이미지를 인식하는 다양한 방법
이미지 내에서 사물 인식하는 방법에는 다양한 유형이 존재한다.
classification
- 일반적으로 한장의 이미지가 주어졌을 때 그 이미지가 어떤 클래스에 해당하는지 하나의 클래스로 분류하는 것을 말한다.

classification + Localization
- 정확히 해당 객체가 어디에 있는지 예측하는 것 까지 포함 한다면 classification + Localization 같이 한다고 부른다. 이미지 내에서 어떤 위치에 즉 어떤 지역에 위치하고 있는지 찾는 다라는 의미에서 Localization이라고 부른다.

object Detection
- 하나의 이미지 안에 여러개의 객체가 존재할 수 있는 상황에서 각각의 객체마다 그 위치를 설정해 주는 Localization을 수행해주고 각각의 bounding box마다 어떤 클래스에 해당하는지 분류 개념을 동시에 수행하는 것을 의미한다.

Instance Segmentation
- 한 이미지 안에 여러개의 object가 존재할 수 있는 상황에서 각각의 object 픽셀 단위로 예측하는 것을 확인할 수 있다. 각각의 픽셀마다 해당 픽셀이 어떤 클래스에 해당하는지 예측하는 방식으로 모델이 동작한다. segmentation은 각 픽셀마다 클래스를 할당하는 작업을 말한다.

semantic segmentation
정의 : 이미지 내에 있는 각 물체(object)들을 의미 있는(semantic)단위로 분할(segmentation)하는 작업을 의미한다.
- 일반적으로 분류(classifcation)에서는 단일 이마지를 하나의 클래스로 분류한다.
- 분할(segmentation)에서는 각 픽셀마다 하나의 클래스로 분류한다.

semantic segmentation 목표
- 각픽셀마다 N개의 클래스에 대한 확률(probability)을 뱉어야 하므로, 정답은(높이x너비xN)형태를 갖는다.
- 각 픽셀마다 원-핫 인코딩(one-hot encoding)형식을 따른다.
semantic segmentation 모델 학습
-
분할(semantation) 작업을 위한 데이터 세트 생성 비용은 매우 비싸다.
->각 픽셀마다 어떤 클래스로 분류되는지 일일이 지정해야 하기 때문이다. -
하지만 일반적인 CNN 분류 모델의 형식을 크게 바꾸지 않고 학습을 할 수 있다.
->일반적으로 딥러닝 네트워크의 구조가 크게 어렵지 않은 편이라는 장점이 있다.
->예를 들어 객체 탐지 분야의 네트워크 구조가 대개 더 복잡한 편이다.
CNN의 동작 과정
-
CNN에서는 필터(filter)혹은 커널(kernel)이라고 불리는 것을 사용한다.
-
각 필터는 입력에서 특정한 특징을 잡아내어 특징맵을 생성한다.
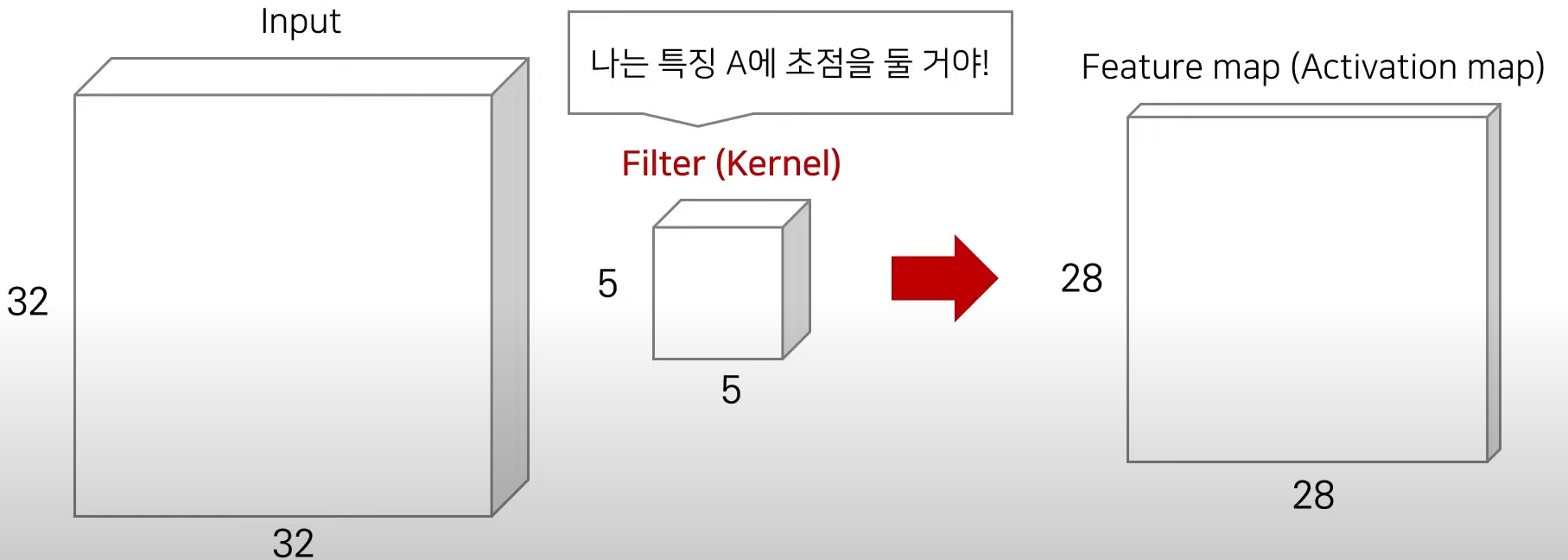
-
하나의 필터는 슬라이딩 하면서 컨볼루션 연산을 통해 특징 맵(feature map)을 계산한다.
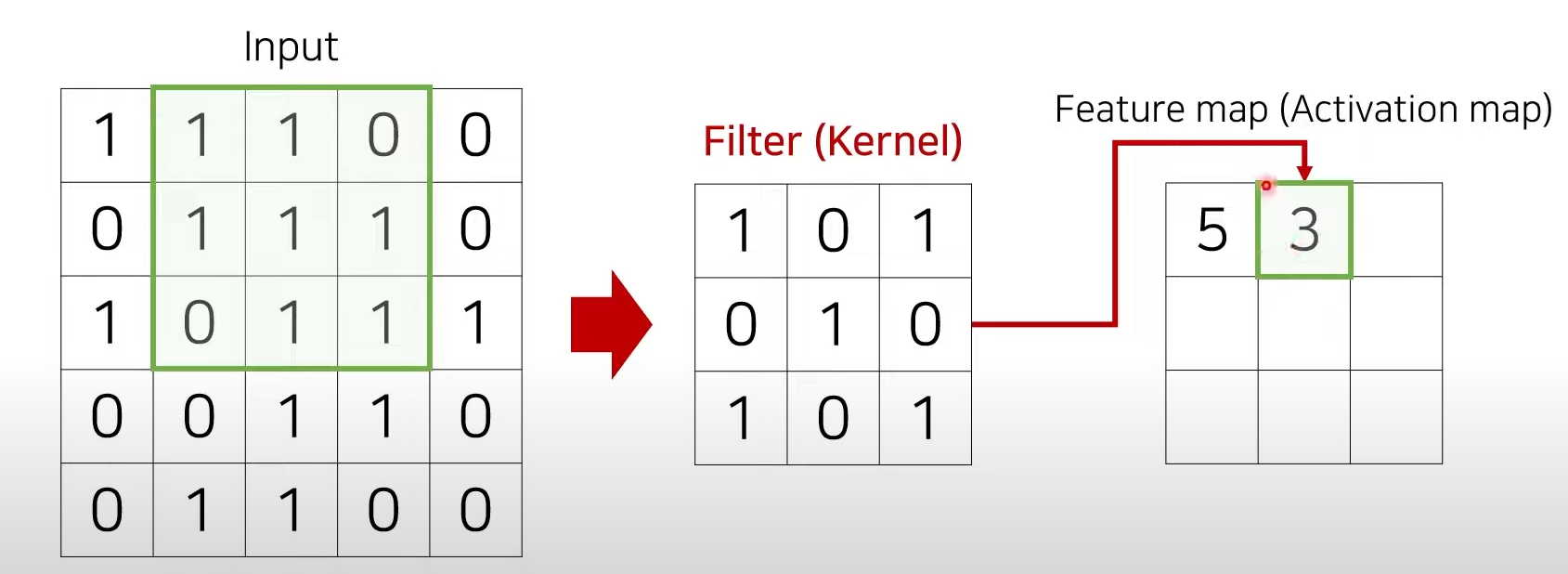
-
각 위치에서의 컨볼루션 연산 결과를 모아서 특징 맵(feature map)을 생성한다.
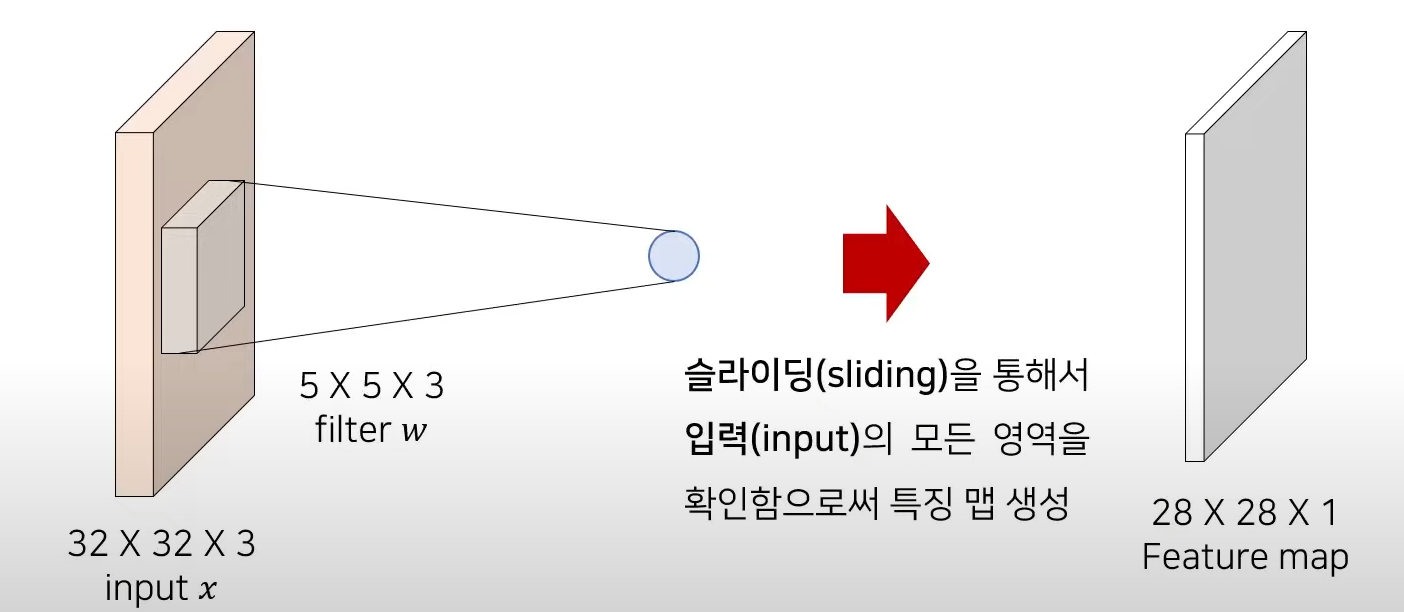
-
6개의 개별적인 필터(filter)를 가진 컨볼루션 레이어(convolution layer)를 이용하면 다음과 같다.
->출력 텐서의 채널 크기(channel size)는 필터의 개수와 동일하다.
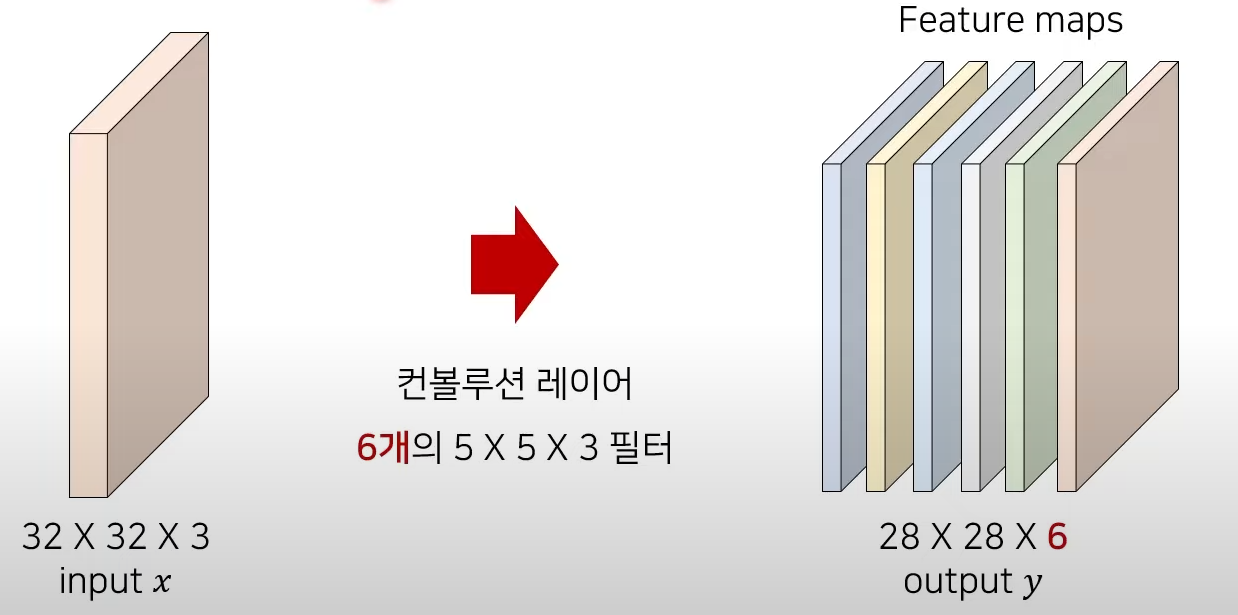
-
실제 CNN 레이어(layer)는 여러 번 중첩되어 사용될 수 있다.
-> 일반적으로 CNN분류 모델에서 깊은 레이어로 갈수록 채털의 수가 증가하고 너비와 높이는 감소함.
->컨볼루션 레이어의 서로 다른 필터들은 각각 적절한 특징 값을 추출하도록 학습된다.
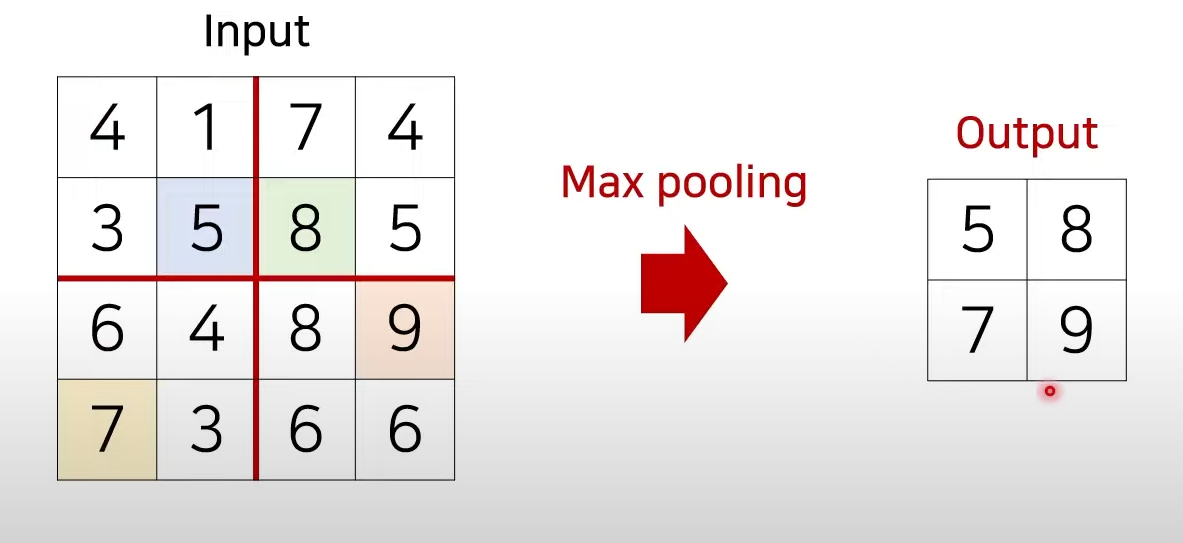
CNN의 MAX Pooling
- CNN 분류 모델에서 중요한 정보는 유지한 상태로 해상도(너비와 높이)를 감소시키는 방법 중 하나이며 가장 큰 값을 가지는 원소만 남긴다.
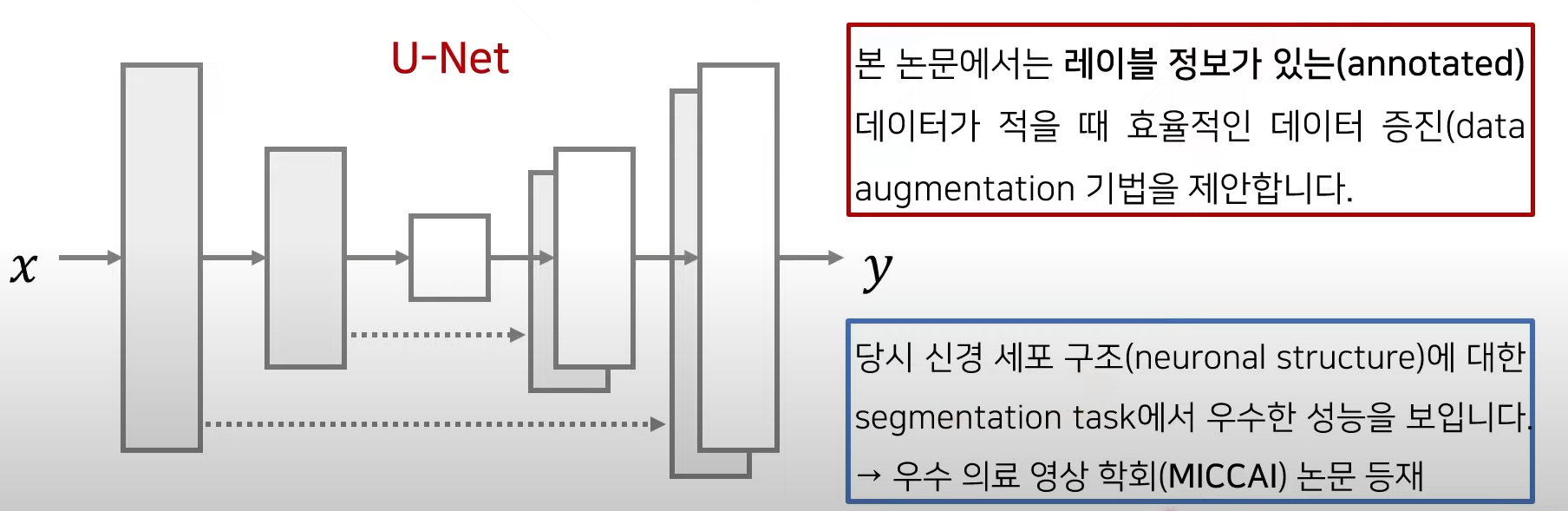
[논문소개] U-Net(MICCAI 2015)
- 본 논문에서는 u자형으로 생긴 네트워크인 U-Net 아키텍처를 제안함.
-> 수축 경로(contraction path): 이미지에 존재하는 넓은 문맥 정보를 처리한다.
-> 확장 경로(expanding path): 정밀한 지역화(precise localization)가 가능하도록 한다.
convolution 연산의 종류
Down-sampling 목적
Strided Convolution:너비와 높이가 감소
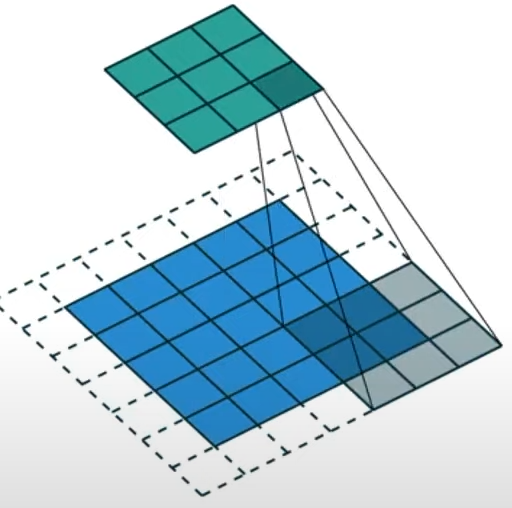
Up-sampling 목적
Transposed Convolution: 너비와 높이가 증가
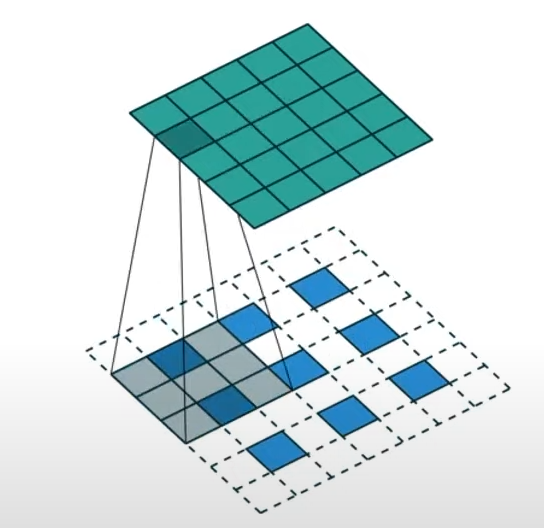
- U-Net 아키텍처의 초반 부분
- 2x2 Max poolig 사용
- 해상도(너비와 높이) 2배 감소
- Conv 연산으로 채널 크기는 2배 증가
- 일반적인 CNN 모델처럼 다음의 형식을 반복
- Conv 연산들 -> ReLU -> Max pooling
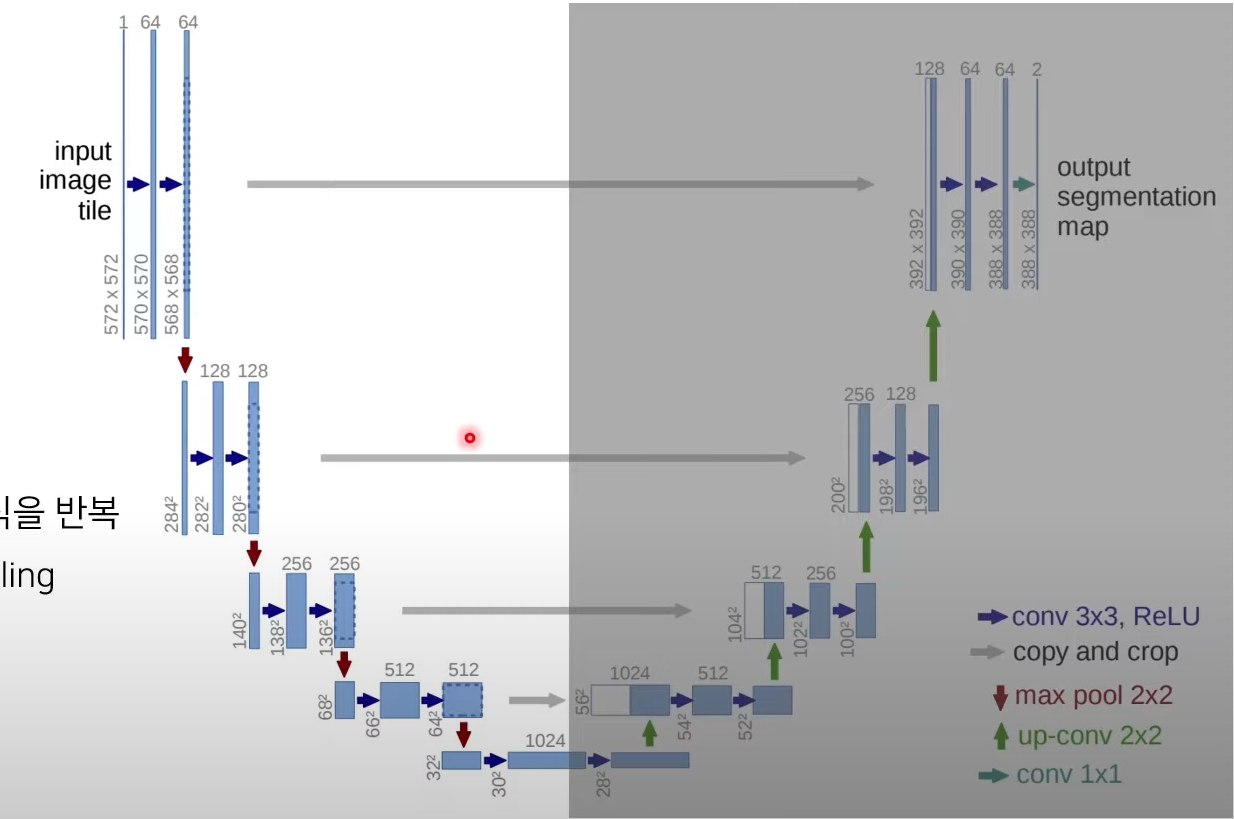
- U-Net 아키텍처의 후반부분
- 2x2Convolution(Up-convolution) 사용
- 해상도(너비와 높이)2배 증가
- Conv연산으로 채널 크기는 2배 감소
- 수축 경로(contraction path)에서 처리된 feature채널 레벨에서 연결(concatenation)map을 잘라내어(cropping)가져와 수행한다.

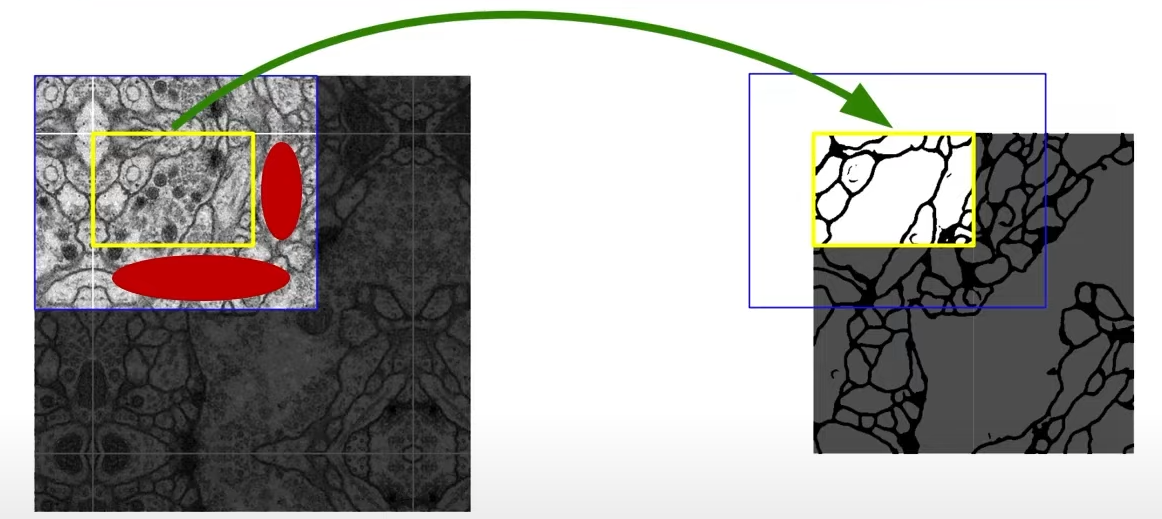
U-Net의 Overlap-tile 전략
- FCN 특성상 입력 이미지의 해상도에는 제한이 없다.
- 하지만 U-Net 구조상 출력 이미지의 해상도가 입력 이미지보다 작다.
- 실제로 노란색 영역의 segmentation이 필요하면 더 큰 범위 (파란색 영역)의 패치를 삽입한다.
- 이미지의 경계 부분은 extrapolation을 사용한다 -> 미러링(mirroring)활용
U-Net의 학습 방법: Objective Function
-
U-Net은 segmentation을 위한 네트워크이므로, 픽셀 단위로 소프트맥스를 사용한다.

-
학습을 위해 다음의 cross-entropy 손실을 사용

-
가중치 w(x)는 인접한 셀 사이에 있는 배경 레이블에 대하여 높은 가중치를 부여하며, 세포를 명확히 구분하기 위해 작은 분리 경계를 학습한다.
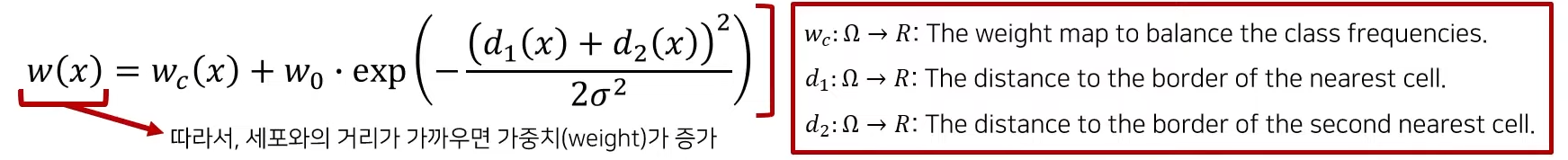
->거리값이 작으면 작을수록 가중치 값은 커지고 거리값이 커지면 가중치가 커지게 된다.
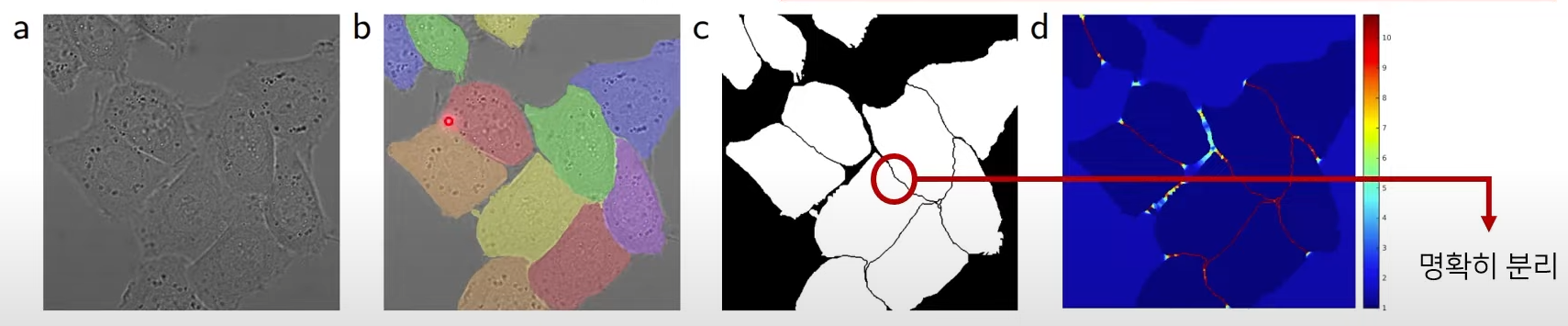
->세포와의 거리가 가까운 위치에서는 높은 가중치를 부여하도록해서 확실히 배경이라는 것을 알려줄 수 있게 도와준다. 즉 다시말해서 서로 붙어있는 여러개의 세포에 대해서 보다 명확하게 배경으로 부터 분리될 수 있게 해준다.
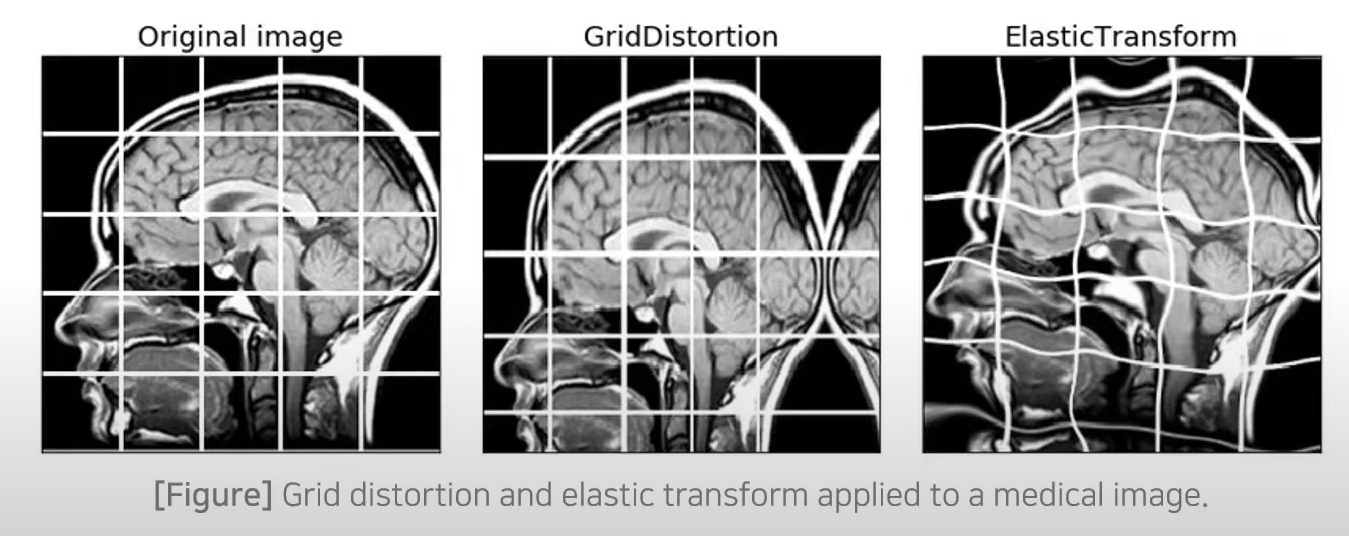
U-Net의 데이터 증진
- 의료 데이터에서는 학습 데이터의 수가 적은 경우가 많으므로, 데이터 증진이 필요하다
- 본 논문에서는 일반적인 data augmentation 기술을 사용한다.
- 추가적으로 Elastic Deformation 방법을 사용하며, 관련 사진은 다음과 같다.