EXPLORATION_YJ2 분류를 해보자.
1. 문자를 분류해보자
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report먼저 문자 분류 프로그램을 만들기 전에 문자를 가져오는 명령문이다.
from sklearn.datasets import load_digits
digits = load_digits()
print(dir(digits))결과 : ['DESCR', 'data', 'feature_names', 'frame', 'images', 'target', 'target_names']
그 다음 불러온 문자들중 dir을 사용해서 객체에 어떤 변수와 매서드가 있는지 나열해본다.
digits_data = digits.data
print(digits_data.shape)결과 : (1797, 64) 이것은 1797개의 데이터 행과 64개의 변수가 있다는 뜻이다.
digits_data[0]결과 : array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13., 15., 10.,
15., 5., 0., 0., 3., 15., 2., 0., 11., 8., 0., 0., 4.,
12., 0., 0., 8., 8., 0., 0., 5., 8., 0., 0., 9., 8.,
0., 0., 4., 11., 0., 1., 12., 7., 0., 0., 2., 14., 5.,
10., 12., 0., 0., 0., 0., 6., 13., 10., 0., 0., 0.])
이것은 0번째 데이터의 숫자가 무엇인가를 확인하는 것이다.
digits_label = digits.target--]
print(digits_label.shape)-----] 라벨을 저장
digits_label==> 라벨에 들어가있는 모양 확인결과 : (1797,)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
import pandas as pd
print(pd.__version__)결과 : 1.3.3 이건 그냥 판다스 버전 확인
digits_df = pd.DataFrame(data=digits_data, columns=digits.feature_names)
digits_df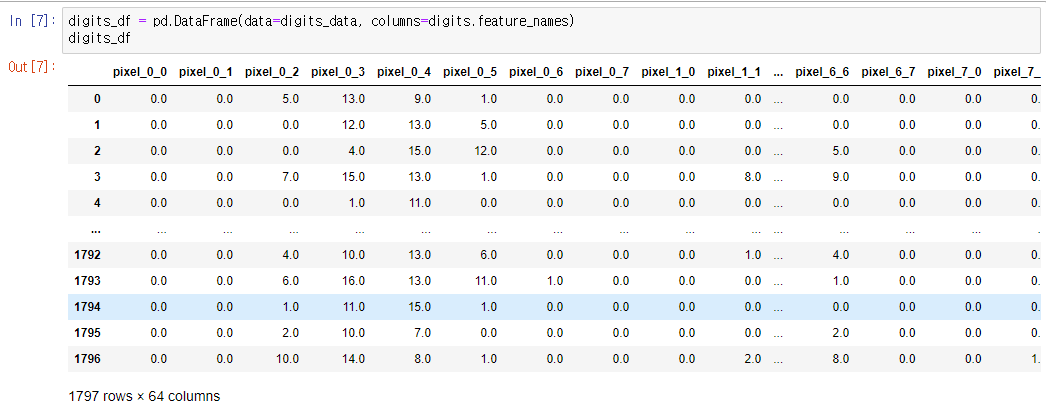
이것은 아까 위에서 보았던 행렬과 변수를 볼 수 있는 표를 보여준다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(digits_data,
digits_label,
test_size=0.2,
random_state=7)
print('X_train 개수: ', len(X_train),', X_test 개수: ', len(X_test))
X_train.shape, y_train.shape 결과 : X_train 개수: 1437 , X_test 개수: 360
((1437, 64), (1437,))
훈련(train)과 실험(test)를 분리한 다음 모델에 적용하기 위해 스플릿 작업을 해줘야 한다.
위에는 훈련과 테스트 갯수, 그리고 훈련의 모양만 보여줬는데 이번엔 테스트의
모양을 한번 보자.
X_test.shape, y_test.shape결과 : ((360, 64), (360,))
그런데 y의 는 어떻게 생겼을까? 하고 쳐봤다
y_train, y_test결과로는 (array([2, 2, 2, ..., 1, 3, 3])
array([6, 0, 5, 9, 2, 9, 0, 4, 1, 0, 1, 8, 2, 5, 2, 8, 1, 8, 9, 1, 0, 2,
0, 4, 5, 3, 3, 0, 0, 4, 1, 4, 4, 4, 6, 1, 4, 0, 6, 6, 0, 9, 3, 6,
6, 2, 0, 1, 9, 6, 2, 8, 9, 9, 0, 2, 0, 8, 4, 6, 8, 5, 8, 7, 8, 7,
7, 4, 1, 4, 5, 5, 4, 6, 2, 0, 1, 3, 7, 5, 8, 2, 4, 4, 2, 5, 1, 9,
3, 7, 6, 3, 3, 5, 6, 2, 1, 0, 1, 9, 4, 1, 1, 3, 1, 6, 9, 0, 3, 7,
6, 9, 3, 8, 0, 8, 3, 8, 8, 6, 3, 7, 3, 9, 0, 3, 0, 9, 8, 1, 2, 2,
3, 6, 9, 4, 0, 5, 4, 2, 9, 1, 0, 2, 5, 0, 2, 2, 7, 4, 6, 9, 8, 2,
6, 0, 4, 4, 8, 5, 0, 2, 4, 6, 8, 2, 3, 7, 2, 9, 0, 3, 5, 9, 1, 6,
8, 7, 5, 3, 0, 4, 2, 1, 3, 3, 6, 0, 2, 8, 4, 1, 4, 7, 5, 7, 6, 6,
8, 1, 0, 6, 8, 7, 1, 1, 9, 8, 5, 5, 3, 6, 8, 1, 2, 0, 7, 5, 3, 0,
8, 2, 0, 4, 0, 9, 4, 8, 4, 7, 9, 7, 3, 6, 2, 5, 1, 5, 9, 2, 9, 9,
8, 2, 1, 6, 7, 1, 7, 5, 7, 8, 9, 5, 7, 4, 3, 7, 8, 8, 2, 8, 9, 5,
3, 2, 8, 0, 4, 2, 1, 0, 8, 4, 1, 7, 1, 4, 7, 7, 1, 8, 3, 8, 4, 3,
5, 9, 4, 4, 8, 1, 8, 7, 2, 3, 1, 1, 1, 0, 2, 8, 0, 7, 4, 0, 1, 0,
2, 3, 7, 9, 8, 5, 8, 2, 2, 6, 5, 0, 8, 9, 8, 9, 0, 0, 9, 7, 4, 1,
2, 6, 7, 3, 7, 4, 0, 2, 1, 7, 2, 5, 7, 2, 3, 5, 7, 1, 4, 1, 3, 3,
8, 8, 1, 0, 1, 9, 3, 0]))
이런식의 결과가 나왔다.
이렇게 train과 test를 설정 했으면 이제 의사결정을 하는 프로그램을 가져와야 한다.
from sklearn.tree import DecisionTreeClassifier먼저 sklearn.tree에 있는 DecisionTreeClassifier을 가져온다.
그 다음 모델을 적용해준다.
decision_tree = DecisionTreeClassifier(random_state=32)
print(decision_tree._estimator_type)그 다음 훈련(train)에 적용해 본다
decision_tree.fit(X_train, y_train)결과 : DecisionTreeClassifier(random_state=32)
먼저 어떤 결과가 나올 지 예측을 해볼 수 있다.
y_pred = decision_tree.predict(X_test)
y_pred결과 : array([6, 0, 5, 3, 2, 9, 0, 4, 1, 0, 1, 8, 2, 5, 2, 8, 1, 8, 3, 1, 0, 2,
0, 4, 5, 3, 3, 0, 0, 4, 1, 4, 4, 4, 6, 1, 4, 0, 6, 6, 0, 5, 3, 6,
6, 2, 0, 1, 9, 6, 2, 8, 2, 9, 0, 2, 0, 8, 4, 6, 8, 5, 8, 7, 2, 7,
7, 2, 2, 4, 5, 5, 4, 6, 2, 0, 3, 3, 7, 5, 8, 2, 4, 4, 2, 5, 1, 4,
3, 7, 6, 3, 1, 5, 6, 2, 1, 0, 1, 1, 4, 5, 1, 3, 1, 6, 9, 0, 3, 7,
6, 9, 3, 8, 0, 1, 3, 8, 8, 6, 3, 7, 3, 9, 0, 9, 0, 9, 3, 1, 2, 2,
3, 6, 9, 4, 0, 1, 8, 3, 9, 1, 0, 8, 5, 0, 7, 2, 7, 4, 4, 9, 2, 2,
6, 0, 4, 4, 9, 5, 0, 2, 4, 4, 2, 2, 3, 7, 2, 9, 0, 3, 5, 9, 9, 6,
8, 4, 5, 3, 0, 4, 2, 1, 3, 3, 6, 0, 8, 1, 4, 1, 4, 7, 5, 7, 6, 6,
8, 1, 0, 6, 1, 7, 1, 1, 9, 8, 5, 5, 3, 6, 6, 1, 2, 0, 7, 5, 3, 0,
8, 2, 0, 4, 0, 9, 4, 6, 4, 7, 9, 5, 3, 6, 2, 5, 2, 5, 9, 3, 9, 9,
2, 2, 1, 6, 4, 1, 7, 5, 9, 8, 9, 5, 7, 4, 3, 7, 4, 8, 2, 8, 9, 5,
3, 2, 1, 0, 4, 2, 1, 0, 1, 4, 1, 7, 6, 4, 7, 7, 9, 8, 3, 8, 4, 3,
5, 9, 4, 4, 8, 1, 8, 7, 2, 3, 2, 1, 1, 0, 2, 8, 0, 7, 4, 3, 1, 0,
2, 3, 9, 9, 8, 5, 6, 2, 2, 6, 5, 0, 8, 9, 8, 9, 0, 0, 4, 7, 4, 1,
9, 6, 7, 3, 7, 4, 0, 2, 1, 7, 6, 5, 3, 2, 3, 5, 7, 1, 4, 1, 3, 3,
8, 8, 1, 0, 1, 9, 8, 0])
그 다음 테스트를 진행해보면
y_test 결과 : array([6, 0, 5, 9, 2, 9, 0, 4, 1, 0, 1, 8, 2, 5, 2, 8, 1, 8, 9, 1, 0, 2,
0, 4, 5, 3, 3, 0, 0, 4, 1, 4, 4, 4, 6, 1, 4, 0, 6, 6, 0, 9, 3, 6,
6, 2, 0, 1, 9, 6, 2, 8, 9, 9, 0, 2, 0, 8, 4, 6, 8, 5, 8, 7, 8, 7,
7, 4, 1, 4, 5, 5, 4, 6, 2, 0, 1, 3, 7, 5, 8, 2, 4, 4, 2, 5, 1, 9,
3, 7, 6, 3, 3, 5, 6, 2, 1, 0, 1, 9, 4, 1, 1, 3, 1, 6, 9, 0, 3, 7,
6, 9, 3, 8, 0, 8, 3, 8, 8, 6, 3, 7, 3, 9, 0, 3, 0, 9, 8, 1, 2, 2,
3, 6, 9, 4, 0, 5, 4, 2, 9, 1, 0, 2, 5, 0, 2, 2, 7, 4, 6, 9, 8, 2,
6, 0, 4, 4, 8, 5, 0, 2, 4, 6, 8, 2, 3, 7, 2, 9, 0, 3, 5, 9, 1, 6,
8, 7, 5, 3, 0, 4, 2, 1, 3, 3, 6, 0, 2, 8, 4, 1, 4, 7, 5, 7, 6, 6,
8, 1, 0, 6, 8, 7, 1, 1, 9, 8, 5, 5, 3, 6, 8, 1, 2, 0, 7, 5, 3, 0,
8, 2, 0, 4, 0, 9, 4, 8, 4, 7, 9, 7, 3, 6, 2, 5, 1, 5, 9, 2, 9, 9,
8, 2, 1, 6, 7, 1, 7, 5, 7, 8, 9, 5, 7, 4, 3, 7, 8, 8, 2, 8, 9, 5,
3, 2, 8, 0, 4, 2, 1, 0, 8, 4, 1, 7, 1, 4, 7, 7, 1, 8, 3, 8, 4, 3,
5, 9, 4, 4, 8, 1, 8, 7, 2, 3, 1, 1, 1, 0, 2, 8, 0, 7, 4, 0, 1, 0,
2, 3, 7, 9, 8, 5, 8, 2, 2, 6, 5, 0, 8, 9, 8, 9, 0, 0, 9, 7, 4, 1,
2, 6, 7, 3, 7, 4, 0, 2, 1, 7, 2, 5, 7, 2, 3, 5, 7, 1, 4, 1, 3, 3,
8, 8, 1, 0, 1, 9, 3, 0])
얼추 보기에는 비슷하게 나왔다.
그렇지만 저런 표로 보면 불편하니까 간단하게 만들어서 보자.
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
accuracy 결과 : 0.8555555555555555
테스트 값과 예측값의 일치도가 86%정도 나왔다.
위에서 한번 테스트도 해보고 예측도 해봤으니 훈련(train)을 시켜보면
먼저 필요한 모듈들을 import 해준다.
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report그 다음 데이터를 준비해주고
digits = load_digits()
digits_data = digits.data
digits_label = digits.target아까 위에서 처럼 훈련과 테스트를 분리해준다.
X_train, X_test, y_train, y_test = train_test_split(digits_data,
digits_label,
test_size=0.2,
random_state=7)이제 마지막으로 훈련을 시키기 위한 명령어를 넣어주면
decision_tree = DecisionTreeClassifier(random_state=32)
decision_tree.fit(X_train, y_train)
y_pred = decision_tree.predict(X_test)
print(classification_report(y_test, y_pred))결과 : precision recall f1-score support
0 1.00 0.98 0.99 43
1 0.81 0.81 0.81 42
2 0.79 0.82 0.80 40
3 0.79 0.91 0.85 34
4 0.83 0.95 0.89 37
5 0.90 0.96 0.93 28
6 0.84 0.93 0.88 28
7 0.96 0.82 0.89 33
8 0.88 0.65 0.75 43
9 0.78 0.78 0.78 32
accuracy 0.86 360
macro avg 0.86 0.86 0.86 360
weighted avg 0.86 0.86 0.85 360이런 식의 결과가 나온다. accuracy를 보면 아까 테스트 한것과 비슷한 결과가 나온것을 볼 수 있다.
근데 위의 훈련을 정해진것만 하지 말고 랜덤으로 돌려보면 어떻게 될까?
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(random_state=32)
random_forest.fit(X_train, y_train)
y_pred = random_forest.predict(X_test)
print(classification_report(y_test, y_pred))위와는 다르게 random을 부여했다
결과 :
precision recall f1-score support
0 1.00 0.98 0.99 43
1 0.93 1.00 0.97 42
2 1.00 1.00 1.00 40
3 1.00 1.00 1.00 34
4 0.93 1.00 0.96 37
5 0.90 0.96 0.93 28
6 1.00 0.96 0.98 28
7 0.94 0.97 0.96 33
8 1.00 0.84 0.91 43
9 0.94 0.94 0.94 32
accuracy 0.96 360
macro avg 0.96 0.96 0.96 360
weighted avg 0.97 0.96 0.96 360엥? 아까보다 accuracy가 더 높다
왜일까?
이제는 여기에 3가지 분류모델을 적용해 볼 것이다.
가장 먼저 내장(svm)분류라는 것을 해볼 것이다.
내장(svm)분류는 데이터 분석 중 분류에 이용되며 지도학습 방식의 모델이다.
from sklearn import svm #내장분류 모델
svm_model = svm.SVC()
print(svm_model._estimator_type)
svm_model.fit(X_train, y_train)
y_pred = svm_model.predict(X_test)
print(classification_report(y_test, y_pred))결과 : classifier
precision recall f1-score support
0 1.00 1.00 1.00 43
1 0.95 1.00 0.98 42
2 1.00 1.00 1.00 40
3 1.00 1.00 1.00 34
4 1.00 1.00 1.00 37
5 0.93 1.00 0.97 28
6 1.00 1.00 1.00 28
7 1.00 1.00 1.00 33
8 1.00 0.93 0.96 43
9 1.00 0.97 0.98 32
accuracy 0.99 360
macro avg 0.99 0.99 0.99 360
weighted avg 0.99 0.99 0.99 360아까 위에 것들보다 훨씬 accuracy가 높은것을 확인 할 수 있다.
그 다음으로 해볼 분류방식은 SGDClassifier모델이다.
이 모델의 특징은 확률적 경사 하강법으로 가장 큰 데이터셋을 가지고 있을 때 훈련 데이터를
하나씩 독립적으로 처리하기 때문에 유용하게 사용된다고 한다.
from sklearn.linear_model import SGDClassifier #SGD Classifier 모델
sgd_model = SGDClassifier()
print(sgd_model._estimator_type)
sgd_model.fit(X_train, y_train)
y_pred = sgd_model.predict(X_test)
print(classification_report(y_test, y_pred))결과 : classifier
precision recall f1-score support
0 1.00 1.00 1.00 43
1 0.90 0.88 0.89 42
2 1.00 1.00 1.00 40
3 0.94 0.88 0.91 34
4 1.00 1.00 1.00 37
5 0.93 0.96 0.95 28
6 1.00 0.93 0.96 28
7 0.97 0.97 0.97 33
8 0.87 0.93 0.90 43
9 0.94 0.97 0.95 32
accuracy 0.95 360
macro avg 0.95 0.95 0.95 360
weighted avg 0.95 0.95 0.95 360정확도는 좋은 편이지만 svm 방식에 비해서는 조금 떨어지는 것 같다.
마지막으로 해볼 분류식은 Logistic Regression모델인데 이것은 독립 변수의 선형
결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계기법이라고 한다.
from sklearn.linear_model import LogisticRegression #Logistic Regression 모델
logistic_model = LogisticRegression(max_iter=2500)
print(logistic_model._estimator_type)
logistic_model.fit(X_train, y_train)
y_pred = logistic_model.predict(X_test)
print(classification_report(y_test, y_pred))결과 : classifier
precision recall f1-score support
0 1.00 1.00 1.00 43
1 0.95 0.95 0.95 42
2 0.98 1.00 0.99 40
3 0.94 0.97 0.96 34
4 1.00 1.00 1.00 37
5 0.79 0.96 0.87 28
6 1.00 0.96 0.98 28
7 0.94 0.97 0.96 33
8 0.92 0.81 0.86 43
9 0.97 0.88 0.92 32
accuracy 0.95 360
macro avg 0.95 0.95 0.95 360
weighted avg 0.95 0.95 0.95 360 흠... sgd방식이랑 결과 값이 같은걸 보니 svm 방식이 가장 정확한가보다.
다들 정확도는 비슷비슷 하지만 여기서는 지도학습을 통한 분류가 제일
정확하게 나오는 것 같다.
근데 결국엔 가장 중요한게 정확도 아닌가?
아까 train을 훈련시켜 accuracy를 구한 것처럼 의사결정 나무의 정확도를 확인해 보면 어떻게 나올까?
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
X_train, X_test, y_train, y_test = train_test_split(digits_data,
new_label,
test_size=0.2,
random_state=15)
decision_tree = DecisionTreeClassifier(random_state=15)
decision_tree.fit(X_train, y_train)
y_pred = decision_tree.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracy결과는 : 0.9388888888888889
분류법들에 비하면 낮은데 아까 훈련한거에 비하면 정확도가 선녀인거 같다.
이왕 하는거 분류하는거에 페이크를 쓴다면 어떻게 될까?
fake_pred = [0] * len(y_pred)
accuracy = accuracy_score(y_test, fake_pred)
accuracy 결과 : 0.925
그래도 괜찮은 점수가 나왔다.
이렇게 나온 걸 보면 훈련이 잘 된거 같지만 하나 더 테스트 해보고 싶다.
그럼 여기에 오차행렬(confusion matrix)를 넣어보자
confusion matrix란? 훈련(training)을 통한 예측(prediction) 성능을 측정하기 위해
예측 value와 실제 value를 비교하기 위한 표
from sklearn.metrics import confusion_matrix #confusion matrix
confusion_matrix(y_test, y_pred)결과 :
precision recall f1-score support
0 0.97 0.96 0.97 333
3 0.58 0.67 0.62 27
accuracy 0.94 360
macro avg 0.78 0.81 0.79 360
weighted avg 0.94 0.94 0.94 360accuracy값이 나쁘지 않게 나왔다, 아니 위보다는 더 좋게 나왔다.
그래서 결론으로 가보자.
가장 중요한 결론은 결국 내가 프로그램을 동작시켰을 때의 확률이 높게 나와야 한다는 것 아닐까?
accuracy_score(y_test, y_pred), accuracy_score(y_test, fake_pred)하면 대망의 결과는 : (0.9388888888888889, 0.925) 이 값이 나왔다
아까 svm에 비하면 한참 아까운 결과지만 그래도 10에 9은 맞추는 거니까 그렇게 나쁜건 아닐지도?
