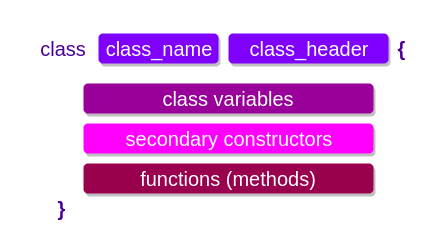
이번 장에서는 코틀린 클래스 다루는 방법을 살펴본다. 자바와 달리 코틀린은 인터페이스에 프로퍼티 선언이 들어갈 수 있고, 선언이 기본적으로 final이며 public이다.
또한 내포 클레스(nested class, 중첩 클래스)는 기본적으로 내부 클래스가 아니다. 내포 클래스에는 외부 클래스에 대한 암시적 참조가 없다. 이외에 다양한 코틀린 만의 객체지향적인 특성은 앞으로 더 본격적으로 알아가보자.
1. 클래스 계층 정의
1.1. 코틀린 인터페이스
인터페이스란, "이 기능을 제공할 거라고 약속만 하는 추상적 구조"를 뜻하며, 함수 이름만 정의하고 내용은 쓰지 않는다.
하지만 코틀린 인터페이스 안에는 추상 메서드 뿐만 아니라 구현이 있는 메서드도 정의할 수 있다. 다만 인터페이스에는 아무런 상태도 들어갈 수 없다.
interface Clickable {
fun click() //추상 메서드
}이 인터페이스를 받아 버튼을 클릭할 수 있는 클래스를 생성해보자.
class Button: Clickable {
override fun click() = println("I was clicked")
}
fun main(){
Button().click() //I was clicked, Button에 괄호를 붙여야 객체가 생성됨
}코틀린의 상속이나 구성에서 모두 클래스 이름 뒤에 콜론(:)을 붙이고 인터페이스나 클래스 이름을 적는다.
클래스는 인터페이스를 원하는 만큼 개수 제한 없이 구현할 수 있지만, 클래스는 오직 '하나만' 확장 가능하다.
상위 클래스나 상위 인터페이스에 있는 프로퍼티나 메서드를 오버라이드 할 때는 꼭 override 변경자를 사용해야 한다.
인터페이스 메서드는 디폴트 구현도 제공 가능하다. 즉, 내용이 비어있는 메서드만 넣을 수 있지 않고, 기본 출력 정도의 디폴트 구현은 가능하다는 말이다.
interface Clickable {
fun click()
fun showoff() = println("I'm clickable!") //디폴트 구현이 있는 메서드
}이렇게 디폴트 구현이 된 showOff 메서드의 경우에는 새로운 동작을 정의할 수도 있고 그냥 정의를 생략해서 디폴트 구현 그대로 사용할 수도 있다. 주의할 점은, 이런 디폴트 구현이 있는 메서드가 한 클래스에서 두 인터페이스에서 구현된다면, 어느 쪽도 선택되지 않고 컴파일러 오류를 발생시킨다.
따라서 코틀린 컴파일러는 두 메서드를 아우르는 구현을 하위 클래스에 직접 다음과 같이 구현하도록 한다.
class Button : Clickable, Focusable {
override fun click() = println("I was clicked")
override fun showOff() {
super<Clickable>.showOff()
super<Focusable>.showOff()
}
}위와 같이 상위 타입의 구현을 호출할 때는 super를 사용해 상위 타입의 이름을 <>안에 넣어 사용한다.(자바는 Clickable.super.showOff과 같은 형식)
참고로, 자바에서 코틀린의 인터페이스를 받아 구현할 때는 코틀린의 디폴트 구현을 사용할 수 없어 따로 디폴트 메서드를 직접 구현해주어야 한다.
1.2. open, final, abstract 변경자: 기본적으로 final
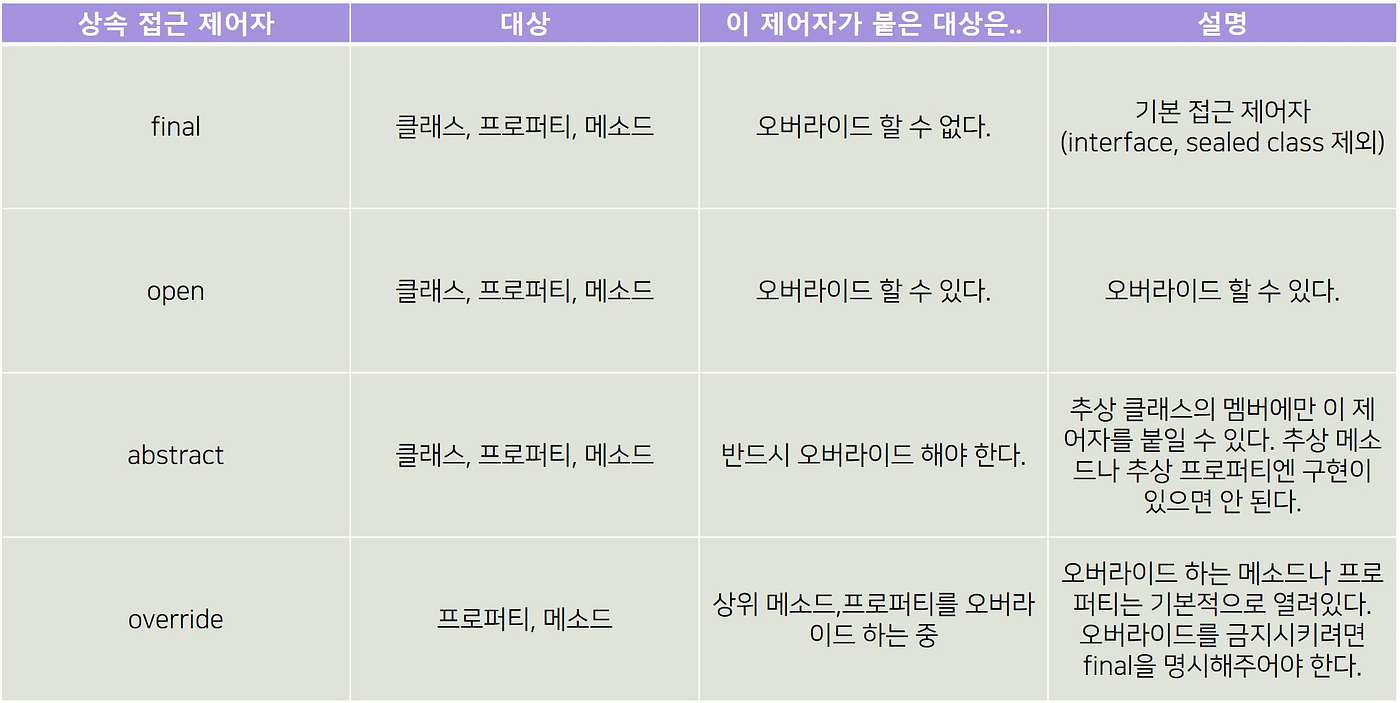
기반 클래스의 개념부터 짚고 넘어가자. 다른 클래스가 상속해서 기능을 확장하거나 재정의할 수 있는 ‘출발점’ 클래스를 기반 클래스라고 정의한다. 'final' 변경자는 상속이나 오버라이드가 불가하다는 의미이다.
기본적으로 코틀린 클래스는 하위 클래스를 만들 수도 없고, 기반 클래스의 메서드를 하위 클래스가 오버라이드 할 수 없다. 즉, 기본적으로 코틀린에서 모든 클래스와 메서드는 기본적으로 final이다.
이는 자바와 다르다. 자바는 final로 지정하지 않는 한 모든 클래스가 상속할 수 있고, 모든 메서드를 하위 클래스에서 오버라이드 할 수 있는데, 이는 편리한 반면 문제가 될 수도 있기 때문에 코틀린에서는 이러한 방식을 채택하지 않았다.
'취약한 기반 클래스(fragile base class)', 기반 클래스를 상속하는 정확한 방법을 제시하지 않는 경우, 기반 클래스의 의도와 다른 방식으로 메서드를 오버라이드 할 위험이 존재한다. 따라서 코틀린은 이러한 위험을 피하고자 다음과 같은 철학을 따른다.
"상속을 위한 설계와 문서를 갖춰라. 그럴 수 없다면 상속을 금지하라."
그래서 모든 클래스와 메서드는 기본적으로 'final'인 것이다. 따라서 어떤 클래스의 상속을 허용하려면 open 변경자를 붙여야 한다.
open class RichButton : Clickable { //열려 있음. 다른 클래스가 이 클래스 상속 가능
fun disable() //final로 하위 클래스가 오버라이드 불가
open fun animate() {}
override fun click() {} //열려있음
}기반 클래스나 인터페이스의 멤버를 오버라이드 한 경우(위에서 마지막 줄)에는 기본적으로 open으로 간주된다. 이 함수를 오버라이드 하는 것을 금지하려면 명시적으로 final로 표시해주어야 한다.
클래스의 기본적인 상속 가능 상태가 final이기 때문에 대부분의 프로퍼티가 스마트 캐스트에 활용될 수도 있는 것이다. 클래스 프로퍼티의 경우 val이면서 커스텀 접근자가 없는 경우에만 스마트 캐스트가 가능하기 때문이다.
abstract로 선언된 추상 클래스의 경우에는 항상 열려 있어서 open 변경자를 명시할 필요는 없다.
1.3. 가시성 변경자: 기본적으로 공개
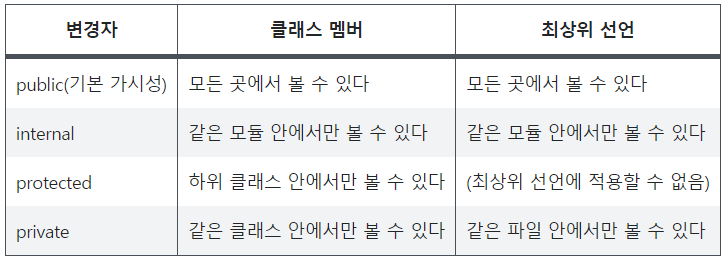
가시성 변경자란, 코드 기반에 있는 선언에 대한 클래스 외부 접근을 제어함으로써, 그 클래스에 의존하는 외부 코드를 깨지 않고도 클래스 내부 구현을 변경할 수 있다.
코틀린은 public, protected, private 변경자를 제공한다. 아무 변경자가 없으면 기본적으로 public이다.
- public: 누구나 볼 수 있음
- protected: 하위 클래스에서만 볼 수 있음
- private: 그 선언이 포함된 클래스 안에서만 볼 수 있음
- internal: 모듈 안으로만 한정된 가시성 제공
모듈이란, 함께 컴파일되는 코틀린 파일의 집합을 의미한다. ex; gradle 소스 집합, Maven 프로젝트, IntelliJ IDEA module
예시를 하나 들어보자.
internal open class TalkativeButton {
private fun yell() = println("Hey!")
protected fun whisper() = println("Let's talk!")
}
fun TalkativeButton.giveSpeech() { //pubilc 멤버가 internal 수신 타입 접근 불가
yell() //private 멤버이므로 접근할 수 없음
whisper() //protected 멤버이므로 접근할 수 없음
}public 함수인 giveSpeech 안에서 그보다 가시성이 낮은 internal 가시성은 참조하지 못하게 한다. 이러한 규칙이 어떤 함수를 호출하거나 어떤 클래스를 확장할 때 필요한 모든 타입에 접근할 수 있도록 보장해준다. 위의 코드에서 컴파일 오류를 없애려면 TalktiveButton의 가시성을 public으로 바꾸거나 giveSpeech 함수의 가시성을 internal로 바꿔야 한다.
protected 멤버는 오직 어떤 클래스나 그 클래스를 상속한 클래스 안에서만 보이기 때문에, 클래스를 확장한 함수는 그 클래스의 private이나 protected 멤버에 접근할 수 없다.
1.4. 내부 클래스와 내포된 클래스: 기본적으로 내포 클래스
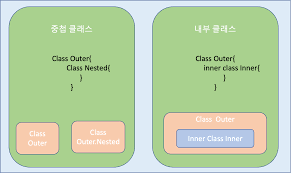
코틀린의 내포 클래스(nested class)는 명시적으로 요청하지 않는 한 바깥쪽 클래스 인스턴스에 접근이 불가하다. 이게 외부 인스턴스에 접근이 가능한 inner 클래스와의 대표적인 차이점이다.
View 요소(UI를 구성하는 화면상의 모든 객체)를 하나 만드는 코드를 예시로 들어보겠다. view 상태를 직렬화(객체의 상태를 파일, 메모리, 네트워크 전송 등에 쓰기 좋은 형식인 바이트, 문자열 등으로 변환하는 과정)하기 위해 State 인터페이스를 선언하고 Serializable을 구현한다.
import java.io.Serializable
interface State: Serializable
interface View {
fun getCurrentState(): State
fun restoreState(state: State) {}
}
class Button : View {
override fun getCurrentState(): State = ButtonState()
override fun restoreState(state: State) { /*...*/ }
class ButtonState : State { /*...*/ }
}코틀린에서 내포된 클래스에 아무 변경자가 없으면 java static 내포 클래스와 같다. 이를 내부(inner) 클래스로 변경해서 바깥쪽 클래스에 대한 참조를 포함하게 만들고 싶다면 inner 변경자를 붙여야 한다.
| 구분 | 정의 | 자바(Java) | 코틀린(Kotlin) |
|---|---|---|---|
| 내포 클래스 (바깥쪽 클래스에 대한 참조를 저장하지 않음) | 외부 클래스 인스턴스 참조 없이 독립적으로 존재하는 클래스 | static class A | class A |
| 내부 클래스 (바깥쪽 클래스에 대한 참조를 저장함) | 외부 클래스 인스턴스를 참조할 수 있는 클래스 | class A | inner class A |
내부 클래스에서 바깥쪽 클래스의 인스턴스를 가리키는 참조를 표기할 때는 this@Outer 라고 표기해주면 된다.
1.5. 봉인된 클래스: 확장이 제한된 클래스 계층 정의
상위 클래스를 표현하는 여러 하위 클래스들을 표현할 때 when식을 사용하면 편리하다. 하지만 반드시 else 분기를 넣어줘야만 한다.
하지만 디폴트 분기를 추가하게 되면 컴파일러가 when이 모든 경우를 처리하는지 제대로 검사할 수 없기 때문에 심각한 버그를 발생시킬 수 있다. 코틀린은 이런 문제를 해결하고자 sealed 클래스(봉인된 클래스)를 상위 클래스에 변경자로 붙여 이를 상속한 하위 클래스의 가능성을 제한시킨다.
sealed class(봉인 클래스)는 상속 가능한 자식 클래스의 종류를 “컴파일 시점에” 딱 정해 놓는 클래스다.
sealed class Expr {
class Num(val value: Int) : Expr()
class Sum(val left: Expr, val right: Expr) : Expr()
}
fun eval(e: Expr): Int =
when (e) {
is Num -> e.value
is Sum -> eval(e.right) + eval(e.left)
}when 식에서 sealed 클래스의 모든 하위 클래스를 처리한다면 디폴트 분기가 필요 없다. 컴파일러가 여러분이 모든 분기를 처리하는지 확인해준다. 또한 sealed 변경자는 클래스가 추상 클래스임을 명시해준다.
코틀린에서는 클래스를 확장할 때나 인터페이스를 구현할 때 모두 콜론(:)을 사용한다는 것을 기억하자.
2. 뻔하지 않은 생성자나 프로퍼티를 갖는 클래스 선언

객체지향 언어에서 클래스는 보통 생성자를 하나 이상 추가할 수 있는데, 코틀린에선 주 생성자(클래스 본문 밖에서 정의)와 부 생성자(클래스 본문 안에서 정의)를 구분한다. 또한 초기화 블록을 통해 초기화 로직을 추가할 수 있다.
2.1. 주 생성자와 초기화 블록
이전에 코틀린에서 클래스를 간단히 선언하는 방법을 공부했었다.
class User(val nickname: String)이렇게 클래스 이름 뒤에 오는 중괄호가 아닌, 괄호로 둘러싸인 코드를 주 생성자라고 한다. 위 코드를 명시적으로 푼 선언은 아래와 같다.
class User constructor(_nickname: String) {
val nickname: String
init {
nickname = _nickname
}
}'constructor' 키워드는 주 생성자나 부 생성자 정의를 시작할 때 사용한다.
'init' 키워드는 초기화 블록을 시작한다.
초기화 블록에는 클래스의 객체가 만들어질 때(인스턴스화 될 때) 실행될 초기화 코드가 들어가며, 주 생성자와 함께 사용된다. 주 생성자는 초기화 블록이 필요하다.
생성자 파라미터 맨 앞의 '_'는 프로퍼티와 생성자 파라미터를 구분해준다. 자바에서 흔히 쓰는 this.nickname = nickname의 this 역할이라고 보면 된다. constructor는 별다른 어노테이션이나 가시성 변경자가 없다면 생략하는 편이 낫다. 따라서 위의 명시적 선언을 다음과 같이 추려서 적을 수 있다.
class User(_nickname: String) {
val nickname = _nickname
}초기화 블록 안에서만 주 생성자의 파라미터(위 코드에서 '_nickname')를 참조할 수 있다는 점에 유의하자. 위 코드를 다시 한 번 간추려 val 키워드를 앞에 추가하는 식으로 더욱 간략히 쓸 수 있다. 아까 그냥 처음거잖아 ㅆ
class User(val nickname: String)클래스의 인스턴스를 만들려면 new 키워드 없이 생성자를 직접 호출하면 된다.
class User(val nickname: String,
val isSubscribed: Boolean = true)
fun main() {
val alice = User("Alice")
println(alice.isSubscribed)
val bob = User("Bob", false)
println(bob.isSubscribed)
val carol = User("Carol", isSubscribed = false)
println(carol.isSubscribed)
}참고로 클래스를 정의할 때 별도로 생성자를 정의하지 않으면 컴파일러가 자동으로 아무 일도 하지 않는 인자가 없는 디폴트 생성자를 만들어준다. 만약 기반 클래스의 생성자가 아무 인자도 받지 않지만, 해당 클래스를 상속하는 하위 클래스는 반드시 기반 클래스의 생성자를 호출하여야 하는데, 이때 기반 클래스의 생성자가 아무 인자도 받지 않는다면 호출할 때 빈괄호를 추가해주면 된다.
class RadioButton: Button()인터페이스는 생성자가 없어 어떤 클래스가 인터페이스를 구현하는 경우에는 아무 괄호도 붙지 않는다. 이 특징으로 기반 클래스와 인터페이스를 쉽게 구별할 수 있다.
어떤 클래스를 외부에서 인스턴스화하지 못하게 막고 싶은 경우에 private 생성자를 붙이면 된다. 자바에서는 유틸리티 클래스(편의 기능을 모아둔 클래스, 주로 static으로 구성)이나 싱글턴 클래스(프로그램 전체에서 하나의 인스턴스만 존재하도록 보장하는 클래스)에 대해 private 생성자를 정의해서 클래스를 다른 곳에서 인스턴스화 하지 못하게 막는데, 코틀린의 경우에는 정적 유틸리티 함수 대신 최상위 함수를 사용하거나, 싱글턴을 사용하고 싶은 경우에는 그냥 object로 객체를 선언해주면 된다.
public class MathUtils { //java에서 유틸리티 클래스 정의
public static int add(int a, int b) {
return a + b;
}
}
int result = MathUtils.add(3, 5); //사용// MathUtils.kt
fun add(a: Int, b: Int): Int { //파일의 최상단(클래스 외부)에 정의
return a + b
}
val result = add(3, 5) // 바로 호출 가능2.2. 부 생성자: 상위 클래스를 다른 방식으로 초기화
대부분의 경우에 간단한 주 생성자 문법으로만 클래스를 정의해도 괜찮지만, 때때로 부 생성자가 필요한 경우가 있다. 다음과 같은 예를 확인해보자.
public class Downloader {
public Downloader(String url){//java에서 생성자가 두 개인 경우
//
}
public Downloader(URI uri){
//
}
}open class Downloader { //위의 클래스를 코틀린에서 정의
constructor(url: String?){ //?는 null 타입을 허용한다는 뜻
//
}
constructor(uri: URI?){
//
}
}부 생성자는 constructor 키워드로 시작하고, 필요에 따라 얼마든지 많이 부 생성자를 선언해도 된다.
class MyDownloader: Downloader {
constructor(url: String?) : super(url){
}
constructor(url: String?) : super(uri) {
}
}여기서 두 개의 부 생성자는 super() 키워드를 사용해 자신에 대응하는 상위 클래스 생성자를 호출해 초기화를 위임(부모 클래스에게 초기화를 넘겨서 초기화를 맡김)한다. 반대로 this() 키워드를 사용해 같은 클래스의 다른 생성자에게 생성을 위임할 수 있다.
class MyDownloader: Downloader {
constructor(url: String?) : this(URI(url)){ //아래의 생성자에게 위임
}
constructor(url: String?) : super(uri) {
}
}클래스에 주 생성자가 없다면 모든 부 생성자는 반드시 상위 클래스를 초기화하거나 다른 생성자에게 생성을 위임해야 한다는 걸 기억하자. 보통 부 생성자는 자바와의 상호운용성이 생성의 주 목적이다.
2.3. 인터페이스에 선언된 프로퍼티 구현
코틀린에서는 인터페이스에 추상 프로퍼티 선언을 넣을 수 있다.
interface USer {
val nickname: String
}이는 이 인터페이스를 구현하는 클래스가 nickname의 값을 얻을 수 있는 방법을 제공해야 한다는 뜻이다. 이 인터페이스를 구현하는 방법을 몇 가지 살펴보자.
fun getNameFromSocialNetwork(accountId: Int) = "soc:$accountId"
class PrivateUser(override val nickname: String) : User //주 생성자에 있는 프로퍼티
class SubscribingUser(val email: String) : User {
override val nickname: String
get() = email.substringBefore('@') //커스텀 게터
}
class SocialUser(val accountId: Int) : User {
override val nickname = getNameFromSocialNetwork(accountId) //프로퍼티 초기화 식
}
fun main() {
println(PrivateUser("test@kotlinlang.org").nickname) //test@kotlinlang.org
println(SubscribingUser("test@kotlinlang.org").nickname) //test
} SubscribingUSer와 SocialUser의 nickname 구현 차이에 주의하라. 전자는 nickname이 호출될 때마다 substringBefore를 호출해 계산하는 커스텀 게터를 활용하고, SocialUser의 nickname은 객체 초기화를 계산한 데이터를 뒷받침하는 필드에 저장했다가 불러오는 방식을 활용한다.
함수 대신 프로퍼티를 주로 사용하는 경우
- 예외를 던지지 않음
- 계산 비용이 적게 듬(최초 실행 후 결과를 cache해 사용할 수 있는 경우)
- 객체 상태가 바뀌지 않는 경우
2.4. Getter와 Setter에서 뒷받침하는 필드에 접근
바로 앞에서 봤던 두 가지 유형을 합쳐 활용하는 유형의 프로퍼티를 만드는 방법을 살펴보자. 어떤 값을 저장하되 그 값을 변경하거나 읽을 때마다 정해진 로직을 실행하는 유형의 프로퍼티인데, 이런 경우엔 프로퍼티를 뒷받침하는 필드에 접근할 수 있어야 하므로 변경 가능한 프로퍼티를 정의하되 세터에서 프로퍼티를 값을 바꿀 때마다 약간의 코드를 추가한다.
class User(val name: String) {
var address: String = "unspecified" //가변 프로퍼티(var)
set(value: String) { //커스텀 setter
println(
""" //원시 문자열만들기(""")
Address was changed for $name:
"$field" -> "$value".
""".trimIndent()
)
field = value
}
}
fun main() {
val user = User("Alice")
user.address = "Christoph-Rapparini-Bogen 23, 80639 Muenchen"
}접근자의 본문에서는 'field'라는 식별자를 통해 뒷받침하는 필드에 접근할 수 있다. 프로퍼티의 getter·setter 안에서만 접근 가능한, 해당 프로퍼티의 실제 저장소를 가리키는 특별한 키워드로, 커스텀 getter & setter를 정의할 때 주로 사용한다.
2.5. 접근자의 가시성 변경
접근자의 가시성은 기본적으로는 프로퍼티의 가시성과 같지만, 원한다면 get이나 set 앞에 가시성 변경자를 추가해서 접근자의 가시성을 변경할 수 있다.
class LengthCounter {
var counter: Int = 0
private set // counter 프로퍼티에 대한 setter 접근 범위 제한
fun addWord(word: String) {
counter += word.length
}
}
fun main() {
val lengthCounter = LengthCounter()
lengthCounter.addWord("Hi!")
println(lengthCounter.counter) //3
}counter에 대한 접근성을 getter는 기본적으로 public으로 설정되어 어디서든 읽을 수 있지만, setter를 private으로 설정함으로써 클래스 내부에서만 counter를 수정할 수 있도록 해놓아 외부에서는 수정을 불가하게 해놓는다.
3. 컴파일러가 생성한 메서드: Data 클래스와 클래스 위임

자바에서 equals(두 객체 같은지 판단), hashCode(객체의 해시코드 제공), toString(객체에 대한 텍스트 표현 제공)과 같은 기계적으로 구현할 수 있는 몇 가지 메서드가 정의돼 있다. 이런 메서드들은 편리하긴 하지만, 코드베이스의 번잡성을 줄여주진 못하는데, 코틀린 컴파일러는 이런 메서드들을 기계적으로 생성하는 작업을 보이지 않는 곳에서 해줄 수 있다. 이것 또한 코틀린의 특징이 잘 두드러지는 부분이다.
3.1. 모든 클래스가 정의해야 하는 메서드
앞서 언급한 세 가지 메서드가 코틀린에서 어떻게 자동으로 생성되고 사용되는지 예시를 통해 살펴보자.
class Customer(val name: String, val postalCode: Int)1. toString
자바처럼 코틀린의 모든 클래스도 인스턴스의 문자열 표현을 얻을 방법을 제공한다. 그 예는 아래와 같다.
class Customer(val name: String, val postalCode: Int) { //두 개의 프로퍼티를 가진 클래스 선언
override fun toString() = "Customer(name=$name, postalCode=$postalCode)" //커스텀 문자열을 반환하도록 재정의
}
fun main() {
val customer1 = Customer("Alice", 34652)
println(customer1) //Customer(name=Alice, postalCode=34562)
}위 코드를 보면, 객체를 그냥 출력했을 뿐인데 문자열이 출력되는데, 그 이유는 println 내부에서 toString()을 자동으로 호출하기 때문이다.
2. equals()
자바에서는 '=='를 기본적으로 기본 타입과 참조 타입을 비교할 때 사용된다. 두 비교방식에 차이가 있기에, 자바에서는 객체의 동등성을 판단할 때는 equals를 호출해야 한다.
반면에 코틀린에서는 == 연산자가 두 객체를 비교하는 기본적인 방법으로서, 내부적으로 equals를 호출하면서 객체를 비교한다.
따라서 equals를 오버라이드 하면 ==를 통해 안전하게 그 클래스의 인스턴스를 비교할 수 있다.
class Customer(val name: String, val postalCode: Int) {
override fun equals(other: Any?): Boolean {
if (other == null || other !is Customer)
return false
return name == other.name &&
postalCode == other.postalCode
}
override fun toString() = "Customer(name=$name, postalCode=$postalCode)"
}
fun main() {
val processed = hashSetOf(Customer("Alice", 342562))
println(processed.contains(Customer("Alice", 342562)))
}
앞서 Ch2에서 다뤘지만 코틀린의 is연산자는 어떤 값의 타입을 검사한다. 위 코드에 나온 other과 null과 관련된 내용은 나중에 7장에서 더 자세히 다룬다.
코틀린에서는 override 변경자는 필수여서 올바르지 않은 형태로 오버라이딩 되면 바로 컴파일러가 오류를 띄운다. 하지만 아직 Customer 클래스는 올바르게 작동하지 않을 확률이 높은데, 그 이유인 hashCode에 대해서 알아보자.
3. hashCode()
hashCode()는 자바와 코틀린 둘 다에서 객체의 “해시값(정수)”을 반환하는 메서드다. 이 값은 주로 HashSet, HashMap, HashTable 같은 해시 기반 컬렉션에서 객체를 빠르게 찾기 위해 사용된다.
자바에서는 equals를 오버라이드 할 때 반드시 hashCode도 함께 오버라이드 해야한다.
JVM 언어(코틀린도 JVM 위에서 돌아감)에서는 "equals()가 true를 반환하는 두 객체는 반드시 같은 hashCode()를 반환해야 한다."라는 규정이 있는데, 이를 어기고 hashCode를 구현하지 않은 경우에는 equals를 구현한 클래스는 제대로 동작하지 않는다.
따라서 Cusotmer 클래스에는 다음과 같이 hashCode를 구현해주어야 한다.
override fun hashCode(): Int = name.hashCode() *31 + postalCode3.2. 데이터 클래스: 모든 클래스가 정의해야 하는 메서드를 자동으로 생성
어떤 클래스가 데이터를 저장하는 역할만 수행하려면 toString, equals, hashCode를 반드시 오버라이드 해야하는데, 코틀린은 data라는 변경자를 클래스 앞에 붙이면 필요한 메서드를 컴파일러가 자동으로 만들어주고, 이런 클래스를 '데이터 클래스'라고 한다.
데이터 클래스는 방금 언급한 세 메서드 뿐만 아니라 copy() 메서드를 포함한 여러가지 메서드들을 더 생성해준다.
데이터 클래스의 프로퍼티 꼭 읽기 전용인 val일 필요는 없으나, 읽기 전용으로 만들어야 다중 스레드 프로그램과 같은 여러 상황에서 신경 쓸 사항이 적어지기 때문에, 읽기 전용으로 만들기를 권장한다.
copy 메서드는 객체를 복사하면서 일부 프로퍼티를 바꿀 수 있게 해주는 메서드이다.
복사를 하게 되면 객체를 메모리에서 직접 바꾸는 대신 원본과 다른 생명주기를 가지면서 원본에는 다른 영향을 전혀 끼치 않는다는 점이 copy 메서드를 쓰는 메리트이다.
data class Customer(val name: String, val postalCode: Int)
fun main() {
val bob = Customer("Bob", 973293)
println(bob.copy(postalCode = 382555))
//Customer(name=Bob, postalCode=382555)
}참고로 자바에도 데이터 클래스와 비슷한 역할을 하는 record(@JvmRecord)가 자바14부터 도입되었으나, copy와 같은 편의 메서드를 제공해주지는 않는다.
3.3. 클래스 위임: by 키워드

보통 대규모 객체지향 시스템을 설계할 때의 대표적인 취약점은 '상속'에서 발생한다. 상속이 일어날 때 상위 클래스의 내용이 바뀌면서 전체적인 코드가 정상적으로 작동하지 못하는 경우가 발생할 수 있다.
앞서 언급했듯이 기본적으로는 final로 코드를 설정해서 상속을 제한하고, 상속을 가능하게 하려면 open 변경자를 붙이는 식으로 이런 혼란을 방지한다.
하지만 종종 상속을 허용하지 않는 클래스에게 새로운 동작을 추가해야할 때가 있는데, 이럴 때 decorator 패턴을 주로 사용한다.
핵심은 상속을 허용하지 않는 클래스 대신 사용할 수 있는 새로운 클래스를 만들되, 기존 클래스와 같은 인터페이스를 데코레이터가 제공하고 기존 클래스를 데코레이터 내부 필드로 유지하는 것이다. 이때 새로 정의해야 하는 기능은 데코레이터의 메서드로 새로 정의하고, 기존 기능이 그대로 필요한 부분은 데코레이터의 메서드가 기존 클래스의 메서드에게 요청을 전달(forwarding)한다.
하지만 치명적인 단점이 있다. 이를 활용하기 위한 준비 코드가 너무 길다.(그래서 보통 인텔리제이 IDEA가 기본적인 준비코드를 기본적으로 제공) 그래서 이런 '위임'의 기능을 코틀린에서 자체적으로 제공한다는 것이 코틀린의 또 하나의 대표적 장점이다.
코틀린에서 “위임(Delegation)” 이란 자신이 해야 할 일을 다른 객체에 맡기는 것을 말한다. 코드에서 “이 기능은 저 객체한테 부탁할게” 하고 책임을 넘기는 방식이다. 'by' 키워드를 통해 위임을 실현한다.
interface Printer {
fun printMessage()
}
class RealPrinter : Printer {
override fun printMessage() = println("진짜 프린터가 출력합니다")
}
// Printer를 직접 구현하지 않고 RealPrinter에게 위임
class PrinterDelegate(printer: Printer) : Printer by printer
fun main() {
val p = PrinterDelegate(RealPrinter())
p.printMessage() // "진짜 프린터가 출력합니다"
}위임이란 “상위 클래스의 특정 메서드만 수정하고 싶을 때” 상속 대신 쓸 수 있는 기법 중 하나이며, 꼭 그럴 때만 쓰는 건 아니고, 유연하고 느슨한 결합을 위해 더 넓게 쓰인다.
4. Object 키워드: 클래스 선언과 인스턴스 생성을 한꺼번에

코틀린에서는 object 선언을 사용하는 몇 가지 경우가 있다.
- 객체 선언(object declaration): 싱글턴(하나의 인스턴스만 존재하도록 보장하는 클래스)을 정의하는 한 가지 방법
- 동반 객체(companion object): 어떤 클래스와 관련이 있지만 호출하기 위해 그 클래스의 객체가 필요하지 않은 메서드와 팩토리 메서드를 담을 때 쓰임
- 객체 식: 자바의 익명 내부 클래스 대신 쓰임
4.1. 객체 선언: 싱글턴을 쉽게 만들기
객체지향 시스템 설계 시 인스턴스가 하나만 필요한 클래스가 유용한 경우가 많은데, 자바에서는 보통 클래스의 생성자를 private으로 제한하고 정적인 필드에 그 클래스의 유일한 객체를 저장하는 sinlgeton pattern을 사용한다.
코틀린에서는 객체 선언 기능을 통해 싱글턴을 언어에서 기본 제공한다.
코틀린에서 객체를 object 키워드로 시작 시 객체 선언 안에 프로퍼티, 메서드, 초기화 블록 등이 들어갈 수 있지만 생성자를 쓸 수는 없다. 싱글턴 객체는 객체 선언문이 있는 위치에서 생성자 호출 없이 즉시 만들어지기 때문이다.
객체 선언도 클래스나 인스턴스를 상속할 수 있다.
object CaseInsensitiveFileComparator : Comparator<File> {
override fun compare(file1: File, file2: File): Int {
return file1.path.compareTo(file2.path,
ignoreCase = true)
}
}
fun main() {
println(CaseInsensitiveFileComparator.compare(
File("/User"), File("/user")))
val files = listOf(File("/Z"), File("/a"))
println(files.sortedWith(CaseInsensitiveFileComparator))
}위의 코드가 싱글턴의 예시인 이유는, object 키워드를 사용함으로써 object 키워드로 정의된 CaseInsensitiveFileComparator는 클래스 선언 + 단일 인스턴스 생성이 동시에 된 것으로, CaseInsensitiveFileComparator라는 타입의 인스턴스가 프로그램 전체에서 단 하나만 존재하게 된다. 그래서 매번 new나 FileComparator() 같은 생성자를 호출하지 않고, CaseInsensitiveFileComparator라는 이름으로 바로 접근해서 쓸 수 있다.
4.2. 동반 객체: 팩토리 메서드와 정적 멤버가 들어갈 장소
코틀린은 자바 static 키워드를 지원하지 않기에 따로 클래스 안에 정적인 멤버가 없다. 따라서 패키지 수준의 최상위 함수와 객체 선언을 활용한다.
팩토리 메서드는 객체를 생성하는 과정을 직접 생성자 호출(new, constructor)로 하지 않고, 전용 메서드(보통 create, of, from, valueOf 등)를 통해서 객체를 만드는 기법이다.
클래스 안에 정의된 객체 중 하나에 companion이라는 표시를 붙이면, 객체 멤버에 접근할 때 자신을 감싸는 클래스의 이름을 통해 직접 사용할 수 있게 된다. 이것이 동반 객체다.
코틀린의 동반 객체의 경우 컴파일러가 동반 객체를 내부적으로 static 필드로 바꿔주기 때문에 자바의 static처럼 클래스 이름을 통해 직접 사용이 가능해진다. 또한 동반 객체는 자신을 둘러싼 클래스의 모든 private 멤버에 접근할 수 있다.
확실한 장점은 부 생성자 대신에 동반 객체를 활용해서 팩토리 메서드를 써서 객체지향의 장점을 살릴 수 있다는 점이다.
class User(val nickname: String) {
constructor(email: String) : this(email.substringBefore('@'))
constructor(accountId: Int) : this(getNameFromSocialNetwork(accountId))
}위처럼 부 생성자를 활용해 구현했을 경우에는 메서드 이름이 지정되지 않아 의도가 불분명해진다.
class User private constructor(val nickname: String) {
companion object {
fun newSubscribingUser(email: String) = //팩토리 메서드
User(email.substringBefore('@'))
fun newSocialUser(accountId: Int) =
User(getNameFromSocialNetwork(accountId))
}
}하지만 이런식으로 팩토리 메서드를 활용해 메서드의 의도를 분명하게 드러낸다면 가독성도 증가하고, 주 생성자를 private으로 막고 외부에서는 무조건 팩토리 메서드만 써서 객체 생성을 강제하는 식으로 캡슐화를 더욱 극대화할 수 있게 된다.
4.3. 동반 객체를 일반 객체처럼 사용
동반 객체는 클래스 안에 정의된 일반 객체이기에, 다른 객체 선언처럼 이름을 붙이거나, 인터페이스를 상속하거나, 확장 함수나 프로퍼티를 정의할 수 있다.
코틀린 표준 라이브러리의 Random 클래스에도 동반 객체가 존재한다.(기본 난수 생성기 제공)
클래스에 동반 객체가 있으면 객체 안에 함수를 정의함으로써 클래스에 대해 호출할 수 있는 확장 함수를 만들 수 있다.
구체적으로 얘기하자면, C라는 클래스 안에 동반 객체가 있고, 그 안에 func를 정의하면 외부에서는 C.func()로 이 함수를 호출 가능하다는 말이다.
4.4. 객체 식: 익명 내부 클래스를 다른 방식으로 작성
자바의 익명 내부 클래스를 대신하는 익명 객체(anonymous object)를 정의할 때도 object 키워드를 쓴다.
*익명 객체: 이름 없는 클래스를 즉석에서 정의하고 인스턴스를 생성하는 것
익명 객체를 활용하면 따로 인터페이스를 구현하지 않아도 되고, 혹은 하나, 여러 개의 인터페이스를 구현할 수 도 있게 되기에 상당히 유연하다.
val listener = object { //익명 객체 생성
val name = "temp"
fun printName() = println(name)
}
fun main() {
listener.printName() // temp
}5. 인라인 클래스: 부가 비용 없이 타입 안정성 추가
인라인 클래스란, 값을 감싸는 작은 클래스로서, 런타임에서는 진짜 객체를 생성하지 않고 → 내부 값(primitive, reference)을 그대로 사용하게 최적화된 클래스를 말한다.
인라인 클래스는 'value' 키워드를 사용하고 @JVMInline 어노테이션을 붙여 활용한다. 인라인 클래스를 사용함으로써 타입 안정성을 확실히 보장할 수 있고, 불필요하게 객체를 생성하는 비용을 줄일 수 있다. 아래의 예시를 보자.
//userID, email 다 String이라 컴파일 시 잘못 넣어도 못잡음
fun sendMessage(userId: String, message: String) { ... }
fun sendEmail(email: String, message: String) { ... }
//인라인 클래스 활용 시 잘못된 타입 넣으면 컴파일 에러로 잡힘
@JvmInline value class UserId(val id: String)
@JvmInline value class Email(val address: String)
fun sendMessage(userId: UserId, message: String) { ... }
fun sendEmail(email: Email, message: String) { ... }즉, 쉽게 말하면 인라인 클래스는 값을 감싸고 있는 클래스지만, 런타임에 객체로 존재하지 않고 값 자체로 치환되기에, 쓸데없이 객체를 더 생성하지 않아도 되는 것이다.
하지만 명확한 제약이 존재한다.
- 인라인 클래스는 오직 하나의 프로퍼티만 가진다.
- 인라인 클래스는 클래스 계층(상속받거나, 상속하거나)에 참여하지 않는다.
