, 네트워크 등 물리적인 공간으로 인터넷 서비스를 위한 영역이다. 예상치 못한 크고 작은 사고가 발생한다. ex) 화재, 포트가 빠진다거나 등. 그렇기 때문에 다양한 failover 설계를 해둬야한다. failover라는 건 문제가 생겼을 때 예비 시스템으로 자동 전환되는 기능을 말한다.
- 데이터 : DB와 같이 데이터를 다루는 영역이다. 실시간 이/삼중화를 통해 데이터가 유실되지 않게 백업해둔다.
- 운영 및 관리 도구 : 실제 서비스 트래픽을 받는 부분은 아니지만, 서비스 운영에 필요한 여러가지 기술적 도구들을 말한다. 배포, 모니터링, 권한관리 등을 위한 도구다. 이상적으론 다른 layer에서 다중화 구성만으로 장애 시 대응이 되어야 하지만 현실은 그렇지 않고, 예상치 못한 여러 상황이 벌어지기 때문에 배포 도구와 같은 운영관리 도구가 전체적인 서비스 복구 시간을 빠르게 도와준다.
- 서비스 플랫폼 : 서비스가 공통적으로 사용하는 플랫폼 영역 다. 보안키 저장소, 레디스, 카프카 등 공용 솔루션을 말한다.
- 어플리케이션 : 실제 사용자에게 서비스하기 위한 소프트웨어 영역이다. 작은 장애가 다른 어플리케이션에 번질 수 있기 때문에 전략적으로 다중화를 진행해야한다.
DR (Disaster Recovery)
- 이중화 요소를 갖췄다면 자연스레 장애 발생시 대처가 되지 않나 생각하지만, 만약 HA를 구성한 데이터 센터에 화재와 같은 큰 재해가 발생한다면 그 데이터 센터 내에 아무리 백업 서버를 두고 이중화를 잘 해놨다고 해도 아무 소용이 없다.
- DR 센터란 서로 전혀 다른 지역에 재해 시 복구할 수 있도록 동일한 센터를 하나 더 만드는 것을 의미한다. 그리고 소산 백업이란 데이터만 백업하되, 그 백업 데이터가 같은 데이터 센터에 위치해 있으면 재해 시 유실되는 건 똑같으니까 물리적으로 다른 곳에 백업데이터를 두는 백업 방식이다.
- 이론적으론 아래의 복구 전략을 수립해야한다. 다만 별도의 DR센터를 구축했을 때 리소스(시간/비용/개발)에 많은 투자가 필요해서 적절한 HA/DR을 구축해야한다.
- 서버가 장애났을 경우를 대비해서 HA 이중화 구성
- 백업 데이터까지 날라갈 경우를 대비해서 소산백업
- 재해 발생 시 빠르게 복구해야하는 경우 실시간으로 바로 서비스 재개가 가능한 DR 센터 구축
장애를 빠르게 복구하기 위해 HA(이중화)를 구축하며, 재해에 대비하여 DR 센터를 별도로 구축하면 고가용성을 제공할 수 있다. 다만, 많은 리소스가 들기 때문에 상황게 맞게 판단하자.
19. For Fault-Tolerance and Durability - Implement Data Replication
내결함성 및 내구성 - 데이터 복제를 구현하세요
- 시스템이 HW, SW 문제로부터 손상을 입었을 때, 시스템의 중단 없이 계속 작동되길 원한다. 특정 데이터 센터에 문제가 있거나 혹은 DB에 문제 발생 시 이러한 현상이 재현된다. 따라서 데이터 복제를 통해 문제 있는 DB가 다른 DB로 대체하여 시스템 중단 없이 계속 작동할 수 있게한다.
- 문제있던 DB에서 다른 DB로 대체되고, 문제있던 DB가 정상화되면 sync를 맞춰주는 작업이 추가적으로 필요하다. 뿐만 아니라 추가 장비를 통해 비용/복잡성 측면에서 리소스가 더 늘어난다. 하지만 고가용성이 중요한 서비스에서는 '이중화' 및 '데이터 복제'는 중요한 과제다.
20. For User-to-User fast communication — Use Websockets
사용자 간 빠른 통신을 위해 - 웹소켓 사용
- 기본적으로 HTTP 통신은 한번 연결을 맺고, 일정 시간 통신이 없을 경우 연결을 close한다. 하지만 웹소켓은 클라이언트와 서버 사이의 지속적인 연결을 제공한다. 이에 따라 웹소켓은 실시간 데이터를 양방향으로 전송할 수 있다.
21. Failure Detection in Distributed Systems - Implement a Heartbeat
분산 시스템에서의 장애 감지 - 하트비트 구현
- 분산 시스템의 다른 구성 요소 또는 노드 간에 주기적인 신호를 보내고 받아서 서로가 여전히 작동 중임을 확인하는 데 사용된다. 일종의 "살아있다" 메시지로 볼 수 있다. 만약 노드가 일정시간(timeout)안에 하트비트를 수신하지 못하면 다른 노드로부터 해당 노드의 장애를 감지할 수 있다.
22. Data Integrity - Use Checksum Algorithm
데이터 무결성 - 체크섬 알고리즘 사용
- 체크섬 알고리즘은 데이터가 정확/안전한지 검증하는데 사용된다. 데이터가 전송되거나 저장될 때, 체크섬 알고리즘은 데이터의 일부분을 사용하여 고유한 체크섬 값을 생성한다. 이 체크섬 값은 데이터가 손상되었는지 여부를 나타내는 일종의 데이터 지문으로 볼 수 있다. 데이터를 수신하는 측에서 동일한 알고리즘을 사용하여 수신된 데이터의 체크섬 값을 계산하고, 이를 원본 체크섬 값과 비교하여 데이터의 무결성을 확인한다.
- 이러한 방식으로 체크섬 알고리즘은 데이터 전송 및 저장 과정에서 발생할 수 있는 오류를 탐지하고 보정하여 데이터 무결성을 유지한다. 이는 파일 전송, 테크워크 통신, 디비 관리 등에서 사용된다.
23. Efficient Server Scaling - Implement Consistent Hashing
효율적인 서버 확장 - 일관성 해싱 구현
- 분산 시스템에서 해싱은 여러 스토리지 서버 간에 데이터를 분할하여 저장/탐색하기 위해 사용된다. 목표는 데이터가 각 서버에 균일하게 분포하고, 서버의 추가/제거시 데이터의 재분배가 많이 일어나지 않으면 좋겠다.
- 단순 해싱은 단순하고 직관적이지만, 서버의 추가 또는 제거 시에 데이터의 재분배가 많이 필요하다. 예를 들어, Data(String, Json etc) -> integer 타입의 Key 획득 -> Key % (n-1) -> 해시값(서버 번호) 획득한다.
- 일관된 해싱은 서버 확장을 위한 고급 해싱 기술로, 서버의 추가/제거에 따른 데이터 재배치를 최소화한다. 해시 함수를 사용하여 데이터를 해시 값으로 변환한 다음, 해당 해시 값을 서버 집합 내의 원형 공간으로 맵핑한다. 각 서버는 이 원형 공간에서 고유한 범위를 가지고 있다. 데이터는 그 해시 값이 서버의 범위에 해당하는 서버에 할당된다.
- 서버가 추가되거나 제거될 때, 대부분의 데이터는 변경되지 않 다. 대신, 새로운 서버의 범위가 추가되고, 일부 데이터가 이에 맞게 재배치된다. (근처에 있는 데이터들) 이 과정에서 전체 데이터의 재배치가 발생하지 않으므로, 일관된 해싱은 시스템의 확장성을 향상시키고 부하 분산을 효율적으로 처리할 수 있다.
24. Decentralized Data Transfer - Consider Gossip Protocol
분산 데이터 전송 - Gossip Protocol을 고려하자
- 가십 프로토콜은 분산 시스템에서 정보를 효율적으로 전파하는 방법 중 하나이다. 핵심 아이디어는 "오는 사람이 있다면, 가는 사람이 있다"는 개념이다. 즉, 노드가 다른 노드에게 정보를 전파하면서 동시에 정보를 받아들인다. 이러한 상호작용을 통해 시스템 내의 모든 노드가 비교적 짧은 시간 내에 동일한 정보를 보유하게 된다. 만약 중간에 통신이 안되더라도, 다른 노드에 의해 정보가 동기화된다.
- 분산 DB의 복제, 분산 시스템의 동기화, P2P 네트워크에서의 파일 공유 등에서 사용된다. 이는 중앙 집중식이 아닌 방식으로 데이터를 전송하고 동기화하는데 유용하며, 노드 간에 정보를 효과적으로 분산시키는데 도움이 된다.
25. Location-Based Functionality - Use Quadtree, Geohash, etc
위치 기반 기능 - Quadtree, Geohash 등 사용해라
PASS
26. Avoid Specific Technology Names - Use generic terms
특정 기술 이름을 피하고 일반적인 용어를 사용해라
- 구체적인 기술 대신 일반적인 용어 혹은 도메인 용어를 사용하는 것은 코드를 이해하는데 유용하다. 또한, 기술에 종속성이 없기 때문에 기술 컴포넌트를 쉽게 교체할 수 있다.
27. High Availability and Consistency Trade-Off - Eventual Consistency
고가용성과 일관성의 상충 관계 - 최종 일관성
분산 시스템에서 일관성은 크게 두 가지 레벨로 나뉜다. 강한 일관성(Strong Consistency)과 최종 일관성(Eventually Consistency)이 있다.
[1] CAP 이론
- CAP 이론은 분산 시스템에서 일관성(Consistency), 가용성(Availability), 네트워크 분할 허용성(Partition Tolerance) 간의 trade-off를 설명하는 이론이다.
- Consistency : 모든 노드가 동일한 데이터를 동일한 시간에 볼 수 있는 것을 의미한다. 즉, 시스템의 모든 복제본이 항상 일관된 상태를 유지한다.
- Availability : 시스템이 항상 작동 가능케 한다. 예를 들어, 데이터를 복제하여 main data에 이슈가 있어도 복제된 데이터를 활용한다.
- Partition Tolerance : 시스템 내의 노드들 사이에 네트워크 분할이 발생했을 때에도 시스템이 정상적으로 동작할 수 있는 것을 의미한다. ex) Load balancer가 적절한 노드를 선택한다.
- 일반적으로 CAP 이론은 Partition Tolerance은 반드시 보장되어야 하므로, 시스템은 서비스에 따라 일관성과 가용성 중에서 하나를 선택한다. Trade-Off
[2] Strong Consistency
- 분산 시스템에서 데이터를 '즉시', '정확하게' 업데이트하는 것을 말한다. 분산 시스템에서 데이터는 한 개가 아니라 가용성을 위해 복제 되있으며, 이를 위해 분산된 데이터를 대상으로 Atomic 업데이트가 필요하다. 이를 위해 각 서비스가 자신들의 데이터를 Atomic 업데이트하는 것을 기다려야한다.
[3] Eventually Consistency
- 고가용성을 확보하기 위해서는 여러 지점에 데이터를 복제하여 장애나 네트워크 문제로부터 시스템을 보호한다. 그러나 데이터를 여러 지점에 복제할 때 일관성을 유지하는 것은 어려운 문제다. 데이터를 복제한 후에도 모든 복제본이 동일한 값을 갖는 '강한 일관성'을 유지하는 것은 네트워크 지연이나 장애로 인해 비용이 많이 발생할 수 있다.
- 이에 대한 대안으로 '최종 일관성'이 제안되었다. 이 모델에서는 모든 복제본이 항상 동일한 값을 갖지 않을 수 있지만, 시감이 흐름에 따라 각 복제본이 최종적으로 동일한 값을 가질 것이라는 것이 보장된다. 즉, 일정 시간 동안 업데이트가 모든 복제본에 반영될 수 있도록 충분한 시간을 제공함으로써 최종적으로 일관성을 보장한다.
- 이러한 '최종 일관성' 모델은 고가용성을 유지하면서 일관성 문제를 완화하느 데 도움이 된다. 다만 일관성을 보장하는데 시간이 걸릴 수 있으므로, 상황에 따라 설정하자. Ex) EDA System
28. For IP resolution & Domain Name Query - Mention DNS
Ip <-> Domain 이름을 변환할 때 DNS를 사용해라
- DNS는 Domain Name System의 약자로, 인터넷에서 도메인 이름을 IP 주소로 변환하거나 반대로 IP 주소를 도메인 이름으로 변환하는 시스템이다.
29. Handling Large Data in Network Requests - Implement Pagination
네트워크 요청의 대용량 데이터 처리 - 페이지 매김 구현
- 대량의 데이터를 가져올 때 pagination 기법이 사용된다. pagination은 데이터를 여러 페이지로 분할하여 각 페이지에 일정량의 데이터를 제공하는 방법이다.
- 구현 예시
- 요청 시 시작 밑 끝 위치 지정 : 클라이언트가 데이터를 요청할 때, 요청에 시작 위치와(start) 가져올 데이터의 양을(일반적으로 페이지 크기) 지정한다.
- 서버에서 데이터 추출 : 서버는 해당 요청에 대해 시작 위치부터 일정량의 데이터를 추출한다. 만약 RDBMS를 사용한다면 limit으로 처리할 수 있으나, 페이지가 뒤로 갈수록 성능 저하가 있다. 따라서 특정 필드 기준으로 정렬되있고 where조건을 추가한다면 성능을 향상 시킬 수 있다.
select * from TEST_DB where seq >= 'start' limit 0, 20
- 다음 페이지 처리 : 클라이언트는 필요할 경우 다음 페이지에 대한 요청을 보낸다. 이때 이전 요청에서 받은 마지막 데이터의 위치를 시작 위치로 사용하여 데이터를 가져온다. 이러한 과정을 통해 전체 데이터를 순차적으로 검색할 수 있다.
30. Cache Eviction Policy — Preferred is LRU (Least Recently Used) Cache
캐시 제거 정책 - LRU(Least Recent Used) 캐시가 선호된다
- LRU (Least Recently Used) : 가장 오랫동안 엑세스되지 않은 데이터를 방출하는 방식이다. 다음은 LRU가 가장 선호하는 사유다.
- Locality Of Reference : 대부분의 응용 프로그램에서는 데이터에 대한 엑세스 패턴이 지역성을 가진다. 즉, 최근에 엑세스된 데이터가 가장 높은 확률로 미래에 다시 엑세스될 가능성이 높다. LRU 방식은 이러한 지역성을 활용하여 캐시에 가장 최근에 엑세스된 데이터를 유지함으로써 캐시 히트 비율을 높일 수 있다.
- 각 데이터의 엑세스 시간을 추적하고, 가자아 오래전에 엑세스된 데이터를 방출하므로 구현이 쉽다.
- LFU (Least Frequently Used) : 가장 적게 엑세스된 데이터를 방출하는 방식이다. 이 방식은 얼마나 자주 엑세스되는지를 추적하여 방출할 대상을 결정한다. 자주 엑세스되지 않은 데이터가 캐시를 차지하지 않도록 하기 때문에 특정 데이터 패턴에 적합할 수 있다.
- FIFO(First In, First Out) : 캐시에 추가된 순서대로 데이터를 방출한다. 가장 오래된 데이터가 먼저 방출되는 방식으로, 캐시에서 일정 시간 이상 보존되지 않아도 되는 데이터를 관리하는데 유용할 수 있다.
31. To handle traffic spikes: Implement Autoscaling to manage resources dynamically
트래픽 급증 처리 : 자동 확장을 구현하여 리소스를 동적으로 관리하세요
- Autoscaling(자동확장)은 시스템의 부하나 트래픽 변화에 따라 자동으로 컴퓨팅 리소스 (예 : 가상 머신 인스턴스)를 확장하거나 축소하여 애플리케이션의 성능을 최적화하고 가용성을 유지하는데 사용된다.
- 자동 확장은 시스템의 트래픽을 지속적으로 모니터링한다. 트래픽이 증가하거나 감소할 때 어떻게 대응할지 결정한다. 예를 들어, TPS, CPU/메모리 사용률 등 특정 임계값을 초과하면 인스턴스를 생성하고, 사용률이 다시 감소하면 인스턴스를 제거하는 정책을 세운다.
- 자동확장은 트리거가 발생하고 자원이 확장되거나 축소될 때 알람을 보내고, 해당 작업을 로깅하여 모니터링을 지원한다.
- 예를 들어, 배달 앱 서비스를 운영한다. 앱 특성상 점심/저녁 시간과 같이 특정 이벤트시점에 요청량이 몰릴 수 있다. 그렇다고 해당 서비스의 서버를 최대값으로 운영하기엔 비용이 많이든다. 따라서 필요한 시점에만 리소스를 많이 확보하고 싶다. 이럴때 autoscaling이 효과적일 수 있다.
32. Need analytics and audit trails — Consider using data lakes or append-only databases
분석 및 감사 추적 필요 — data lakes 혹은 append-only DB 사용을 고려하세요
- 감사추적 : 시스템의 사용이력, 변경이력, 데이터 생성/가공, 시스템 설정 이력 등 시스템 내에서 일어난 모든 이력에 대한 기록을 의미한다.
Data Lake
- Data Lake란 가공되지 않은 다양한 종류의 데이터를 한 곳에 모아둔 저장소의 집합이다.
- 빅데이터와 인공지능 기술의 중요성이 커지면서 다양한 영역의 다양한 데이터가 만나 새로운 가치를 만들어내기 시작했다. 이와 같이 빅데이터를 효율적으로 분석 및 사용하고자 다양한 영역의 가공되지 않은 데이터를 한 곳에 모아서 관리하고자 하는 것을 바로 Data Lake라 한다.
- Data Lake라는 개념이 나오고 데이터를 한곳에 모으기 시작하였지만 데이터 사용자는 데이터 준비 과정에만 작업 시간의 80%를 소요했다. 이와 같은 문제점을 해결하고자 나온것이 바로 Data Lake Framework이다. 데이터 엔지니어가 데이터 사용자들의 데이터 준비 시간을 단축시켜 주는 것이다. Ex) Apache Hadoop/Spark/Hive, Amazon S3
Append Only DB
- 데이터를 수정하지 않고 새로운 데이터만 추가하는 방식으로 동작한다. 이러한 DB는 주로 감사추적, 금융 서비스 등에서 활용된다.
- 데이터가 추가되면 변경되지 않으므로 데이터의 '무결성'이 보장되며, 데이터 수정 및 삭제로 인한 문제가 발생하지 않는다.
- 감사 추적을 위해 모든 데이터 변경 이력을 저장하므로 데이터의 변화를 추적하고 검증할 수 있다.
33. Handling Large-Scale Simultaneous Connections — Use Connection Pooling and consider using Protobuf to minimize data payload
대규모 동시 연결 처리 — 연결 풀링을 사용하고 Protobuf를 사용하여 데이터 페이로드를 최소화하는 것을 고려하세요.
Connection Pooling
- 풀에 미리 여러 개의 연결을 생성해두고, 클라이언트 요청이 들어올 때마다 풀에서 사용 가능한 연결을 할당하여 사용한다. 연결을 재사용하여 연결을 매번 생성하고 해제하는 오버헤드를 줄인다.
- 최대한의 연결을 생성하여 풀에 저장해둔다. 이를 통해 시스템이 동시에 처리할 수 있는 최대 연결 수를 제어하고, 과도한 연결 요청이 들어왔을 때도 안정적으로 처리할 수 있다.
- 풀은 일정 시간 동안 사용되지 않은 연결을 자동으로 해제하거나 재생성하여 연결의 유효성을 유지한다. 이를 통해 불필요한 연결 리소스의 낭비를 방지하고, 시스템의 성능을 최적화한다.
Protocol Buffer
- 데이터 페이로드(payload)는 통신에서 전송되는 실제 데이터의 부분을 가리킨다.
- Protocol Buffer는 구조화된 데이터를 직렬화하여 전송하는데 사용되는 바이너리 포맷이다. json, xml보다 더 작은 크기의 데이터를 생성하며, 빠르고 효율적인 데이터 전송이 가능하다.
- 대규모 동시 연결에서는 데이터 전송 속도와 크기가 중요하므로, 프로토콜 버퍼를 사용하여 데이터 페이로드를 최소화하고 네트워크 대역폭을 절약할 수 있다.
CQRS 패턴도 고려해보자.
