1. Web
Web 1.0 ~ 3.0
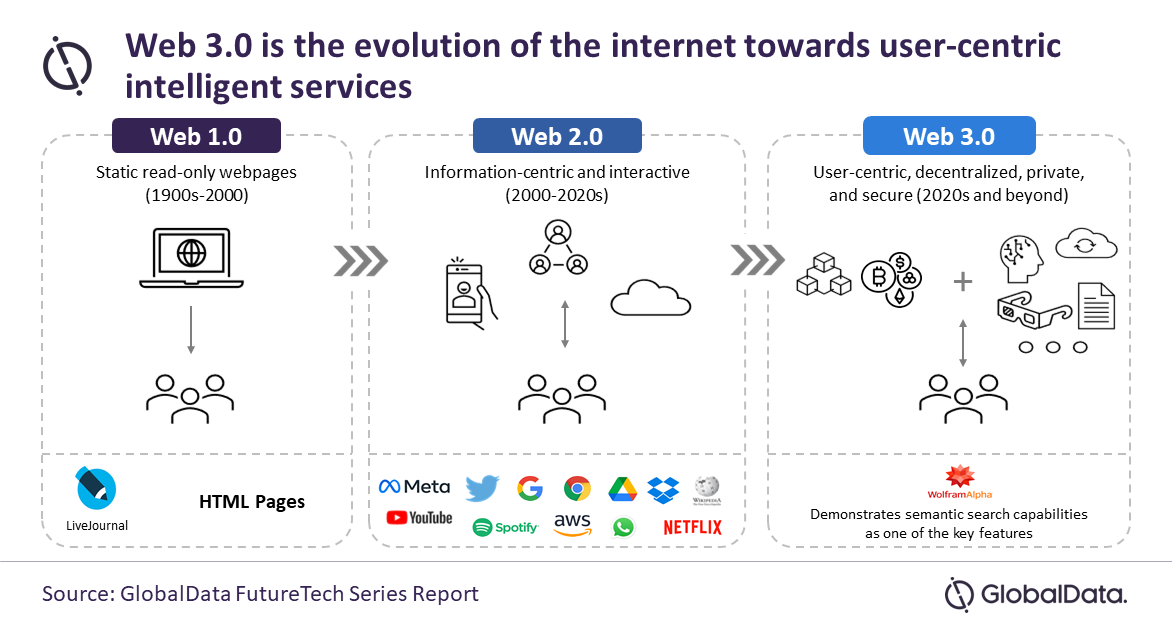
Web 1.0은 1990년대 초반, 정적인 정보 게시판이 전부였다. '정보 제공'에만 초점이 맞춰져 있어서 읽기 전용이었고, 사용자가 직접 내용을 추가하거나 수정하는 건 불가능했다. 단방향 소통이다.
Web 2.0은 2000년대 초반부터 현재까지다. 사용자가 직접 콘텐츠를 생산하고 공유하는 형태로 발전했다. 블로그, 싸이월드, 페이스북, 인스타그램, 유튜브 같은 플랫폼들이 이 시기에 등장했다. 양방향 소통이 시작된 시기다.
Web 3.0은 아직 완전히 도래하지 않은 분산형 웹, 지능형 웹이다. 개인화와 지능화에 초점을 맞추고 있으며 핵심 원칙은 세 가지다.
- 탈중앙화: 데이터를 중앙 서버가 아닌 다수의 컴퓨터에 분산 저장한다. 개인 데이터 주권 확보와 해킹 리스크 감소가 목적이다.
- 개인화: AI·머신러닝으로 사용자 맞춤형 경험을 제공한다.
- 새 기술: 블록체인 기반 NFT, 스마트 계약 등 디지털 자산 소유권 증명이 가능해진다.
Web 3.0을 알아야 하는 이유는 두 가지다.
첫째, 개인 데이터 관리가 AI 모델의 핵심 화두로 떠오르고 있다. 데이터 주권을 개인에게 돌려주고, 로컬에서 직접 사용하거나 모바일 디바이스에서 돌아가도록 경량화하는 방향이다.
둘째, 웹으로 금융, 자산, 개인정보까지 처리하게 되면서 보안이 더욱 중요해지고 있다.
Client-Server 구조
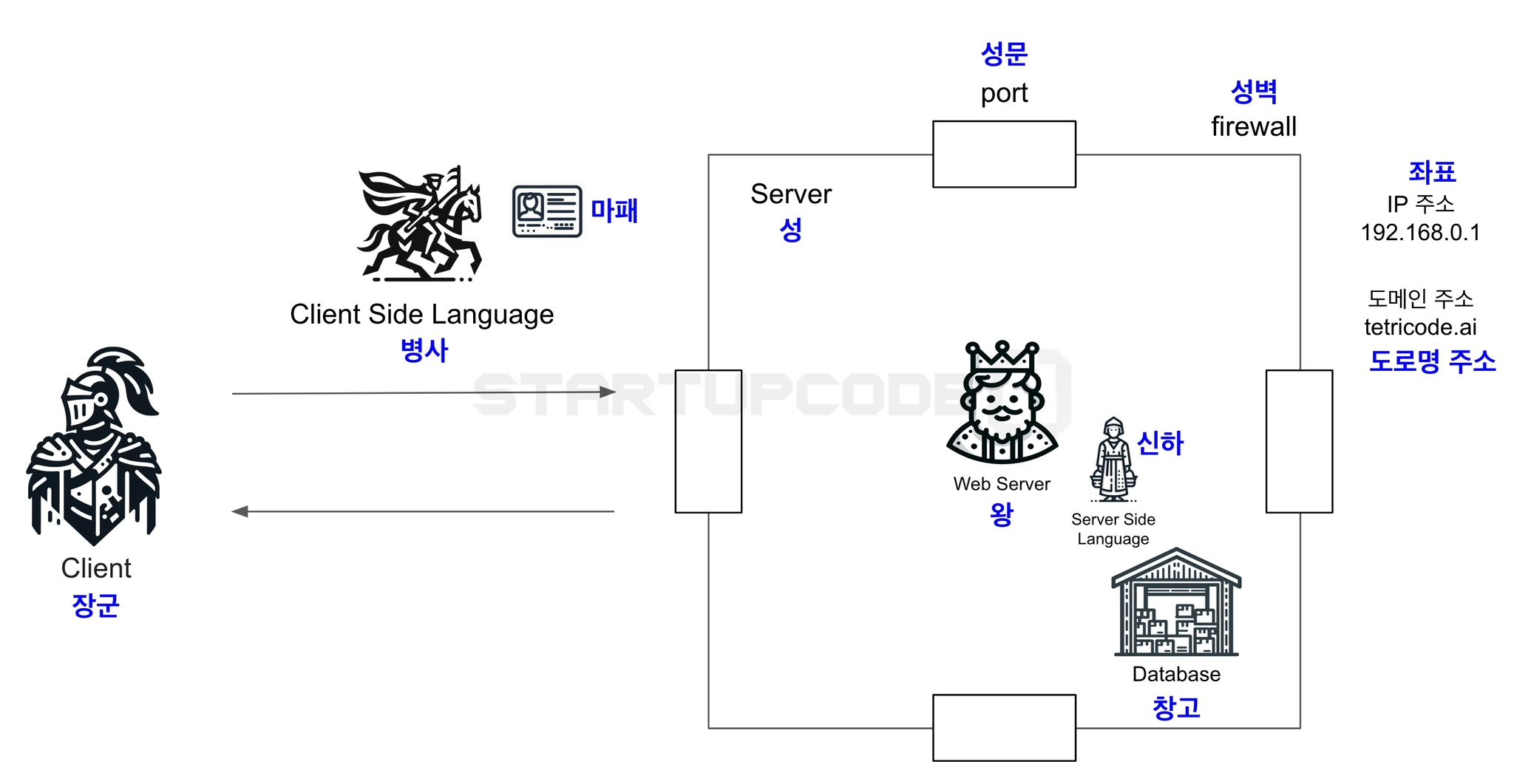
클라이언트-서버 구조를 이해하기 위해 왕과 장군 비유를 활용했다.
- 장군 → Client: 요청하는 주체
- 왕 → Web Server: 요청을 받고 응답하는 주체
- 병사 → Client Side Language: 요청을 전달하는 역할
- 성 → Server: 서버 컴퓨터 자체
- 좌표 → IP 주소: 서버의 실제 위치값
- 도로명주소 → Domain: IP를 사람이 읽기 쉽게 변환한 주소
- 성벽 → Firewall: 외부 공격 차단
- 성문 → Port: 서버 접근 통로 (0~65535번)
- 약속한 규칙 → Protocol: 통신 규약 (대표: HTTP)
- 마패 → 인증(Authentication): 신원 확인
- 접근 권한 → 인가(Authorization): 권한 확인
- 요청서 → HTTP Message: 실제 주고받는 메시지
- 신하 → Server Side Language: 서버 내부에서 DB 조회·처리
- 창고 → Database: 데이터를 체계적으로 저장·관리하는 곳
클라이언트는 request 하는 주체로, 서비스를 요청하는 단말기 또는 SW다. user agent라고도 불린다. 핵심 역할은 요청의 시작점이 되는 것, HTML을 사용자가 보기 편한 UI로 바꿔주는 것(브라우저), 그리고 컴퓨팅 자원을 사용하는 것이다. 실제 기술로는 크롬, 사파리, 카카오톡, 인스타그램, CLI, Postman 등이 있다.
Client Side Language는 HTML, CSS, JavaScript다. JavaScript는 클라이언트와 서버 양쪽 모두에서 사용 가능한 유일한 언어다.
서버는 '제공'의 주체다. 네트워크를 통해 클라이언트에게 서비스나 자원을 제공하는 시스템 또는 프로그램이다. 언제 요청이 올지 모르기 때문에 24시간 포트를 열어두고 대기한다. 스스로 통신을 시작하지 않고 요청이 오면 비즈니스 로직을 수행하고 결과를 반환한다.
Server Side Language로는 Java, PHP, JavaScript(실시간 데이터 처리), Python이 있다. 실제 기술로는 Web Server(Apache 등), WAS(Tomcat, Jetty, Node.js 등), DB Server(MySQL, Postgres 등)가 있다.
이 구조가 생긴 역사적 배경도 정리했다. 1970~80년대에는 메인 프레임이라는 거대한 중앙 컴퓨터 하나가 모든 연산을 처리했고, 더미 터미널은 내부 동작이 없었다. 중앙 컴퓨터가 너무 비싸고 병목현상이 심각했다. 1980년대 후반 개인용 컴퓨터가 보급되면서 중앙 컴퓨터의 일부를 개인 컴퓨터에 위임하게 됐고, 그 결과 client-server 구조가 탄생했다. 비용 절감, 사용자 경험 개선, 확장 용이성이라는 세 가지 이점을 얻게 됐다.
- 인증(Authentication): "넌 누구냐?" → 로그인 → 먼저 확인
- 인가(Authorization): "넌 여기 들어와도 되냐?" → 관리자 페이지 접근 권한 → 인증 이후 확인
2. HTTP
HTTP는 HyperText Transfer Protocol의 약자로, 글을 뛰어넘는 글을 전송하는 규약이다.
HyperText는 이미지, 링크, 단락, 목록 등을 포함하는 구조화된 텍스트다. 사람마다 이걸 표현하는 방식이 달랐기 때문에 전송 규약을 통일할 필요가 생겼고, 그 약속이 HTTP다. HTML, CSS, JS 문서들과 PNG, JPEG 같은 파일들을 전송하기 위한 통신 규약이다. OS나 브라우저에 관계없이 동작하는 네트워크 레벨의 약속이다.
2-1. HTTP Message
HTTP Message는 클라이언트와 서버 간에 데이터를 주고받는 통신의 기본 단위다. client-server가 주고받는 '편지'라고 생각하면 된다.
구조는 네 부분으로 나뉜다.
┌─────────────────────────┐
│ Start Line │ ← 요청/응답 상태 (첫 번째 줄)
├─────────────────────────┤
│ HTTP Headers │ ← 메시지 부가 정보
├─────────────────────────┤
│ Empty Line │ ← 헤더 끝 / 본문 시작 구분자
├─────────────────────────┤
│ Body │ ← 실제 데이터 (HTML, JSON 등)
└─────────────────────────┘- Start Line: 메서드(GET, POST 등) + 경로 + HTTP 버전. HTTP Method는 여기에 들어간다.
- Headers: 브라우저 버전, 데이터 총량·종류 같은 부가 정보(Metadata)
- Empty Line: CRLF. 헤더와 본문을 구분하는 역할
- Body(Payload): 로그인 시 ID·PW, 응답 시 페이지 HTML 등 실제 전송 데이터
2-2. HTTP Method
서버에게 어떤 작업을 원하는지 명확하게 지시하는 명령 규칙이다. Start Line에 URL과 함께 명시된다.
메서드를 나누는 이유는 두 가지다.
첫째, 트래픽이 많아지면서 모든 요청을 열어보지 않고도 빠르게 처리해야 했다. 캐싱을 적용할 때도 Method를 기준으로 판단한다.
둘째, 보안 문제다. Method만 보고 사용자의 권한에 없는 요청을 바로 차단할 수 있다. 요청을 뜯어보지 않고도 분류하고 안전하게 빠르게 처리하기 위해 나눈 것이다.
다섯 가지 Method와 데이터 전달 위치는 다음과 같다.
- GET: 데이터 조회 / URL (Query String)
- POST: 데이터 생성 / Body
- PUT: 데이터 전체 수정 / Body
- PATCH: 데이터 일부 수정 / Body
- DELETE: 데이터 삭제 / URL (식별자)
PUT과 PATCH의 구분이 실무에서는 회사마다 팀마다 규약이 다를 수 있다.
데이터 전달 방식 차이를 예시로 정리하면 이렇다.
GET /weather?city=seoul ← Query String
DELETE /users/123 ← 식별자
POST /users
Body: { "name": "kim", "age": 20 }2-3. HTTP Status Code

서버가 클라이언트 요청의 처리 결과를 3자리 숫자로 명확하게 전달하는 코드다. 응답 메시지의 Start Line에 포함된다.
- 1xx: 정보 메시지 (Informational)
- 2xx: 성공 (Successful)
- 3xx: 리다이렉션 (Redirection)
- 4xx: 클라이언트 오류 (Client Error)
- 5xx: 서버 오류 (Server Error)
4xx는 client의 잘못, 5xx는 서버의 잘못이다. 5xx는 내부 로직이 드러날 수 있기 때문에 이유를 자세하게 클라이언트에게 전달하지 않는다. 정보통신법에 따라 제정되기도 한다.
401은 인증 실패, 403은 인가 실패다.
2-4. HTTP URL (Uniform Resource Locator)
리소스의 위치와 종류를 나타내는 주소다. Resource는 웹에서 제공하는 모든 것을 의미한다.
https://www.example.com:443/users/1?city=seoul&page=2
│ │ │ │ │
스키마 도메인 포트 리소스경로 매개변수- 스키마: 필수. 사용할 프로토콜 지정 (
http,https) - 도메인: 필수. 요청할 서버 주소 (
www.example.com) - 포트: 선택. 서버 접근 통로 번호 (HTTP 기본 포트 80, HTTPS 기본 포트 443 → 생략 가능)
- 리소스 경로: 선택. 서버 내 리소스 위치 (
/users/1) - 매개변수: 선택.
?로 시작,&로 구분 (?city=seoul&page=2)
QueryString & Path Variable
- QueryString: 클라이언트가 웹페이지에 대한 추가 정보를 서버에 전달하기 위해 URL 끝에 붙이는 문자열. key=value 형태.
- Path Variable: URL 경로 자체에 변수 값을 포함시켜 특정 자원을 식별하는 변수.
사용 기준은 명확하다. QueryString은 추가 질의가 필요할 때, Path Variable은 리소스 그 자체를 특정해야 할 때 쓴다.
목록 조회 (필터, 정렬, 페이징) → Query String
GET /posts?offset=0&limit=10
특정 하나 조회 → Path Variable
GET /posts/1JSON
언어에 관계없이 데이터를 주고받기 위한 표준화된 경량 데이터 형식이다. JavaScript 기반이지만 모든 언어에서 범용으로 사용된다.
{
"이름": "웨인",
"나이": 25,
"취미": ["독서", "등산"]
}{}: 객체[]: 배열"key": value: 프로퍼티 (키-값 쌍)- 쌍 구분:
,/ 키-값 구분::
핵심 메서드 두 가지다.
// 받을 때 (문자열 → 객체)
const obj = JSON.parse('{"name":"웨인"}');
console.log(obj.name); // 웨인
// 보낼 때 (객체 → 문자열)
const str = JSON.stringify({ name: "웨인" });
console.log(str); // {"name":"웨인"}다른 데이터 형식과 비교하면 다음과 같다.
- JSON: 키-값 쌍 구조. 가독성·호환성 높지만 대용량에는 비효율적.
- XML: 태그 계층 구조. 복잡한 데이터 표현 가능하지만 문서가 길고 복잡.
- CSV: 쉼표 구분. 대량 데이터·엑셀 호환에 강하지만 계층 구조 표현 불가.
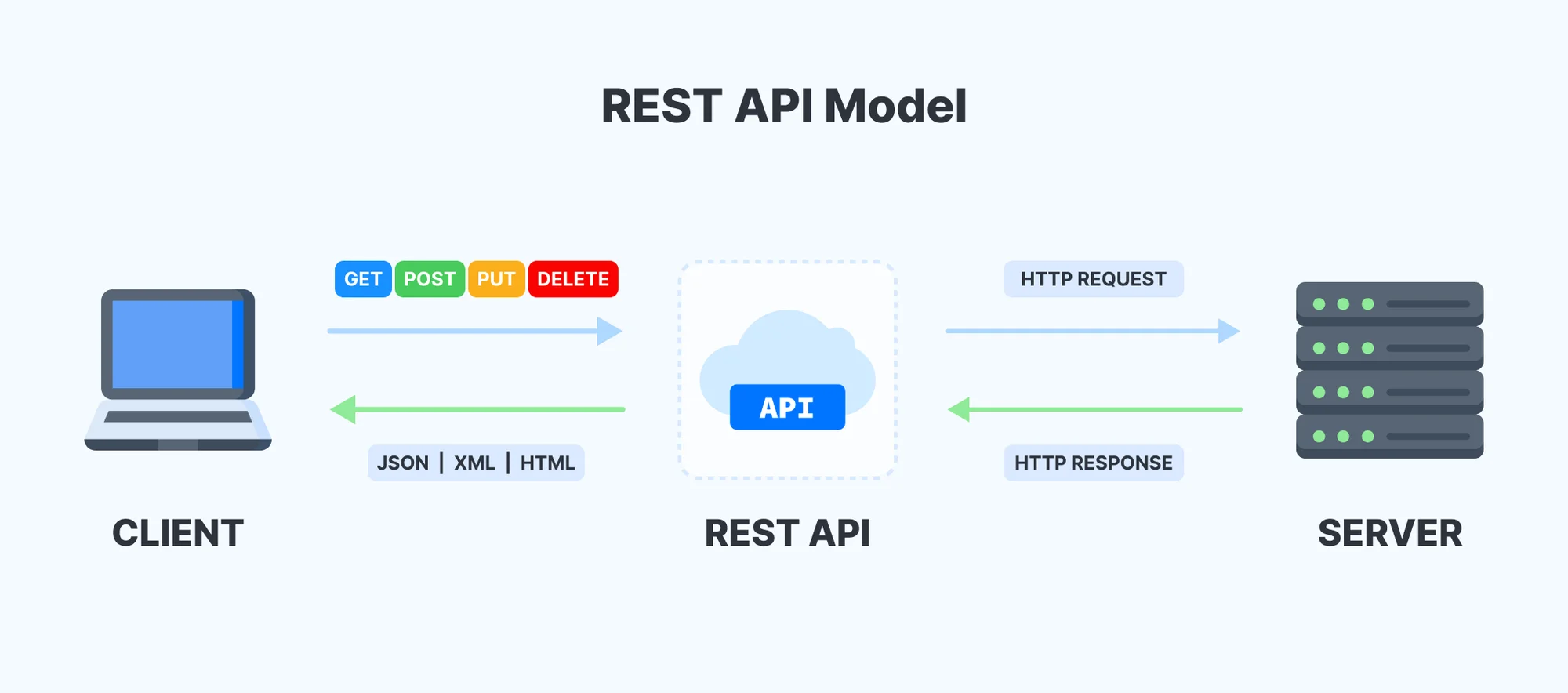
3. REST API
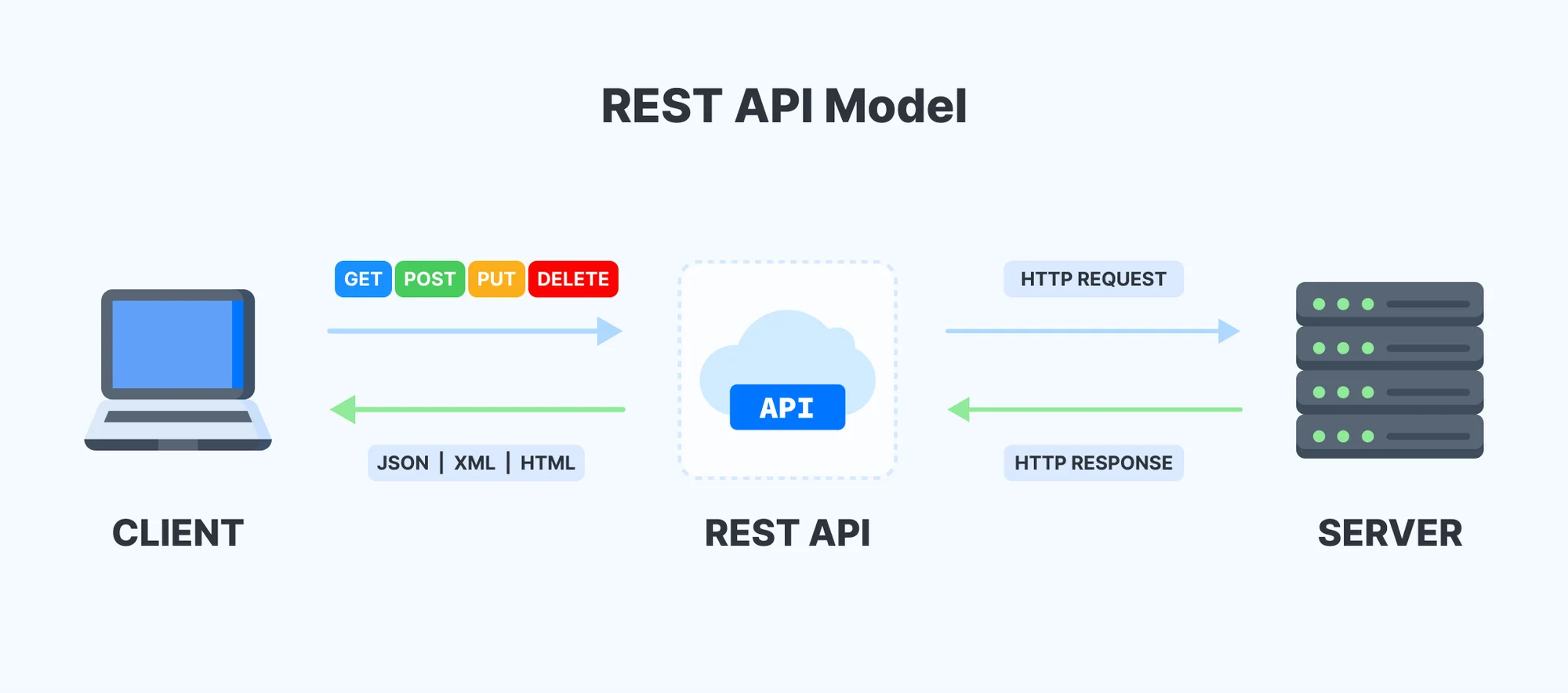
REST 아키텍처 스타일을 따르는 응용 프로그램 인터페이스다. 클라이언트-서버 간 일관된 통신 규칙이라고 이해하면 된다.
중요시하는 HTTP 요소 세 가지
- 리소스(받고 싶은 자원)
- 메서드(행위)
- 메시지(구체적인 요청)
핵심 규칙은 두 가지다.
1. 자원에 대한 행위는 HTTP Method로 표현한다.
2. URI는 자원을 표현한다. (URI는 URL의 상위 개념)
행위는 무조건 Method로 표현되기 때문에, 리소스명에는 반드시 명사만 들어간다.
예시를 보면 명확하다. "Charlie 회원의 이름을 변경해주세요" → PATCH /users/charlie. 로그인의 경우 인증정보를 생성하는 개념이므로 POST /auth가 RESTful한 표현이다.
6가지 원칙
- Uniform Interface: 모든 API가 일관된 방식으로 통신
- Client-Server: 클라이언트·서버 독립적으로 분리
- Stateless: 서버는 클라이언트 상태를 저장하지 않음
- Cacheable: 응답은 캐싱 가능해야 함
- Layered System: 클라이언트는 중계 서버 존재를 몰라도 됨
- Self-Descriptiveness: 메시지 자체가 처리 방법을 설명해야 함
설계 규칙 7가지
- URI는 명사:
/users(X:/getUsers) - 행위는 HTTP 메서드로:
DELETE /users/1(X:POST /users/delete/1) - 계층은
/로:/users/1/posts(X:/users-posts-1) - 소문자만:
/users(X:/Users) - 하이픈(
-) 사용:/user-posts(X:/user_posts) - 확장자 금지:
/users/1/profile(X:/users/1/profile.png) - 마지막
/금지:/users(X:/users/)
실무 개념으로 soft delete도 알아뒀다. 회원 삭제 API를 DELETE /users/{user_id} 대신 PATCH /users/{user_id}로 처리하는 경우가 있다. 30일 이내 계정 복구 약관이 있을 때처럼, 실제로 데이터를 지우는 게 아니라 삭제 상태로 변경만 하는 경우다.
REST API
├── URL 구조 (URL)
├── Path Variable (/users/1)
├── Query String (/users?page=1)
├── HTTP Method (GET, POST ...)
├── HTTP Message (요청/응답 형식)
└── JSON (본문 데이터 형식)4. Spring

Java 애플리케이션에서 객체 생성과 의존성 관리를 자동화해 구조를 단순하고 유연하게 만드는 프레임워크다. 객체 지향 언어의 강력한 특징을 살려 좋은 객체 지향 애플리케이션을 개발할 수 있도록 도와준다.
Spring 등장 배경
Web 2.0 시대가 되면서 동적으로 HTML을 만들어내는 기술이 필요해졌다. CGI, PHP, ASP가 등장했고, 자바에서도 JSP가 나왔다. 하지만 JSP는 Java + HTML을 하나의 코드에서 처리하다 보니 비즈니스 로직이 혼재되고 코드 복잡도가 폭증했다. 재사용성 부족, 테스트 어려움 문제도 있었다.
대규모 기업 서비스를 위해 EJB가 등장했지만 높은 개발 난이도, 복잡한 배포 설정, 테스트 어려움 문제는 여전했다. 결국 둘 다 자바 기반이지만 자바의 특징을 제대로 살리지 못했다. 객체 관리가 어렵고, 설정·배포가 복잡하고, 객체들이 서로 강하게 결합돼 테스트와 확장이 힘들었다.
개발자가 설정이 아닌 비즈니스 로직 개발에 집중해야 한다는 문제의식에서 Spring이 등장했다.
Spring의 5가지 특징
1. IoC (Inversion of Control): 제어의 역전
객체의 생성과 의존성 관리를 개발자가 아니라 외부 컨테이너(Spring)가 제어하도록 만드는 설계 원칙이다.
개발자는 어떤 객체가 필요한지 선언(@Component)만 하고, 스프링 컨테이너가 필요한 객체를 주입하고 관계를 관리한다. Bean은 컨테이너의 통제하에 생성되고 관리되는 객체다.
IoC 이전에는 객체 생성·의존성 연결·생명주기 관리를 모두 개발자가 했고, Service가 생성과 비즈니스 로직을 함께 담당했다. IoC 이후에는 이 모든 것을 Spring 컨테이너가 맡고, Service는 비즈니스 로직에만 집중한다. IoC는 SOLID 중 DIP(의존 역전 원칙)를 실현하는 구체적인 방법이다.
2. DI (Dependency Injection): 의존성 주입
객체가 직접 의존 객체를 생성하지 않고, 외부(Spring 컨테이너)에서 필요한 의존성을 주입받도록 하는 설계 방식이다.
@Autowired를 통해 사용한다.
주입 방식은 세 가지다.
- 생성자 주입: 객체 생성 시. 기본·권장 방식
- 세터 주입: 객체 생성 후. 선택적 의존성·순환참조 시에만
- 메서드 주입: 특정 메서드 호출 시. 거의 사용 안 함
IoC는 제어권을 컨테이너로 넘기는 설계 원칙이고, DI는 IoC를 실현하는 구체적인 방법이다. IoC가 상위 개념이고 DI는 그 구현 수단이다.
3. AOP (Aspect-Oriented Programming): 관점 지향 프로그래밍
공통 관심사와 핵심 관심사를 분리하여 코드 수정 없이 공통 기능을 일관되게 적용하는 프로그래밍 방식이다.
@Aspect로 AOP를 등록하고,@Around로 범위를 지정한다.
OOP는 무엇을 하는가(역할·책임)를 기준으로 클래스·계층을 분리하는 기반 구조고, AOP는 어디에 공통 기능을 적용하는가를 기준으로 횡단 관심사를 분리한다. AOP는 OOP를 대체하는 게 아니라 보완한다.
4. POJO (Plain Old Java Object)
프레임워크나 라이브러리 의존성이 없는 순수한 자바 객체다. JSP나 EJB처럼 프레임워크에 종속되면 객체지향적으로 개발할 수 없기 때문에, 순수 자바로만 스프링 프레임워크를 구성해 테스트 용이성·유연성·간결함을 보장한다.
스프링은 자바를 자바답게 쓰기 위한 프레임워크다.
Spring Container & Bean
Bean은 스프링 컨테이너가 생성하고 관리하는 객체다. 컨테이너는 빈 스캐닝·등록, 빈 생성·DI, 빈 라이프사이클 관리, 환경 설정 관리, 이벤트 발행을 담당한다.
빈 등록 방법은 두 가지다.
첫 번째는 Component Scanning이다.
@Controller: 웹 요청 처리, View 반환@RestController: 웹 요청 처리, JSON 반환@Service: 비즈니스 로직@Repository: 데이터 접근@Component: 계층 구분 없는 일반 Bean
두 번째는 @Bean을 이용한 설정 클래스 기반 등록이다. 외부 라이브러리처럼 어노테이션을 직접 붙일 수 없는 객체를 등록할 때 사용한다.
IoC·DI·Bean의 관계를 한 줄로 정리하면 다음과 같다.
- IoC: 구조적 원칙. 제어권을 컨테이너로 이전
- DI: 구체적 기법. IoC를 실현하는 방법
- Bean: 관리 단위. DI의 대상이 되는 객체
Spring Data Access/Integration
서버를 DB와 연결하는 영역이다. 다음 시간에 이어서 다룰 예정이다.
