
1년차 주니어 프론트엔드 개발자입니다. 회사에 입사 한 후 정말 많은 것들을 배우고 경험했습니다. 그 중에서도 제가 가장 관심을 가지고 공부한게 무엇이냐 물어본다면, 단연코 React Query입니다.
이번 글에서는 왜 제가 React Query에 열광했는 지, 어떻게 사용했는 지에 대한 경험을 공유하고자 합니다.
React Query란?
본격적인 이야기에 앞서 간략하게 React Query가 무엇인지 간략히 소개해 드리겠습니다.
React Query는 애플리케이션에서 서버 상태를 불러오고, 캐싱하며, 지속적으로 동기화하고 업데이트 하는 작업을 도와주는 라이브러리입니다. React Query를 사용하면 서버 상태와 클라이언트 상태를 분리하여 관리할 수 있어 React 애플리케이션의 성능,확장성,유지 보수성을 향상시킬 수 있습니다. 더불어, 서버 상태를 관리하며 마주하는 다양한 문제들을 효과적으로 해결할 수 있습니다.
React Query는 다양한 기능들이 존재하는 데, 그 중 제가 생각하는 장점과 주요 기능은 아래와 같습니다.
React Query의 장점 및 주요 기능
1) 캐싱
2) 동일한 데이터에 대한 중복 호출 제거
3) Out of date를 파악하고, 백그라운드에서 업데이트 가능
4) 모든 쿼리의 Loading,Error 상태 제공
5) Pagination,Lazy loading, Prefetching 등 데이터 성능 최적화 기능 제공
6) 서버 상태 메모리 관리 및 garbage collect 지원
React Query에 대해 더 자세히 알고 싶으신가요? 자세한 내용은 공식 문서와 공식 블로그를 참고하세요!
(해당 포스트는 React Query 사용법에 대해 다루지 않습니다.)
React Query를 도입한 이유
수습 기간이 지나고, 회사에서 프론트엔드 개발자로 처음 정식으로 맡게 된 프로젝트는 웹 소켓 서버를 사용하고, 로봇에 포함되는 웹 애플리케이션을 개발하는 프로젝트였습니다.
웹 소켓 서버를 통한 실시간 데이터 통신을 사용해야하는 프로젝트 특성상, 중복된 데이터 요청, 불필요한 네트워크 부하, 데이터 불일치 등 다양한 문제가 발생할 가능성이 높아 이를 효율적으로 관리하고 처리할 방법이 필요했습니다. 그리고 로봇 데이터의 정제와 복잡한 알고리즘으로 인해 RESTful API 응답 시간이 평균 3초 이상 길게는 응답 시간이 소요되는 경우도 많아 클라이언트 측에서 optimistic update가 필요했습니다.
그래서 안정적이고 효율적인 서버 통신과 간편하고 일관된 Optimitic update 처리를 위해 React Query 도입을 결정했습니다. 여러 시행착오를 겪으며 해당 프로젝트에 React Query를 성공적으로 적용한 이후, 사내 코어 프로젝트와 다른 프로젝트들에도 React Query를 점진적으로 적용하였습니다.
이번 시리즈에서는 여러 개의 상용 프로젝트에 어떻게 React Query를 적용하였는 지와 사용하며 느낀 장단점에 대해 공유해보고자 합니다.
React Query 이렇게 사용했어요
사용 버전 : @tanstack/react-query : v4.35.3
들어가기 앞서..
아래의 내용이 React Query를 사용하는 Best Practice가 아닙니다. 많은 시행착오를 겪으며 나름대로 정립한 React Query 사용법을 공유하는 글 입니다. 건설적인 태클과 지적, 제안은 언제나 환영입니다!
1. Query Key 관리하기
React Query에서 QueryKey는 데이터 캐싱과 관련된 각각의 API 호출을 식별하는 유일한 식별자입니다. React Query에서 내부적으로 데이터를 올바르게 캐싱하고, dependency가 변경될 때 자동으로 refetch를 수행하기 위해 QueryKey를 잘 관리하는 것은 매우 중요합니다. QueryKey를 효율적으로 관리하기 위해 저는 다음과 같은 방식을 사용하였습니다.
① QueryKey 추상화
가장 기본적으로 QueryKey를 문자열로 직접 사용하지 않고, QueryKey 함수를 사용해 추상화하여 사용하였습니다.
// 🚫 문자열을 직접 QueryKey로 사용하는 경우 <= 권장하지 않음!
const { data, isLoading } = useQuery(['test_query_key'], queryFn);문자열을 직접 사용하지 않고 아래와 같이 QueryKey를 추상화하여 사용하는 이유는 휴먼 에러를 방지하고, 가능한 중복 작업을 줄이기 위해서 입니다.
동일한 쿼리를 호출할 때, 동일한 QueryKey를 사용하여 캐싱된 데이터를 찾아 가져옵니다. 이 때, 실수로 QueryKey에 오타를 내게 된다면 아무런 에러는 발생하지 않지만, QueryKey가 바뀜에 따라 불필요한 데이터 호출이 발생하게 됩니다.
이러한 휴먼 에러를 방지하고, 동일한 QueryKey를 반복적으로 작성하는 귀찮은 일을 피하기 위해 아래와 같은 Query Key Factory를 사용했습니다.
// ✅ QueryKey 추상화
// queryKeys.ts - Query Key Factory
export const queryKeys = {
testKey : () => ['test_query_key'],
}
// 사용하기
const { data, isLoading } = useQuery(queryKeys.testKey(), queryFn);해당 내용에 대한 자세한 내용이 궁금하다면 공식 블로그의 Effective React Query Keys 를 확인해보세요!
② QueryKey 네이밍 컨벤션
QueryKey의 이름 짓기에 최대한 시간을 덜 사용하기 위해 Swagger를 기준으로 네이밍 컨벤션을 정의했습니다.
먼저 Swagger를 살펴보면 크게 API를 분리하는 태그 doner-controller가 있고, 그 하위에 각각의 RESTful API가 존재합니다.
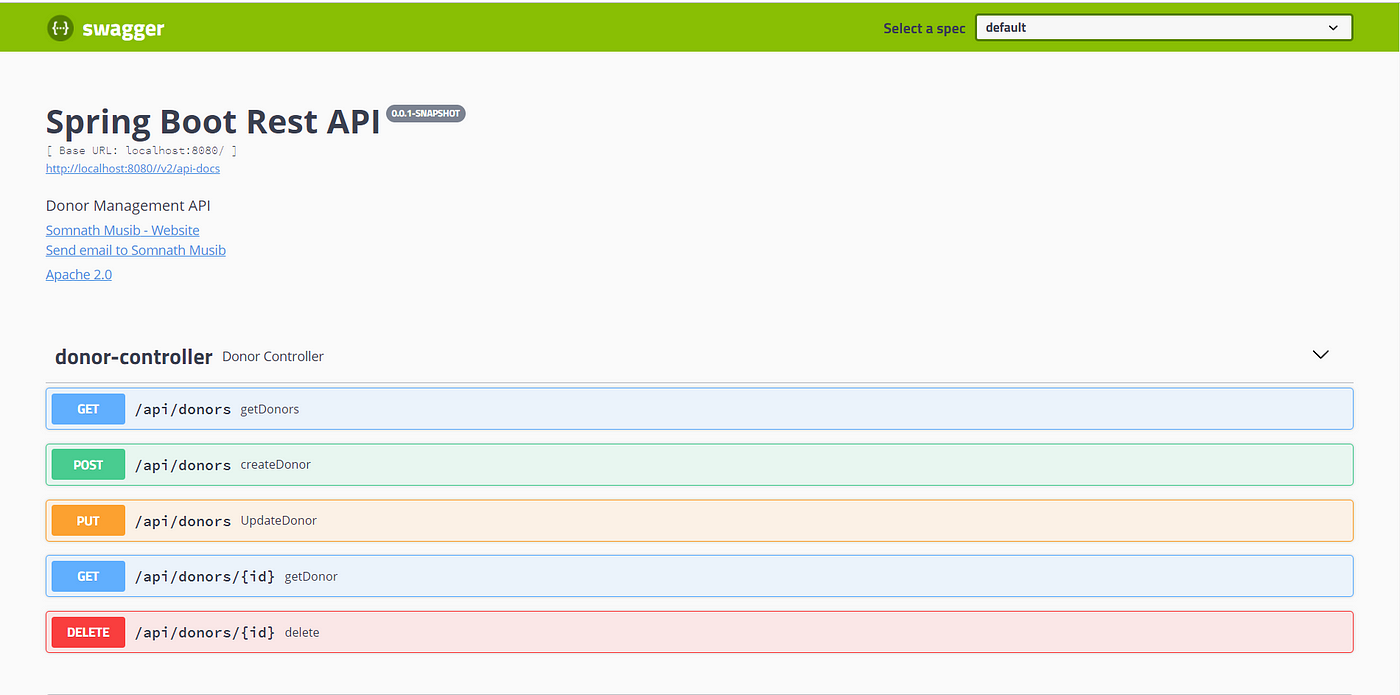
일반적으로 GET API를 호출하는 경우에만 QueryKey가 필요하기 때문에 아래의 두 API에 QueryKey를 정의해보겠습니다.
GET /api/donors - 기부자들의 목록 조회 API
GET /api/donors/{id} - 기부자 상세정보 조회 API각각의 API를 아래와 같이 구조화하고, 이를 사용하여 QueryKey를 구성하였습니다.
| API | Tag | Entity | Unique ID |
|---|---|---|---|
| 기부자 목록 | doner-controller | donors | X |
| 기부자 상세 | doner-controller | donor | {id} |
Swagger의 Tag를 기준으로 크게 QueryKey를 먼저 분류하고, Tag 아래 있는 각각의 API를 구조화하여 QueryKey를 아래와 같이 정의했습니다.
export const queryKeys = {
donerController : {
donors: () => ['donors'],
donor: ({ id }) => ['donor', { id }],
}
}정의한 QueryKey는 아래와 같이 사용할 수 있습니다.
// 기부자 목록을 조회하는 경우
const 기부자_목록 = useQuery(queryKeys.donerController.donors(), queryFn1);
// 기부자의 상세 정보를 조회하는 경우
const [id, setId] = useState("");
const 기부자_상세정보 = useQuery(queryKeys.donerController.donor({ id }), queryFn2);이렇게 QueryKey를 정의하면,QueryKey의 이름을 무엇으로 할 지 고민하는 고통의 시간이 단축되고, QueryKey를 보면 직관적으로 해당 쿼리가 어떤 API를 호출하는 지 알 수 있어 개발 생산성 향상에 도움이 됩니다.
③ 단점 & 개선할 점
저는 queryKeys.ts라는 파일에 queryKeys 객체를 만들어 애플리케이션 내 모든 QueryKey를 관리했습니다. 이렇게 QueryKey를 관리하며 대부분의 경우 편리했지만, 몇 가지 단점과 개선점도 존재했습니다.
우선, 프로젝트의 규모가 커질 수록 queryKeys 객체가 점점 거대해져 가독성이 떨어지고 관리가 어려워지는 문제를 겪었습니다. 평균적으로 queryKeys.ts 파일이 300줄이 넘어가니 새로운 QueryKey를 어디 위치에 넣을 지 찾기 어려웠습니다.
그리고 page, limit, sortDirection, sort 등 중복해서 사용되는 parameter들이 많아 이를 매번 작성하는 일이 번거로웠습니다.
먼저 반복되는 코드를 줄이기 위해 아래와 같은 방법으로 일부 리팩토링을 진행했습니다.
QueryKey에서 자주 사용되는 페이지네이션과 관련한 파라미터들을 정리한 defaultQueryKeys라는 객체를 새로 만들었습니다.
export const defaultQueryKeys = {
tableDefaultParams: {
default: ({
page = 0,
limit = 10,
sortDirection = "DESC",
sort = "createDate",
keyword = "",
...otherProps
}) => [
{
page,
limit,
sortDirection,
sort,
keyword,
...otherProps,
},
],
},
};그 다음 반복적으로 사용되는 파라미터를 QueryKey에 포함하고자 하는 경우, 아래와 같이 QueryKey를 작성하면 중복된 코드를 최소화해서 작성할 수 있고, 다른 파라미터들도 원하는대로 추가할 수 있습니다.
const queryKeys = {
donerController : {
donors: (props) => ['donors', ...defaultQueryKeys.tableDefaultParams.default({...props})],
},
}console.log(queryKeys.donerController.donors({test : 123}))
// 결과: ["donors",{"test": "123", "page": 0,"limit": 10,"sortDirection": "DESC","sort":"createDate","keyword": ""}]위와 같은 방식으로 중복되는 코드를 줄여도 여전히 100줄 가까이 되어 QueryKey를 효율적으로 관리할 다른 폴더 구조를 고민했습니다. 이와 관련한 내용은 추후 '폴더 구조' 섹션에서 다시 다루겠습니다.
이어지는 포스트
지금까지 React Query를 도입한 배경과 상용 프로젝트에서 어떤 방식으로 QueryKey를 관리했는 지에 대해 정리해보았습니다. 최대한 풀어 쓰려 노력하였지만, 혹시 이해가 되지 않거나 궁금한 점이 있다면 언제든 편하게 질문해주세요.
다음에는 React Query 이렇게 사용했어요 - Custom Hook 사용하기, "React Query 이렇게 사용했어요 - 폴더 구조" 편으로 돌아오겠습니다. 긴 글 읽어주셔서 감사합니다!
Reference
TKDODO - Effective REact Query Key
React Query의 Query Key 구조화 하기
이미지 참조
