VGGNet과 ResNet의 차이점
- VGGNet
VGGNet는 2014년에 ILSVRC에서 GoogleNet과 함계 주목을 받았고 간소한 차이로 2위를 차지했습니다. 하지만 VGGNet은 간단한 구조와 단일 network에서 좋은 성능을 보여준다는 이유로, 오히려 1위를 차지한 GoogleNet보다 많은 network에서 응용되고 있습니다.
VGGNet은 network의 깊이(depth)가 어떤 영향을 주는지 연구를 하기 위해서 설계된 network 입니다.
그래서인지 convolutional kernel 사이즈를 한 사이즈로 정하고 Convolution의 개수를 늘리는 방식으로 테스트를 진행합니다. Convolution layer를 통해서 이미지 resize를 한 것이 아니라 max pooling을 사용해서 이미지를 resize를 합니다. Max pooling은 kernel 사이즈 2x2, stride 2로 이미지를 절반으로 resize 합니다. 아래 그림은 VGGNet이 layer의 깊이를 어떻게 늘려가며 테스트 했는지 보여줍니다. Network는 convolution layer를 추가함으로써 깊이가 깊어지는 것을 볼 수 있습니다.
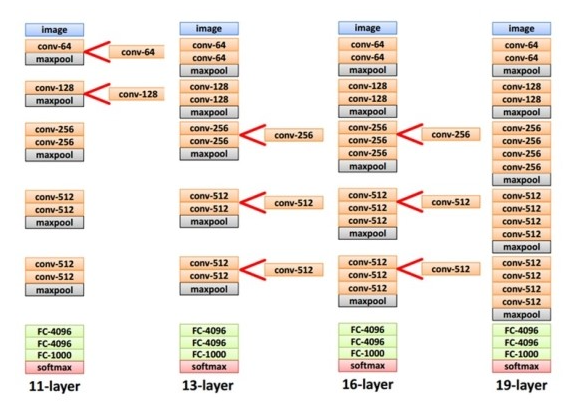
이론적으로 보면 5x5 kernel이나 3x3 kernel을 2개 사용하는 거나 성능적으로는 동일할 것이다. 그러나 VGGNet팀이 테스트한 결과 3x3 kernel을 중첩해서 사용하는게 성능은 더 좋다고 합니다. 이 이유는 non-linear 함수 ReLU가 더 많이 들어가서, decision function이 더 잘 학습되다고 볼수 있습니다. 또 한가지 이유는 학습을 해야 할 parameter 수가 줄어듭니다. 그러므로 큰 사이즈의 kernel보다는 작은 사이즈의 kernel을 중첩해서 사용하는게 성능도 더 좋고, 학습할 parameter도 적어서 속도도 더 빨라집니다. VGGNet의 구조는 간단하지만 최종단에 fully-connected layer 3개를 붙여서 parameter 수가 너무 많다는 단점이 있습니다. 최종단에 fully-connected layer에만 parameter 개수가 약 122 million개나 됩니다. network의 깊이가 깊어질수록 error가 내려가는 걸 볼 수 있습니다.
하지만 D(16-layer)와 E(19-layer)를 비교하면 error가 비스하거나 더 나빠지는 것을 보실 수 있습니다. 그렇다면 19-layer보다 network를 더 깊게 설계하면 어떻게 될까요? 결과가 더 나빠질 거라고 추측할 수 있습니다. - ResNet
VGGNet에서도 언급했지만 deep learning은 기본적으로 망이 깊어지면 성능이 더 좋아진다고 생각합니다. 이전까지 설계된 deep learning network는 8-layer 수준이었고, VGGNet에서 19-layer까지 테스트를 하였습니다. 하지만 VGGNet의 16 layer와 19 layer의 성능 차이는 거의 없었습니다. 만약 19-layer보다 망을 깊게 설계하면 어떻게 될까요?
[deep network의 문제점]
ResNet팀이 망이 깊어지는 경우 어떤 결과가 나오는지 실험을 하였습니다.
20-layer와 56-layer에 대해서 비교 테스트를 진행하였고, 결과는 아래 그림과 같습니다.
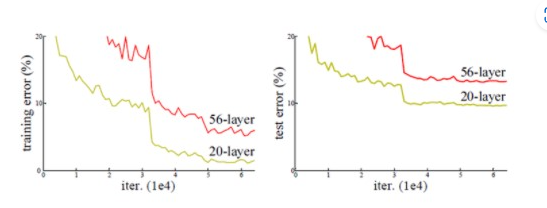
위 그림을 보시면, 오히려 56-layer의 결과가 더 나쁘게 나오는 걸 확인할 수 있습니다. 다른 이미지 데이터를 사용하거나 layer수를 변경을 해봐도 같은 결과가 나올 것입니다. 그 이유는 뭘까요?
망이 깊어지면 gradient vanishing/exploding 또는 degradation이 발생하게 됩니다. 하지만 ResNet은 망의 깊이를 처음에 152-Layer까지 늘렸고, 후에는 망의 깊이를 1001-layer까지 늘려서 설계 했습니다.
[ResNet의 구조]
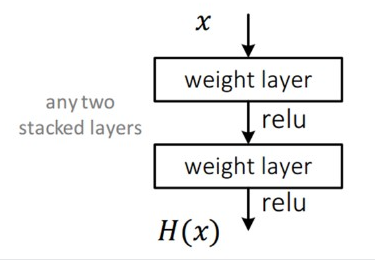
그럼 먼저 아래 구조와 같은 평범한 CNN 망을 살펴보겠습니다.
이 평범한 망은 입력 x를 받아 2개의 weighted layer를 거쳐 출력 H(x)를 내며, 다음 layer의 입력으로 적용됩니다.
ResNet은 layer의 입력을 layer의 출력으로 바로 연결시키는 "skip connection"을 사용했습니다. 아래 그림은 ResNet의 구조입니다.
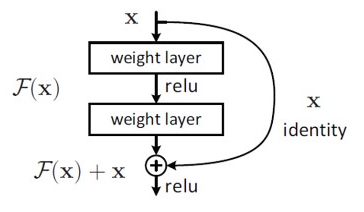
보시는 바와 같이 출력 H(x)가 F(x) + x로 변경이 되었습니다.
그림만으로 보면 단순히 weight layer를 통해 나온 결과와 그 전 결과를 더하고 relu를 사용한 것 뿐인데, 그 성능은 대단하였습니다. 그 이유는 기존 network들은 H(x)를 얻기 위해 학습을 했다면, ResNet은 F(x)가 0이 되는 방향으로 학습을 합니다.
F(x) = H(x) - x고, F(x)를 학습한다는 건 나머지(residual)을 학습한다고 볼 수 있고, 그렇기 때문에 ResNet이라 불리게 됩니다.
또한 x가 그대로 skip connection이 되기 때문에 연산 증가는 없고, F(x)가 몇 개의 layer를 포함하게 할지 선택이 가능하며 fully-connected layer외에 convolution layer도 가능합니다.
그리고 x와 H(x)의 dimension이 다르면 dimension을 맞추기 위해 parameter w들을 추가해서 학습 시킵니다.
Why ResNet worked?
그럼 왜 ResNet은 깊은 network에서도 학습이 되는지에 대해서 자세히 알아보도록 하겠습니다. 그 전에 먼저 gradient vanishing이 왜 발생하게 되는지에 대해서 설명하도록 하겠습니다.
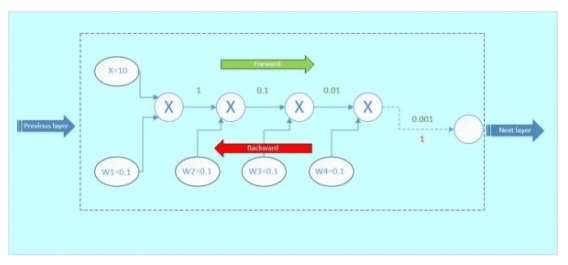
위 그림을 보시면 back propagation으로 weight를 갱신할 때, 앞쪽 layer로 갈수록 weight가 작아지는 것을 보실 수 있습니다.
그럼 network가 깊어질수록 weight가 계속 작아질 것이고 마지막에는 0으로 변해서 학습이 안되는 현상이 발생합니다.
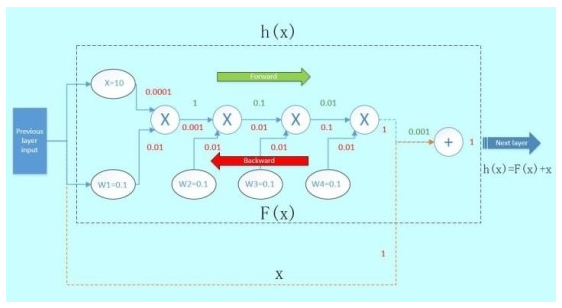
그럼 만약 ResNet과 같이 앞 layer를 skip connection으로 다음 layer에 연결하면 back propagation이 어떻게 변할까요? 그림의 주황색 선은 "Skip connection"입니다. 그림과 같이 Skip connection으로 gradient는 dh(x)/dx = 1이 됩니다. previous layer에 최종 전달되는 gradient는 [0.0001, 0.01]에서 [1, 0.0001, 0.01]이 됩니다.
1이라는 gradient가 더 추가가 되어서 Previous layer에 전달이 됩니다. 이런 이론을 적용하면 gradient vanishing을 줄일 수 있겠지만 어디까지나 한 개의 module에 관해서만 가능합니다.
실제로 ResNet은 많은 module을 사용하며, 이 방식이 아니더라도 BN (Batch Normalization), ReLU만으로도 어느 정도의 깊이의 network까지는 gradient vanishing이 발생하지 않습니다.
ResNet 이전의 network (VGGNet, AlexNet 등)들은 각 layer 입력은 그 전 layer의 출력에 의지하게 됩니다.
하지만 ResNet은 위 그림에 보시는 바와 같이 각 layer입력은 다른 구조의 network의 출력이 됩니다.
그러므로 ResNet 이전의 network들은 각 layer의 path 길이가 동일하지만, ResNet은 각 layer의 path 길이가 다릅니다.
