1월 18일 오늘의 일기
오늘 익스노드로 케글대회 참가 뭐시기를 하게되었는데,
하나도 이해가 안된다.
내가 보기엔 데이터들을 다 받아온 다음에 내가 필요한 데이터들을 꺼내는
그런 작업인거 같은데................ 일단 점수라도 받아야되는데 제출하는게 없다.
lms거기 설명이랑 내 화면이랑 달라서 어디서 받아야하는지 모르겠다.
일단 내가 알고 있는 부분은
import warnings
warnings.filterwarnings("ignore")
import os
from os.path import join
import pandas as pd
import numpy as np
import missingno as msno
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import KFold, cross_val_score
import xgboost as xgb
import lightgbm as lgb
import matplotlib.pyplot as plt
import seaborn as sns먼저 코드를 실행시키려면 실행시켜줄 라이브러리를 가져와야겠지..
그리고 데이터 파일을 알맞은 파일 경로를 사용해야 하니
data_dir = os.getenv('HOME')+'/aiffel/kaggle_kakr_housing/data'
train_data_path = join(data_dir, 'train.csv')
sub_data_path = join(data_dir, 'test.csv') # 테스트, 즉 submission 시 사용할 데이터 경로
print(train_data_path)
print(sub_data_path)여기에는 여러 정보들이 들어있다.

이 데이터들을 다 불러오면 몇개가 될까?>
data = pd.read_csv(train_data_path)
sub = pd.read_csv(sub_data_path)
print('train data dim : {}'.format(data.shape))
print('sub data dim : {}'.format(sub.shape))결과 : train data dim : (15035, 21) sub data dim : (6468, 20)
ㅎㄷㄷ... 학습데이터가 15000개, 테스트데이터가 6400개다.
근데 왜 학습데이터는 21개의 칼럼인데, 테스트는 20개일까? 그 이유는 가격칼럼이 빠져서다.
그래서 저 가격 칼럼을 지우고 싶으면
y = data['price']
del data['price']
print(data.columns)이렇게 코드를 작성하고 결과를 보면
Index(['id', 'date', 'bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot',
'floors', 'waterfront', 'view', 'condition', 'grade', 'sqft_above',
'sqft_basement', 'yr_built', 'yr_renovated', 'zipcode', 'lat', 'long',
'sqft_living15', 'sqft_lot15'],
dtype='object')
짜잔, price가 없다
근데 이 모델을 학습하기 전에 전체 데이터를 파악해 보고 싶다.
그럴려면 학습과 테스트 데이터를 합쳐야 겠지.
train_len = len(data)
data = pd.concat((data, sub), axis=0)
print(len(data))결과 : 21503 (아까 위에 데이터 합한게 나오네)
이걸 표로 보고 싶으면~
data.head()
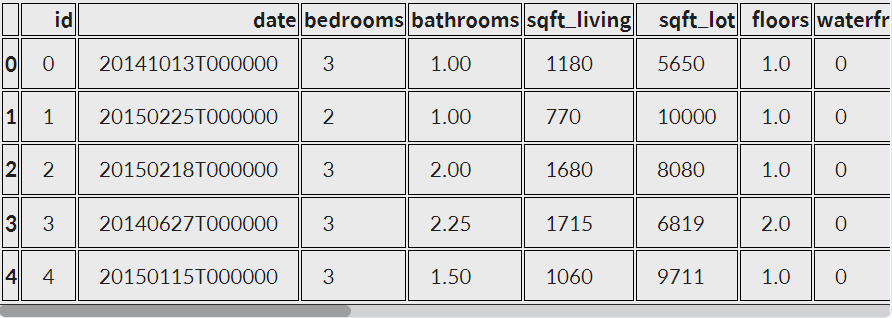
그 다음 데이터들 중에 빈데이터와 전체 데이터의 분포를 확인하는 전처리 과정도 필요하단말이지
그래서 아까 설치했던 missingno 라이브러리를 사용해보자.
msno.matrix(data) 
이런 결과가 나온다.
그 다음에 한번 id를 가지고 데이터프레임 인덱싱을 적용해보자.
3단계로 진행이 되는데
1. 먼저 id칼럼이 결측치인지 확인하고
2. 그 다음 결측치의 데이터만 뽑아낸다.
3. 마지막으로 결측치 데이터 개수를 센다.
그래서 가장 먼저 id 칼럼이 결측치인지 확인해보면.
null_check = pd.isnull(data['id'])
print(null_check)
그 다음에 결측치 데이터를 뽑아내보자.
null_data = data.loc[null_check, 'id']
null_data.head()Series([], Name: id, dtype: int64)
결측치가 없어서 비었네?
마지막으로 결측치 데이터 개수를 세보면?
print('{}: {}'.format('id', len(null_data.values))) id: 0
없어서 0이 뜨네..
근데 이거 따로 따로 하면 귀찮으니깐 한번에 몰아서 해보자.
print('{} : {}'.format('id', len(data.loc[pd.isnull(data['id']), 'id'].values)))id: 0
근데 이게 id뿐만 아니라 위에서 본것처럼 다른거에도 써야되니깐 for문을 쓰자.
for c in data.columns:
print('{} : {}'.format(c, len(data.loc[pd.isnull(data[c]), c].values)))근데 id중에 굳이 필요없는건 있을 필요가 없으니 지워버리자, 근데 나중에 예측결과를 제출할 때 대비해서 sub_id변수에 id를 집어넣자.
sub_id = data['id'][train_len:]
del data['id']
print(data.columns)여기서 date 칼럼은 apply 함수로 필요부분만 컷팅!
data['date'] = data['date'].apply(lambda x : str(x[:6]))
data.head() 근데 str(x[:6]) 이걸 왜 썼냐..
결과를 도출하면 아까 저 위에 표 보면 20141013T0000막 이런식으로 길게 되어있는데
너무 보기 불편하니깐 년/월까지만 표시되게끔 넣은거다.
그래서 출력해서 보면 201410까지만 깔끔하게 나온다.
일단 깔끔하게 해 놓고, 불필요한거 치워놓고 그 다음에 전체 데이터의 분포를 확인해야겠지
그래서 그래프를 사용할건데 이산데이터의 경우에도 부드러운 곡선으로 전체 분포를 확인할 수 있도록 하는 시각함수 sns.kdeplot를 사용해야겠다.
fig, ax = plt.subplots(9, 2, figsize=(12, 50)) # 가로스크롤 때문에 그래프 확인이 불편하다면 figsize의 x값을 조절해 보세요.
id 변수(count==0인 경우)는 제외하고 분포를 확인합니다.
count = 1
columns = data.columns
for row in range(9):
for col in range(2):
sns.kdeplot(data=data[columns[count]], ax=ax[row][col])
ax[row][col].set_title(columns[count], fontsize=15)
count += 1
if count == 19 :
break이 명령어를 놓고 결과를 보면.
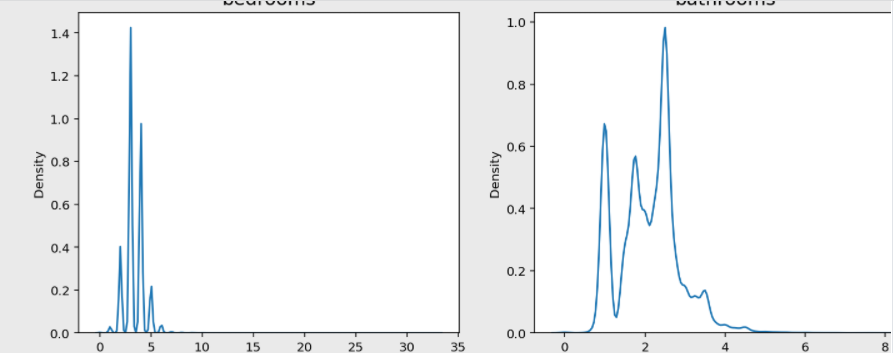
이런식의 그래프가 19개 정도 나온다.
근데 그래프들을 쫙 훑어보니 bedrooms, sqft_living, sqft_lot, sqft_above, sqft_basement, sqft_living15, sqft_lot15 변수가 한쪽으로 치우친 경향을 보인다.
이렇게 한 쪽으로 치우친 분포의 경우에는 로그 변환(log-scaling)을 통해 데이터 분포를 정규분포에 가깝게 만들 수 있다.
아래와 같이 치우친 컬럼들을 skew_columns 리스트 안에 담고, 모두 np.log1p()를 활용해서 로그 변환을 해보자. numpy.log1p() 함수는 입력 배열의 각 요소에 대해 자연로그 log(1 + x)을 반환해 주는 함수다.
skew_columns = ['bedrooms', 'sqft_living', 'sqft_lot', 'sqft_above', 'sqft_basement', 'sqft_lot15', 'sqft_living15']
for c in skew_columns:
data[c] = np.log1p(data[c].values)
print('얍💢')이렇게 변환시켜보고 다시 그래프를 출력해보면?
fig, ax = plt.subplots(4, 2, figsize=(12, 24))
count = 0
for row in range(4):
for col in range(2):
if count == 7:
break
sns.kdeplot(data=data[skew_columns[count]], ax=ax[row][col])
ax[row][col].set_title(skew_columns[count], fontsize=15)
count += 1
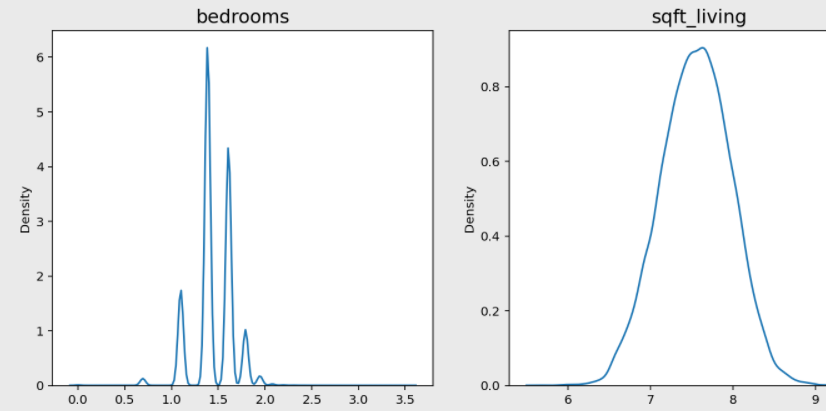
치우친게 가운데로 몰렸다.
근데 어떻게 로그변환이 분포 치우침을 줄어들게 할까?
그걸 보려면 일단 그래프를 그려야겠지
xx = np.linspace(0, 10, 500)
yy = np.log(xx)
plt.hlines(0, 0, 10)
plt.vlines(0, -5, 5)
plt.plot(xx, yy, c='r')
plt.show() 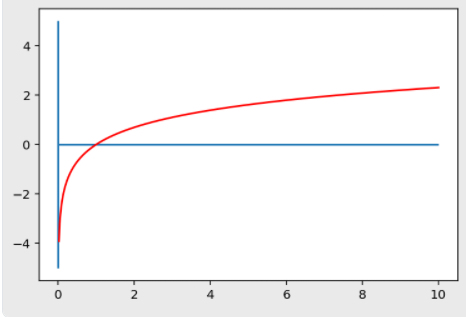
그럼 이런 그래프가 나오는데, 여기서 보이는 로그함수 특징이 있다.
0<x<1 범위에서는 기울기가 매우 가파르다. 즉, xx의 구간은 (0, 1)(0,1)로 매우 짧은 반면, yy의 구간은 (-\infty, 0)(−∞,0)으로 매우 크다.
따라서 0에 가깝게 모여있는 값들이 xx로 입력되면, 그 함수값인 yy 값들은 매우 큰 범위로 벌어지게 된다.
로그 함수는 0에 가까운 값들이 조밀하게 모여있는 입력값을, 넓은 범위로 펼칠 수 있는 특징을 가진다.
반면, xx값이 점점 커짐에 따라 로그 함수의 기울기는 급격히 작아진다.
이는 곧 큰 xx값들에 대해서는 yy값이 크게 차이나지 않게 된다는 뜻이고, 따라서 넓은 범위를 가지는 xx를 비교적 작은 yy값의 구간 내에 모이게 하는 특징을 가진다.
일단 오늘은 여기까지만 하고 다음에 이어서 써야겠당
