XML이란?
- eXtensible Markup Language 의 줄임말이다.
- Markup 이므로 HTML과 굉장히 비슷한 모양을 가진다.
- 약속된 tag를 사용하는 HTML과 달리, 사용자가 원하는 tag를 만들어서 사용한다.
<!--test.xml-->
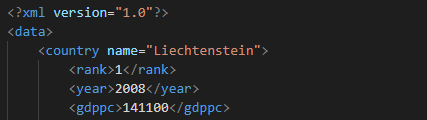
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>위와 같은 xml파일이 있다고 가정하자.
xml을 트리의 형태로 볼 수 있는데,
위의 xml파일을 예로 들면,
root는 <data> 가 되고,
<data>의 child는 <country> 가 된다.
<country>는 총 3개가 존재하므로 <data>의 child는 3개이다.
<country name = "Liechtenstein">은
<rank>, <year>, <gdppc>, <neighbor>, <neighbor> 로 총 5개의 child를 갖는다.
마찬가지로, <country name = "Singapore"> 는 4개의 child를 갖고,
<country name="Panama"> 는 5개의 child를 갖는다.
XML 파일에 담겨있는 정보를 터미널에 출력하는 코드는 아래와 같다.
아래의 코드를 담은 .py 파일과 xml파일이 같은 디렉토리에 있어야 한다.
import xml.etree.ElementTree as ET
tree = ET.parse('test.xml')
root = tree.getroot()
for x in root:
print(x.tag, x.attrib, x.text)
for y in x:
print("--",y.tag, y.attrib, y.text)출력값은 아래와 같다.
country {'name': 'Liechtenstein'}
-- rank {} 1
-- year {} 2008
-- gdppc {} 141100
-- neighbor {'name': 'Austria', 'direction': 'E'} None
-- neighbor {'name': 'Switzerland', 'direction': 'W'} None
country {'name': 'Singapore'}
-- rank {} 4
-- year {} 2011
-- gdppc {} 59900
-- neighbor {'name': 'Malaysia', 'direction': 'N'} None
country {'name': 'Panama'}
-- rank {} 68
-- year {} 2011
-- gdppc {} 13600
-- neighbor {'name': 'Costa Rica', 'direction': 'W'} None
-- neighbor {'name': 'Colombia', 'direction': 'E'} Nonexml파일에 있는 모든 정보가 잘 뽑아진 것을 볼 수 있다.
이것이 어떻게 동작하는지 알기 위해서, 함수와 반복문을 차례로 살펴보도록 하자.
import xml.etree.ElementTree as ET
tree = ET.parse('test.xml')
root = tree.getroot()
print(tree)
print(type(tree))
print(root)
print(type(root))
import inspect
print(inspect.getsource(ET.parse))
print(inspect.getsource(ET.ElementTree.getroot))tree와 root에 담겨있는 내용과 type을 출력해보고,
inspect 모듈을 이용해서 parse()와 getroot()함수가 어떤 일을 하는지 알아보자.
바로 위에 있는 코드를 실행시키면 아래와 같은 출력값이 나온다.
1. <xml.etree.ElementTree.ElementTree object at 0x0000015901B66310>
2. <class 'xml.etree.ElementTree.ElementTree'>
3. <Element 'data' at 0x0000015901BC49A0>
4. <class 'xml.etree.ElementTree.Element'>
5. def parse(source, parser=None):
"""Parse XML document into element tree.
*source* is a filename or file object containing XML data,
*parser* is an optional parser instance defaulting to XMLParser.
Return an ElementTree instance.
"""
tree = ElementTree()
tree.parse(source, parser)
return tree
6. def getroot(self):
"""Return root element of this tree."""
return self._root
위의 출력값을 보자. 번호는 임의로 붙인 것이다.
tree의 내용을 출력했더니 xml.etree.ElementTree.ElementTree object 라고 나온다.
tree의 type을 출력했더니 xml.etree.ElementTree.ElementTree 클래스라고 한다.
이것으로, tree는 어떠한 클래스 임을 알 수 있다.
root의 내용을 출력했더니 Element 'data' 라고 나온다.
root의 type을 출력했더니 xml.etree.ElementTree.Element 클래스라고 한다.
https://docs.python.org/3/library/xml.etree.elementtree.html#module-xml.etree.ElementTree
위의 문서에서 찾아보면, XML을 tree의 형태로 나타내기 위해서 ET에는 두개의 클래스가 있다고 한다.
ElementTree는 XML 전체를 tree로 표현하고, Element는 tree의 하나의 노드만을 의미한다고 한다.
tree는 XML 문서 전체를, root는 문서의 어떠한 한개의 노드만을 표현하는것을 알 수 있다.
tree와 root가 무엇을 의미하는지 알았으니, 함수에 대해 알아보자.
위의 출력값을 읽어보면, parse() 함수는 XML 문서를 tree로 분석한다고 적혀있다.
ElementTree를 리턴해준다고 한다.
이것으로 parse()가 어떤 함수인지 알게 되었다.
getroot()함수는 위에서 생성된 ElementTree의 함수이고, 자기 자신의 root 노드를 반환해준다고 적혀있다.
이것으로 parse()와 getroot()가 어떤 일을 하는지 알게 되었다.
그러면이제 for문을 관찰해보자
import xml.etree.ElementTree as ET
tree = ET.parse('test.xml')
root = tree.getroot()
for x in root:
print(x.tag, x.attrib, x.text)
for y in x:
print("--",y.tag, y.attrib, y.text)x는 root[0], root[1], root[2]...를 돌면서 root의 child들에 접근하게 될 것이다.
root[0]으로 1번째 child에 접근할 수도 있다.
0번째 child에 접근하면 x.tag로 tag를 string 자료형으로 출력,
x.attrib로 tag안의 값을 dictionary자료형으로 출력,
x.text로 태그 사이의 값을 string 자료형으로 출력한다.
자료형이 맞는지는 type()으로 확인해보는것도 좋을 것 같다.
0번째 child의 정보 출력이 끝나면, 0번째 child의 child에 대한 접근을 시도한다.
이것이 반복되면서 tree의 모든 node에 접근하고, 모든 값을 출력했다.
xml 파일에서 depth가 2로 동일했기 때문에 for문을 두번만 돌린 것이고,
depth가 3이라면 for문을 한번 더 넣으면 될 것 같다.
"--"을 앞에 붙인것은 출력값을 볼 때, 구분감을 주어서 보기 편하게 한 것이다.
모르는 라이브러리가 있을때는
https://docs.python.org 를 참고하도록 하자.
모르는 함수가 있을때는 inspect를 쓰는것도 좋은 방법중 하나일 것이라고 생각한다.
