Recursion의 정의
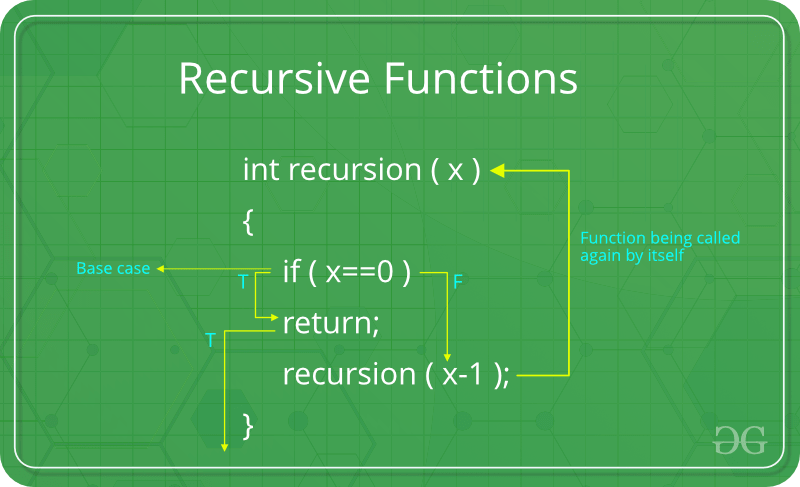
재귀란, 문제를 더 작은 문제들로 나누어 해결해가는 문제 해결 과정이다. 문제를 해결하기 위해 자기 자신을 호출하는 방식으로 문제를 풀어나간다. 다른 말로 '자기 호출'이라고 표현하기도 한다.
이는 수학적 귀납법과도 밀접한 연관이 있다. 1부터 n까지 곱하는 것을 우리는 n!(n factorial)으로 표현한다. 여기서 맨 끝의 n만 제외하면 (n-1)!이 되는데, 이것은 크기가 n인 factorial은 n-1인 factorial을 포함한다고 할 수 있다. 이처럼 어떤 문제나 함수 등이 자신과 성격이 똑같지만, 크기가 더 작은 문제를 하나 이상 포함하고 있을 때, 자료구조가 재귀적 구조를 지닌다고 한다.

앞서 언급한 factorial을 재귀를 활용한 자바 코드로 짜보면 이와 같다. factorial 함수 안에 n-1 크기의 동일한 함수가 포함되어 코드가 효율성 있게 짜진 것을 확인할 수 있다.
Recursoin으로 발생할 수 있는 오류
- Stack Overflow: 스택 메모리가 초과되어 더 이상 사용할 수 없을 때 발생하는 오류로, 재귀 함수 호출이 과도하게 발생할 때 나타나는 오류이다.

다음과 같이 올바른 기저 조건(base case, 첫 번째 자연수 n에 대해 조건이 성립함을 증명하는 과정)가 설정되지 않아, factorial 함수가 계속 factorial(n-1)을 호출해 스택에 계속 쌓이게 된다. 이렇게 되면 프로그램은 더 이상 함수 호출을 처리할 메모리를 확보할 수가 없어 stackOverflowError가 발생한다.
따라서, 올바른 재귀 함수의 정의를 위해서는, 처리하려는 작업의 더 '작은' 버전을 포함시킴과 동시에 궁극적으로 기저 조건을 포함하고 있어야 한다.
Recursion의 시간복잡도
계속 등장하는 factorial 함수(기저 조건은 n=1 일때 1을 반환)의 시간 복잡도를 나타내보면, t(n) = n으로 단순화될 수 있다. 그 이유는 다음과 같다.
t(4) = 1 + t(3)
t(3) = 1 + t(2)
t(2) = 1 + t(1)
t(1) = 1
따라서, t(4) = 1 + 1 + 1 + 1 = 4가 된다.
즉, 팩토리얼 계산의 시간 복잡도는 O(n)이 된다. 예외적으로, 거듭제곱 계산의 시간 복잡도는 O(log n)이다.
Recursion을 피해야 하는 경우

*피보나치 수의 시간복잡도
흔히 많이 알려진 피보나치 수열을 살펴보면, 수학적으로는 F(n) = F(n-1) + F(n-2)(*n=0, n=1일때 제외)로 나타낼 수 있는데, 이를 재귀적으로 계산할 때 몇 번의 재귀 호출이 이루어지는지 확인했을 때 많은 중복이 일어나는 것을 확인할 수 있는데, 이러한 중복은 프로그래밍에서 굉장히 비효율적이라는 것을 확인할 수 있다. 시간복잡도가 O(2^n)으로 굉장히 비효율적이고, 값이 커질수록 더욱 성능이 떨어지게 되므로 이런 경우에는 재귀를 피해야 한다.
이런 경우에는 꼬리 재귀, 반복문, 스택 등의 다른 자료구조들을 활용해 더 좋은 효율을 가진 코드를 작성할 수 있도록 해야한다.
Tower of Hanoi
하노이의 탑 문제는 대표적인 고전적 재귀 알고리즘 문제이다. 기본적인 개요는 다음과 같다.
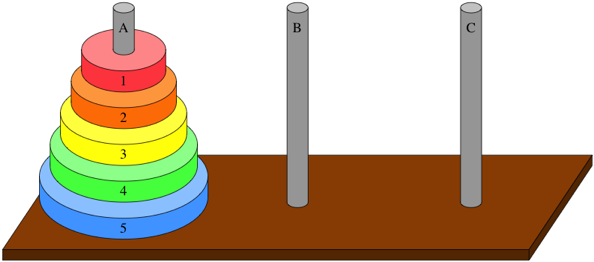
- 구성 요소:
보드: 원판을 올려놓는 수직 기둥들로 이루어진 판.
세 개의 수직 기둥: 각각 A, B, C로 불리며, 원판을 이동할 수 있는 장소입니다.
여러 개의 원판: 크기가 다른 여러 원판이 있으며, 큰 원판은 작은 원판 위에 놓일 수 없다는 규칙을 따릅니다.
- 규칙:
한 번에 한 개의 원판만 이동할 수 있습니다.
큰 원판은 작은 원판 위에 놓을 수 없습니다.
목표는 모든 원판을 출발지(A 기둥)에서 목적지(C 기둥)로 옮기는 것입니다.
base case에서 원판 하나를 바로 c기둥으로 옮기는 것을 제외하고는, n개의 원판을 옮기긴 위해서 일단 n-1개의 원판을 중간 기둥에 옮겨야 하는데, 이는 결국 재귀적으로 작은 문제로 쪼개지는 것이다.
깊이 우선 탐색(DFS)
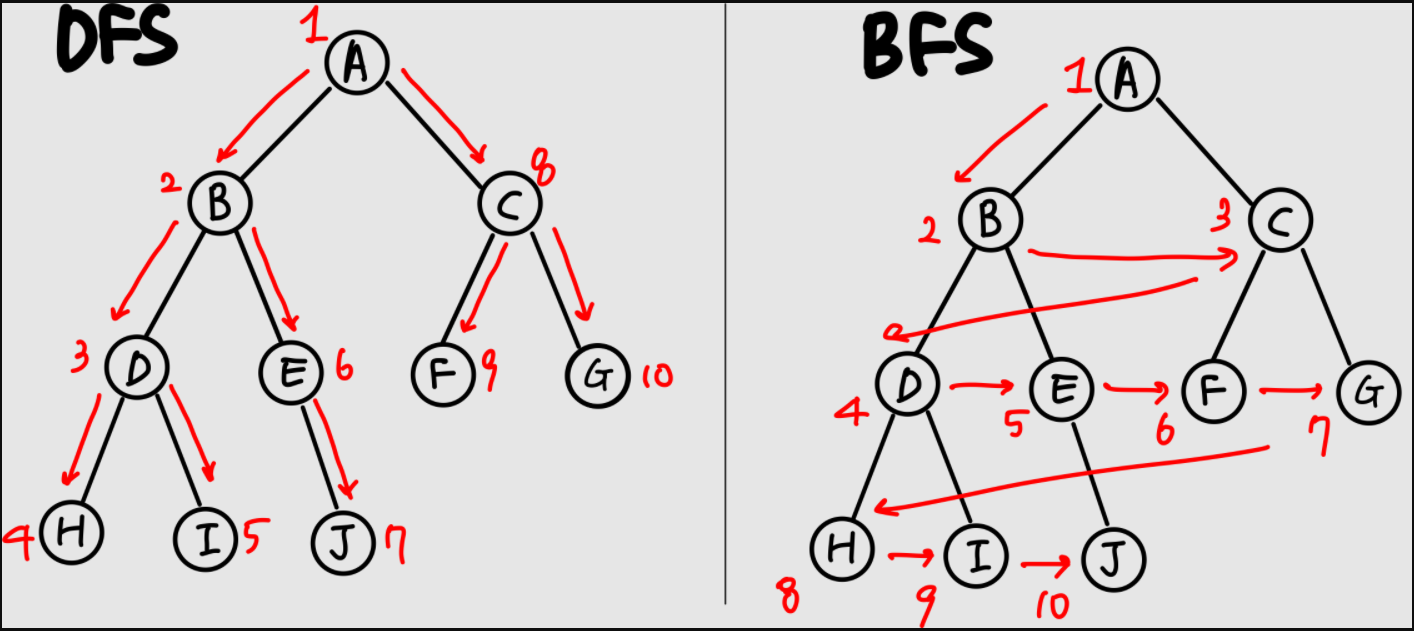
DFS(Depth-First Search), 깊이 우선 탐색은 방향을 정해 한쪽 방향의 노드들을 다 탐색하고 다른 쪽으로 넘어가는, 재귀를 상징하는 대표적인 예시이다. 기본적인 DFS의 알고리즘은, 방문한 노드는 방문했다고 표시하고, 방문하지 않은 노드중 한 노드를 임의로 택하여 다시 DFS를 수행한다. 즉, 다른 말로 풀어내면 시작 노드가 방문되었다고 표시하는 노드를 제외하고, 그 안에서 다시 자신과 성격은 똑같지만 크기만 작은 다른 하나의 문제를 만나게 되는 것이다.
