리스트(List)란
리스트는 대표적인 자료구조 중 하나로, '줄 세워져 있는 데이터' 또는 '쭉 늘어선 데이터'를 의미한다.
리스트라는 자료구조를 생각했을 때, 필요한 작업을 대략적으로 생각해보면 i번째 자리에 원소 삽입, 특정 자리의 원소 삭제, 리스트의 사이즈, 등 여러 작업 목록을 생성해낼 수 있는데, 자바에서는 언어 자체에서 리스트를 기본 자료구조로 생각하진 않고, java.util 패키지에서 이를 제공한다.
리스트의 구현 방법에는 다음과 같이 배열을 활용한 방법과 연결 리스트를 활용하는 방법 크게 두 가지가 있다.
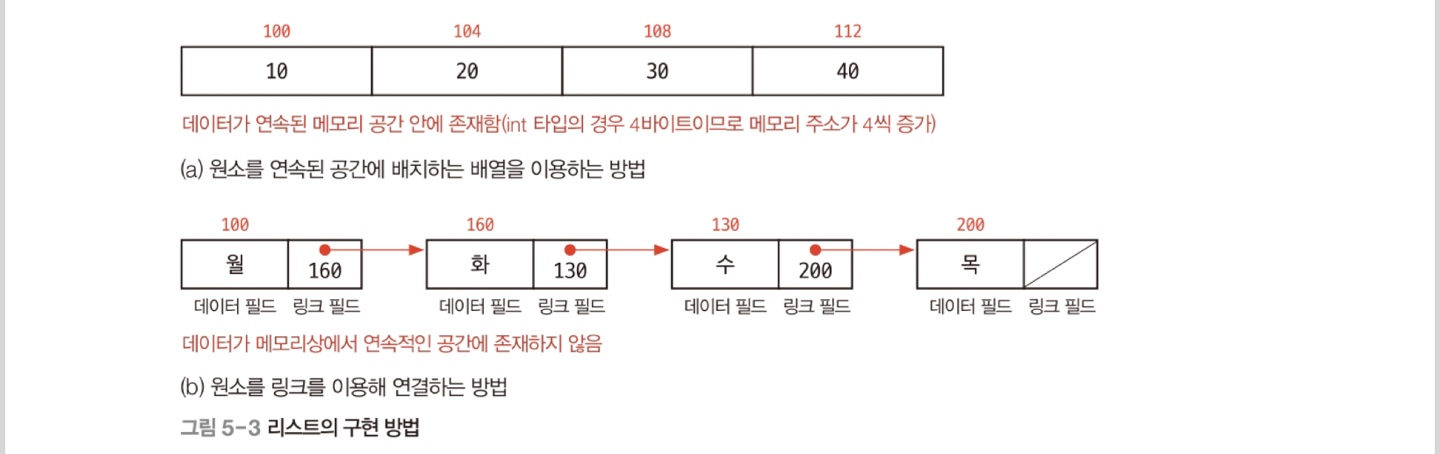
배열의 경우에는 자료를 순서대로 연속하여 저장해 논리적인 순서와 물리적인 순서가 일치한다. 반면에, 연결 리스트의 경우 물리적 위치나 순서와 상관없이 링크에 의해 논리적인 순서를 표현한다.
배열 리스트의 경우 공간의 낭비가 심하다는 단점이 있다. 미리 공간의 크기를 충분히 확보해두어야 나중에 문제될 일이 생기지 않고, 연결 리스트는 이런 배열의 단점인 공간 낭비를 피할 수 있게 해주는 자료로, 동적 할당 방식을 따른다.
배열 리스트
배열 리스트 객체 구조 필드에서 제공하는 대표적인 메소드들은 다음과 같다.

배열 리스트의 작업을 하나씩 알아보도록 하자.
- 원소 삽입
리스트에서는 보통 규칙 없이 저장되므로 원소를 삽입하려면 어디에 넣을지에 관한 정보도 함께 주어져야 한다. 예를 들어, 특정 값을 리스트의 n번째 원소로 삽입하려고 한다면, n번째 뒤의 원소들을 오른쪽으로 한칸씩 시프트해서 빈 공간을 만들어낸 후, 그 자리에 특정 값을 삽입해야 한다.
add(k, x):
if(numItems >= item.length || k < 0 || k > numItems)
/에러처리/
else
for i <- numItems-1 down to k
item[i+1] <- item[i]
item[k] <- x
numItems++이 코드가 배열 리스트의 k번째 자리에 원소 x를 삽입하는 알고리즘을 보여준다.
예외적으로, 리스트의 맨 뒤에 원소를 추가하는 경우는 다른 원소들을 시프트할 필요성이 없어진다. 따라서, append(x)라는 메소드를 사용하면 쉽게 맨 끝에 원소를 삽입할 수 있다.
-
원소 삭제
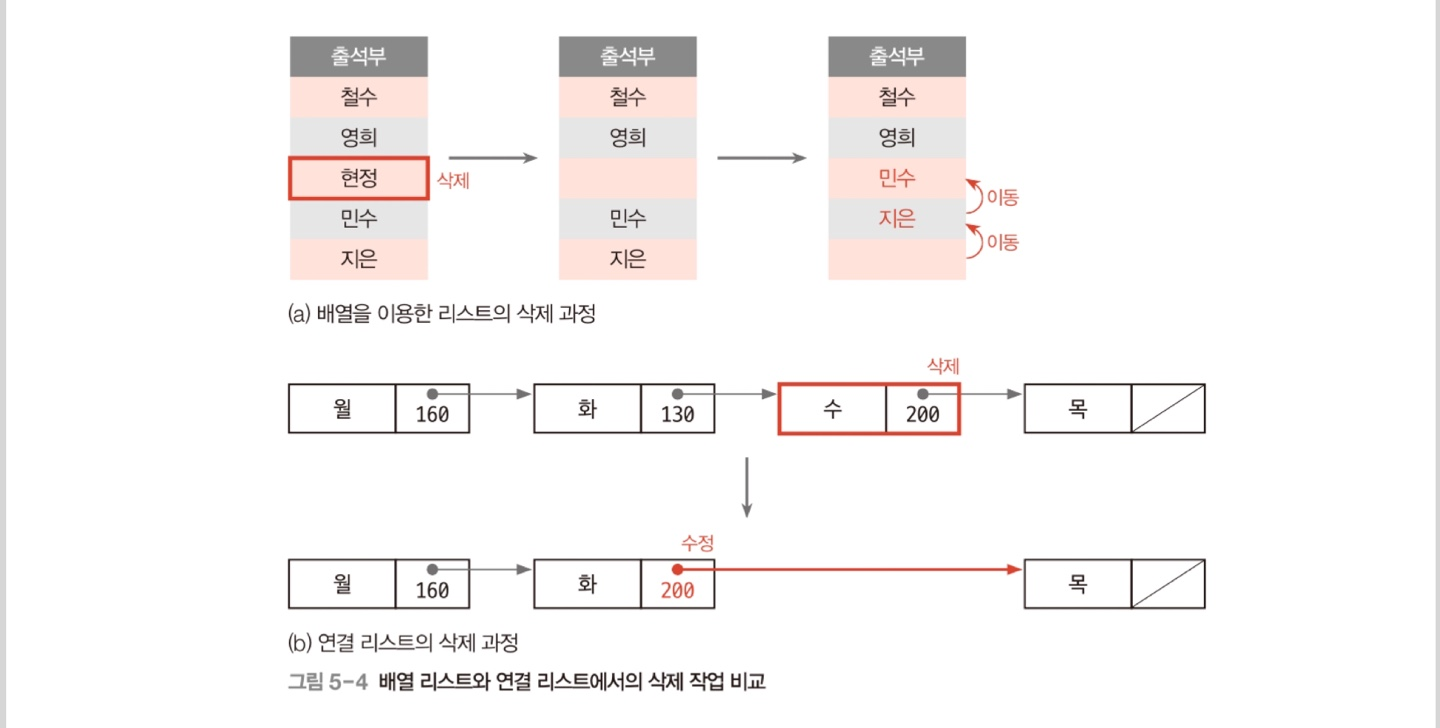
리스트에서 원소를 삭제할 때는 특정 위치의 원소를 삭제하게 할 수도 있고, 특정 원소를 삭제하게 할 수도 있다.특정 위치의 원소를 삭제하는 경우는 remove()라는 메소드를 통해 구현할 수 있고, 특정 원소를 삭제하는 경우는 반복문을 통해 배열을 돌면서 해당 원소를 찾아낸 후, 해당 원소를 삭제하는 식으로 구현할 수 있다. 두 가지 경우 모두 삭제 후 삭제된 원소의 다음 원소부터 맨 마지막 원소까지 모두 좌시프트를 해야 한다.

-
기타
삽입, 삭제 외의 배열 리스트의 i번째 원소 찾아내기, 특정 원소 다른 원소로 대체하기, 특정 원소가 몇 번째 원소인지 알아내기 등의 작업은 순서대로 get(), set(), indexOf()로 구현해낼 수 있다.
연결 리스트
연결 리스트(Linked List)는 배열의 공간 낭비를 피할 수 있는 자료구조이다. 연결 리스트는 원소를 저장하는 필드와, 다음 노드를 가리키는 필드 두 개로 구성되며, 원소를 저장하는 공간에는 정수나 실수와 같은 기초타입 뿐만 아니라 클래스의 객체가 들어갈 수도 있다. 아래의 그림이 연결 리스트의 일반적인 형태를 보여준다.

연결 리스트의 객체 구조 및 메소드들은 배열 리스트와 동일하다. add, remove, get, set 등이 그대로 다 존재한다.
연결 리스트의 작업들은 다음과 같다.
-
원소 삽입
연결 리스트에서 중간에 노드를 삽입하려면, 직전 노드를 가리키는 레퍼런스 prevNode가 존재해야 한다. 그리고 prevNode와 다음 노드 사이에 newNode를 삽입하면 된다. 이는 맨 뒤에 노드를 삽입할 때도 동일하지만, 맨 앞에 노드를 삽입하기 위해서는 head값을 수정해야 한다. 이에 해당되는 알고리즘은 다음과 같다.

이런식으로 두 가지 경우로 나누지 않아도, 더미(Dummy) 헤드 노드라는 원소가 들어있지 않은 가짜 노드를 존재시키면 위의 경우처럼 두 가지로 나누지 않아도 된다.
-
원소 삭제
원소 삭제의 경우에는 레퍼런스 prevNode가 직전 노드를 가리키도록 하고, 그 직전 노드가 바로 삭제 다음 노드로 건너뛰어 링크하도록 만든다. 이 경우에도 더미 헤드 노드를 존재시키면 알고리즘이 더 간단해진다. 이는 다음과 같다.

-
기타 작업
기타 작업들은 배열 리스트의 메소드들과 거의 동일하다.
배열 리스트와 연결 리스트의 비교
간단히 정의하자면 배열 리스트는 정적이고, 연결 리스트는 동적이라고 할 수 있다. 배열 리스트는 연속된 공간에 원소를 저장하는 반면, 연결 리스트는 공간의 연속성이 없어 정렬이나 검색 작업을 하는 데에 있어 배열 리스트에 비해 시간이 더 걸린다.
리스트에서 어떤 원소를 찾는 작업을 '검색'이라고 하는데, 정렬된 배열일수록 검색의 시간은 줄어든다. 정렬된 상태의 배열 리스트에서 원소를 비교적 빠른 시간에 검색할 수 있게 하는 알고리즘이 있는데, 이진 탐색 알고리즘(binarysearch)이다.
이진 탐색은 한 번 호출할 때마다 문제의 크기가 반으로 줄어들기에 시간적으로 훨씬 빠르게 원하는 원소를 찾아낼 수 있다는 장점이 있다. 알고리즘은 다음과 같다.

이미지 출처: [쉽게 배우는 자료구조 with 자바] - 문병로 &
