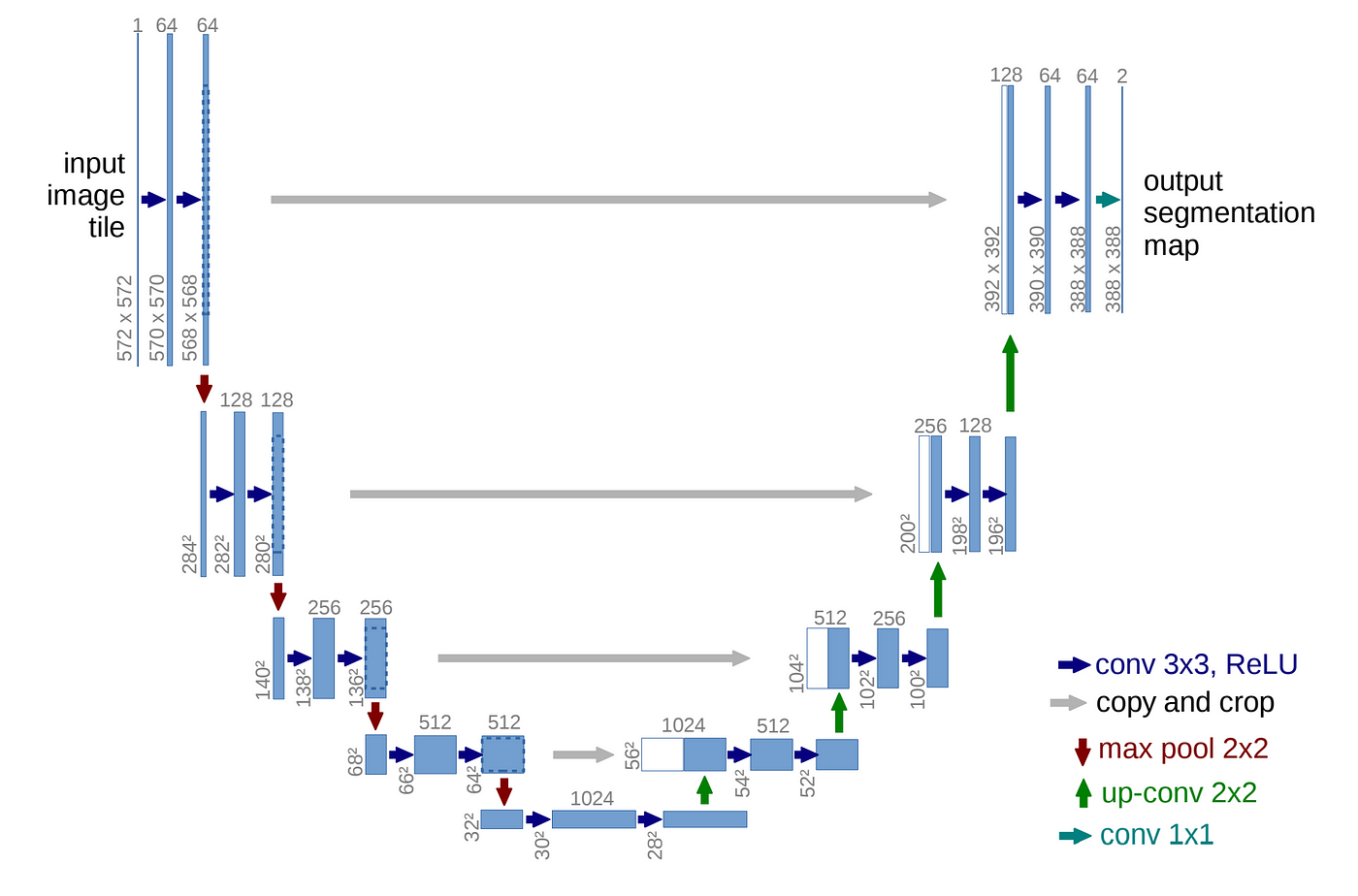
Pytorch_UNet 프로젝트를 참고하여 unet_parts.py 파일을 분석하였습니다.
이번 글에서는 unet_parts 파일의 구성과 역할을 집중적으로 살펴봅니다.
🔹 프로젝트 파일 구조
Pytorch-UNet-master/
├── .github/workflows/main.yml # GitHub Action 설정
├── data/ # 이미지, 마스크 데이터 폴더
├── scripts/ # 데이터 다운로드 스크립트
├── unet/ # U-Net 모델 관련 코드
│ ├── unet_model.py # U-Net 전체 모델 조립
│ └── unet_parts.py # U-Net 구성 파츠
├── utils/ # 데이터 로딩, 평가지표 함수
├── evaluate.py, predict.py, train.py # 모델 평가, 예측, 학습 코드
├── 기타 설정 파일들
📚 모델 분석 순서
- unet/unet_parts.py
- unet/unet_model.py
- train.py
- utils/data_loading.py
- utils/dice_score.py
- predict.py
🔥 코드 분석
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)입력 크기를 유지하며 특징(feature)을 추출하는 블록입니다.
3×3 Convolution → BatchNorm → ReLU 를 2번 반복합니다.
중간 채널(mid_channels)을 지정할 수 있는데, 보통 out_channels로 설정됩니다.
(필요하면 중간에 채널 수를 줄였다가 늘리는 것도 가능)
쉽게 말해, "특징을 잘 뽑아내는 이중 터널" 역할입니다.
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)U-Net의 특징인 디코더부분의 Downsampling의 코드입니다. 입력된 이미지를 점점 줄이면서 중요한 특징만 압축해서 뽑는 과정을 의미하며 크기를 절반으로 줄이고 특징을 두 번 COnvolution으로 추출한다. 즉 공간 정보는 줄이지만, 의미 있는 feature을 뽑아내기 위함입니다.
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)디코더(Decoder) 부분에서 작아진 이미지를 2배 키웁니다 (업샘플링).
키운 후, 저장해둔 원본(스킵 연결)을 이어붙입니다 (Concat).
이어붙인 feature map에 대해 다시 DoubleConv를 적용합니다.
⚙️ 업샘플링 방법 선택
bilinear=True
→ Bilinear interpolation (부드럽고 빠른 업샘플링) 사용
bilinear=False
→ ConvTranspose2d (학습 가능한 업샘플링) 사용
Bilinear는 빠르고 가볍지만 정밀한 복원은 약하고,
Transpose Conv는 정밀하지만 무겁고 느릴 수 있습니다.
⚡ 채널 수 줄이는 이유
크기만 키우면 (2배 확대) 픽셀 수는 4배 증가합니다.
그대로 채널도 많으면 메모리 폭발(GPU out-of-memory)!
그래서 in_channels // 2로 채널 수를 줄여서 메모리 사용량을 관리합니다.
🧩 Bilinear 보간법 예시
예를 들어, 다음처럼 새로운 픽셀 값을 부드럽게 채워넣습니다.
10 20 -> 10 15 20
30 40 20 25 30
30 35 40class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
모델이 학습한 결과를 진짜 정답 채널 수로 바꿔서 출력하는 단계로 마지막 단계에 해당합니다.