머신러닝은 데이터를 이용해서 명시적으로 정의되지 않은 패턴을 컴퓨터로 학습하여 결과를 만들어내는 학문 분야입니다. 머신러닝은 데이터, 패턴인식, 컴퓨터를 이용한 계산이 합쳐져서 만들어진 분야입니다.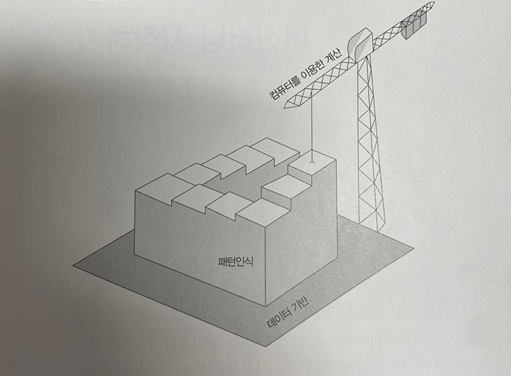
데이터
머신러닝은 항상 데이터를 기반으로 합니다. 이런 의미에서 머신러닝은 여러 규칙을 단순 조합하는 '고전적인 인공지능 시스템'과는 다르다고 할 수 있습니다. 또한 사용자가 어떻게 동작할지 완전히 정의하는 컴퓨터 알고리즘과도 다릅니다. 머신러닝은 알고리즘이 아닌 데이터 학습을 통해 실행 동작이 바뀌며 데이터를 기반으로 한다는 점에서 통계학과 가장 가깝다고 볼 수가 있습니다.
패턴인식
머신러닝은 통계학을 비롯해 딥러닝을 이용하여 데이터의 패턴을 유추하는 방법이 주축이 됩니다.
사용자가 일일이 정해놓은 패턴으로 데이터를 분석하는 것이 아니라 데이터를 보고 패턴을 추리는 것이 머신러닝의 핵심입니다.
컴퓨터를 이용한 계산
머신러닝은 데이터를 처리하고 패턴을 학습하고 계산하는 데 컴퓨터를 사용하고 그렇기 때문에 계산 그 자체도 머신러닝에서는 중요합니다. 분산 처리 등 시스템 구성에 관한 연구가 한 예이며, 이런 점에서 응용수학이나 통계학과 달리 머신러닝은 단순히 수학적인 모델의 구축이나 증명에만 그치는 것이 아니라 실제 데이터에 대해 계산해서 결과를 만들어낸다는 점에서 머신러닝은 전산학의 한 분야로 볼 수 있습니다.
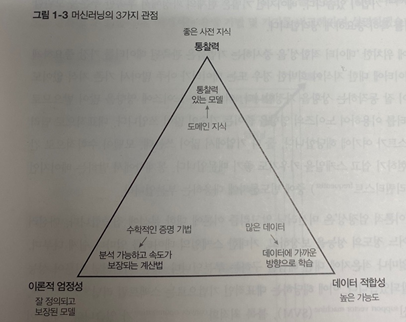
제이슨 아이스너는 머신러닝에 3가지 중요한 관점이 있다고 봅니다. 먼저 삼각형 맨 위쪽에 있는 '통찰력'을 중시하는 경우는 결국 데이터가 어떤 패턴을 가지고 있다고 믿으며, 그 패턴에 대한 지식을 확보하는 것을 중요시한다는 뜻입니다.
삼각형 오른쪽에 위치한 '데이터 적합성'을 중시하는 기법들은 곽측된 데이터를 가장 중요하게 생각합니다.
삼각형 왼쪽의 '이론적 엄정성'은 머신러닝 알고리즘 이론에 대한 분석에 집중합니다. 머신러닝 알고리즘이 어느 정도의 성능을 보장하고, 거대한 스케일의 데이터를 얼마나 쉽게 다루며, 잘못된 확률이 얼마나 적은지에 대한 해답을 구하는 부분입니다.
지도학습,비지도학습,강화학습
지도학습은 주어진 데이터와 레이블(정답)을 이용해서 미지의 상태나 값을 예측하는 학습 방법입니다. 대부분 머신러닝 문제는 지도학습에 해당합니다.
ex) 예전의 주식 시장변화를 보고 내일의 주식 시장 변화 예측하기, 문서에 사용된 단어를 보고 해당 문서의 카테고리 분류하기, 사용자가 구매한 상품을 토대로 다음에 구입할 상품 예측하기
비지도학습은 데이터와 그에 주어진 레이블 간의 연관 관계를 구하는 것이 아니라 데이터 자체에서 유용한 패턴을 찾아내는 학습 방법입니다. 지도학습과 가장 다른 점은 데이터가 주어졌을 때 특정 값을 계산하는 함수를 만드는 대신 데이터의 성질을 직접적으로 추측한다는 것입니다.
ex) 비슷한 데이터끼리 묶는 군집화,데이터에서 이상한 점을 찾아내는 이상 검출, 데이터 분포 추측
강화학습은 기계(에이전트)가 환경과의 상호작용(선택과 피드백의 반복)을 통해 장기적으로 얻는 이득을 최대화하도록 하는 학습 방법입니다. 지도학습과는 달리, 강화학습의 경우에는 입력값-출력값(레이블)의 쌍이 명시적으로 정해지지 않았습니다.
지도학습의 세부 분류
지도학습의 경우 데이터를 통해 학습하는 레이블이 어떤 성질을 지니는지에 따라 크게 회귀와 분류로 구분합니다.회귀의 경우에는 숫자값을 예측합니다. 대개 연속된 숫자를 예측하는데, 예를 들어 기존 온도 추이를 보고 내일 온도를 예측하는 일을 들 수 있습니다. 분류는 입력 데이터들을 주어진 항목들로 나누는 방법입니다. 회귀와 다르게 항목'1'과 항목'2'는 서로 다른 수치값이 아니라 서로 다른 항목임을 나타냅니다.
비지도학습의 세부 분류
군집화는 비지도학습의 분류 중 하나로 비슷한 데이터들을 묶어서 큰 단위로 만드는 기법입니다. 즉, 비슷한 데이터들을 묵어서 몇 개 의 그룹을 만들어 데이터 패턴을 파악합니다.
밀도 추정은 관측한 데이터로부터 데이터를 생성한 원래의 분포를 추측하는 방법입니다.
차원 축소는 말 그대로 '데이터의 차원을 낮추는' 기법으로, 디멘셔널리티 리덕션(dimensionality reduction)이라고도 합니다. 보통은 데이터가 복잡하고 높은 차원을 가져서 시각화하기 어려울 때 2차원이나 3차원으로 표현하기 위해 사용합니다.
딥러닝
딥러닝은 신경망을 층층이 쌓아서 문제를 해결하는 기법의 총칭입니다. 딥러닝은 머신러닝이 풀고자 하는 목표에 따라 분류한 개념이 아니며, 사용하는 기법이 특정 형태를 가지는 것을 말합니다. 이는 데이터양에 의존하는 기법으로, 다른 머신러닝 기법보다 문제에 대한 가정이 적은 대신 다양한 패턴과 경우에 유연하게 대응하는 구조를 만들어 많은 데이터를 이용하여 학습시키는 것으로 모델의 성능을 향상시킵니다. 즉, 큰 데이터에서 잘 동작하는 방법입니다.
