Multi-task Cascaded Convolutional Networks or MTCNN is a framework developed as a solution for both face detection and face alignment.
Stage 1. The Proposal Network (P-Net)
The first stage is a fully convolutional network (FCN). The difference between a CNN and a FCN is that a fully convolutional network does not use a dense layer as part of the architecture. This Proposal Network is used to obtain candidate windows and their bounding box regression vectors.
Stage 2. The Refine Network (R-Net)
All candidates from the P-Net are fed into the Refine Network. This network is a CNN, not a FCN like the one before since there is a dense layer at the last stage of the network architecture. The R-Net further reduces the number of candidates, performs calibration with bounding box regression and employs non-maximum suppression (NMS) to merge overlapping candidates.
The R-Net outputs whether the input is a face or not, a 4 element vector which is the bounding box for the face, and a 10 element vector for facial landmark localization.
Stage 3. The Output Network (O-Net)
This stage is similar to the R-Net, but this Output Network aims to describe the face in more detail and output the five facial landmarks' positions for eyes, nose, and mouth.
The Three Tasks of MTCNN
The Network's task is to output three things: face/non-face classification, bounding box regression, and facial landmark localization.
-
Face classification
This is a binary classification problem that uses cross-entropy loss.
-
Bounding box regression
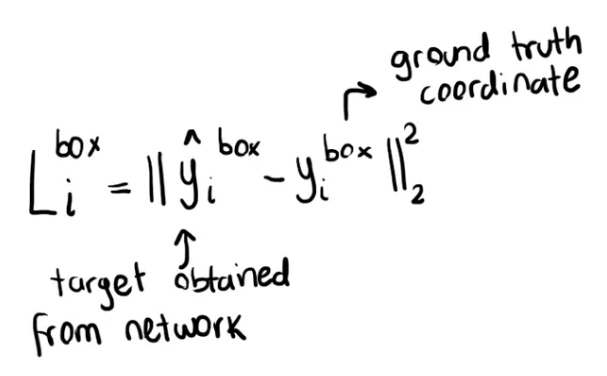
The learning objective is a regression problem. For each candidate window, the offset between the candidate and the nearest ground truth is calculated. Euclidean loss is employed for this task.
-
Facial Landmark localization
The localization of facial landmarks is formulated as a regression problem, in which the loss function is Euclidean distance.

