[CS/네트워크] 웹의 통신
웹의 통신
웹에서 가장 중요한 HTTP의 기본에 대하여 알아보자.
1. HTTP란?
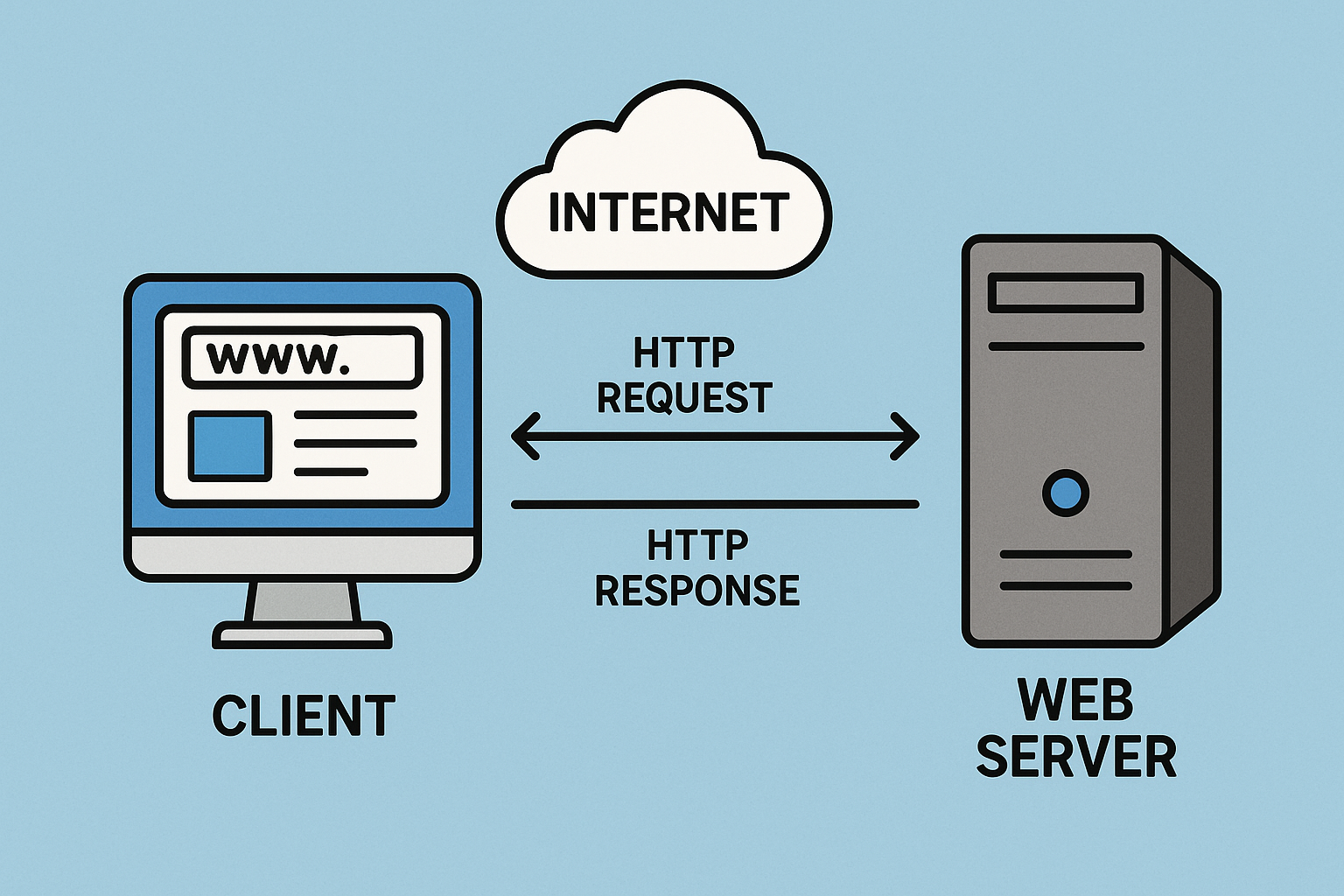
HTTP(Hypertext Transfer Protocol)는 웹에서 데이터를 주고받는 서버-클라이언트 모델의 프로토콜이다.
(이전에 TCP에 대하여 설명한 적이 있는데, TCP의 통신 프로토콜에서 발전한 것이 HTTP라고 받아들이면 된다.)
쉽게 말하면 "웹 브라우저가 서버와 통신할 때 따르는 규칙"이다.
클라이언트(브라우저)의 요청과 서버의 응답 사이에는 여러 프록시 서버가 존재한다.
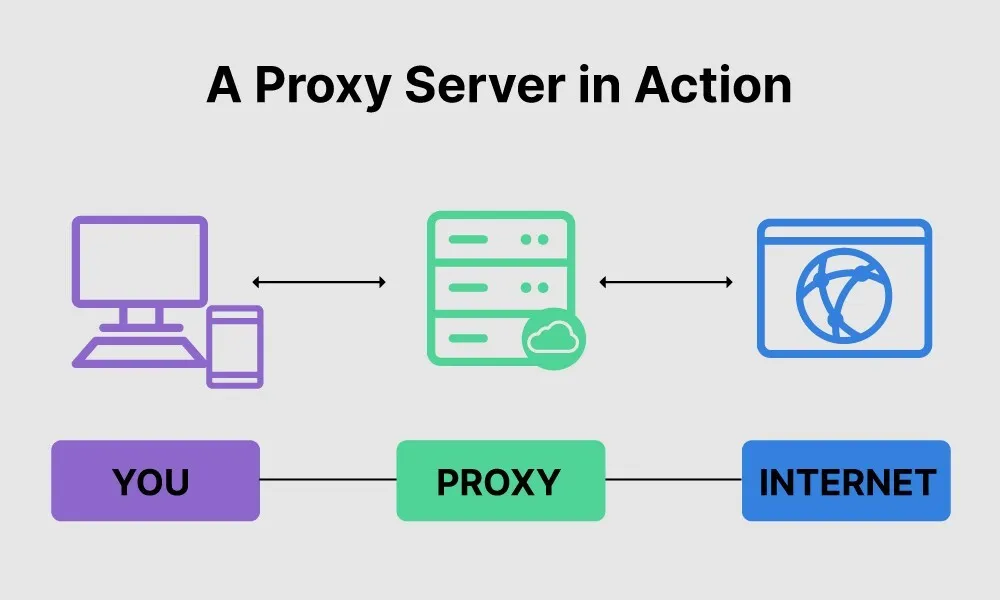
프록시 서버는 캐시를 보관하거나, 서버의 IP 주소를 숨기고, 포트가 노출되지 않도록 보안적인 역할을 한다.
예전엔 nginx가 이 부분에서 핵심 역할을 했다.
HTTP 통신은 TCP 기반으로 이뤄지며, HTML, 텍스트, 이미지, 음성, 영상, 파일 등 다양한 데이터를 주고받을 수 있다.
1-1. HTTP vs HTTPS
HTTP와 HTTPS의 차이점은 무엇일까?
그것은 바로 "보안"이다!
우리는 항상 접근할 때마다 HTTPS로 접근하고,
HTTP의 사이트에 접근할 경우, 브라우저 상에서 이에 대하여 보안 접속을 지원하지 않는다고 경고를 하는 것을 발견할 수 있다.
그 이유에 대하여 알아보자.
HTTP는 데이터를 암호화하지 않고 평문 그대로 전송한다. 그래서 제3자가 데이터를 가로채 읽을 수 있고, 대표적인 보안 취약점이 바로 CSRF 공격 같은 것이다.
CSRF(Cross-Site Request Forgery) 공격
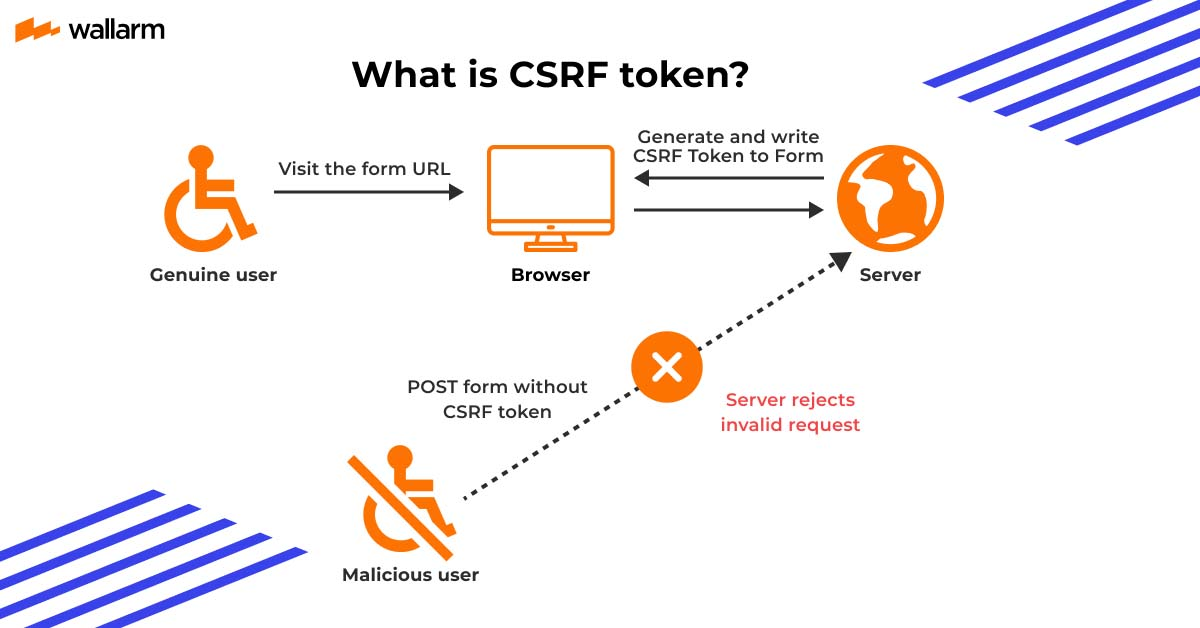
사용자가 자신의 의지와 무관하게 웹사이트의 기능을 악용하도록 만드는 공격 방식
- 악성 스크립트 삽입: 공격자는 사용자가 자주 방문하는 정상적인 웹사이트나 이메일에 악성 스크립트를 삽입
- 사용자 유도: 사용자는 공격자가 심어놓은 스크립트가 있는 페이지를 방문하도록 유도
- 위조된 요청: 사용자가 해당 페이지에 접속하면, 웹 브라우저는 사용자의 인증 정보를 포함한 채 공격자가 미리 작성해 둔 위조된 HTTP 요청을 피해자의 웹사이트로 보냄
- 피해 발생: 피해 웹사이트는 이 요청이 정상적인 사용자의 요청이라고 착각하여, 사용자의 계정으로 비밀번호 변경, 송금, 게시글 삭제 등 민감한 작업을 수행
CSRF 공격의 특징
- 인증 정보 탈취 불필요: CSRF 공격은 사용자의 세션 토큰이나 비밀번호를 직접 탈취하지 않고, 사용자가 이미 인증된 상태를 악용하는 방식이다!
- 사용자 행위 위장: 사용자의 브라우저를 통해 악의적인 요청을 보내기 때문에, 서버 입장에서는 정상적인 사용자의 행위로 보일 수 있어 취약
- 피해 범위: 사용자의 권한 내에서 가능한 모든 행위를 위조 가능
CSRF 방어 방법
-
CSRF 토큰: 서버는 사용자의 세션마다 고유한 일회용 토큰을 생성하고, 이를 HTML 폼에 숨겨 보냄
-
요청 검증: 사용자가 요청을 보낼 때, 서버는 전송된 토큰과 서버에 저장된 토큰이 일치하는지 확인
-
공격 차단: 공격자는 이 토큰 값을 알 수 없으므로, 위조된 요청 불가
이를 보완한 것이 HTTPS(Secure)다.
HTTPS는 SSL/TLS 프로토콜을 통해 데이터를 암호화해 전송한다. 브라우저와 서버는 먼저 안전한 암호화 연결을 맺고, 그 위에서 요청과 응답을 주고받는다.
요즘 브라우저는 HTTPS가 아닌 사이트에 접속하면 경고를 띄운다. 그만큼 HTTPS는 웹 보안의 기본이다.
1-2. HTTP 메서드
HTTP는 서버와 클라이언트가 요청과 응답을 주고받는 규약이다.
그러면 어떤 형식으로 주고받나??
요청과 응답은 특정한 구조를 따른다.
예를 들어 클라이언트가 요청을 보낼 때는 이렇게 생겼다:
GET /index.html HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0
Accept-Language: ko-KR- 첫 줄: 요청 메서드, URL 경로, 프로토콜 버전
- 이후: 요청 헤더 (key:value 형태) → 호스트, 브라우저 정보, 언어 등
위와 같이 클라이언트가 요청을 보낸다면,
서버는 응답을 해준다.
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2023 14:28:02 GMT
Server: Apache
Content-Type: text/html
<html>
...
</html>
- 첫 줄: 프로토콜 버전 + 상태 코드
- 이후: 응답 헤더 (서버, 콘텐츠 타입 등)
- 마지막: 실제 데이터 (HTML, JSON, 이미지 등)
이는 실제 웹사이트를 통하여 두 눈으로 직접 확인해보는 것이 더 좋다.
당장 Google에 들어가기만 해도 개발자도구의 Network에서 다음 자료들을 주고받으며 200 OK 응답이 나온 것을 확인할 수 있다.
주요 HTTP 상태 코드 분류
그리고 일반적으로 Success에 대한 코드는 200번대를 사용하는데,
이 때 다양한 응답 코드가 존재하니 첨부하겠다.
- 1xx (정보 응답): 요청을 받았으며, 작업을 계속 진행 중이라는 것을 나타냅니다.
- 100 Continue: 서버가 요청의 첫 부분을 받았고, 클라이언트가 나머지 요청을 계속 보내야 함을 나타냅니다.
- 2xx (성공 응답): 클라이언트의 요청이 성공적으로 처리되었음을 나타냅니다.
- 200 OK: 요청이 성공적으로 완료되었습니다.
- 201 Created: 요청이 성공적으로 처리되어 새로운 리소스가 생성되었습니다.
- 204 No Content: 요청이 성공했지만, 응답 본문에 보낼 내용이 없습니다.
- 3xx (리다이렉션): 클라이언트가 요청을 완료하기 위해 다른 위치로 이동해야 함을 나타냅니다.
- 301 Moved Permanently: 요청된 리소스의 URI가 영구적으로 변경되었습니다.
- 302 Found: 요청된 리소스의 URI가 일시적으로 변경되었습니다.
- 304 Not Modified: 클라이언트가 가진 캐시된 응답이 유효하며, 다시 전송할 필요가 없음을 나타냅니다.
- 4xx (클라이언트 오류): 클라이언트의 요청에 문법적 오류가 있거나, 요청을 처리할 수 없음을 나타냅니다.
- 400 Bad Request: 잘못된 문법으로 인해 서버가 요청을 이해할 수 없습니다.
- 401 Unauthorized: 클라이언트가 요청된 응답을 얻기 위해 유효한 인증 자격 증명이 필요합니다.
- 403 Forbidden: 클라이언트가 요청된 콘텐츠에 접근할 권한이 없습니다.
- 404 Not Found: 서버가 요청된 리소스를 찾을 수 없습니다.
- 5xx (서버 오류): 서버가 유효한 요청을 처리하지 못했음을 나타냅니다.
- 500 Internal Server Error: 서버에 오류가 발생하여 요청을 수행할 수 없습니다.
- 502 Bad Gateway: 게이트웨이 또는 프록시 역할을 하는 서버가 업스트림 서버로부터 잘못된 응답을 받았습니다.
- 503 Service Unavailable: 서버가 일시적으로 요청을 처리할 수 없습니다. (유지보수 또는 과부하)
1-3. HTTP의 버전
이번에는 HTTP가 발전해 온 과정을 확인할 수 있는 HTTP 버전에 대하여 알아보자.
- HTTP/0.9 (1991)
- GET 메서드만 지원
- 헤더 없음
- 요청 예시
GET /index.html - 응답 예시
<html> <body>Hello World</body> </html> - 한계
- HTML 외 다른 리소스 전송 불가 (이미지, JSON 같은 건 불가능)
- 상태 코드도 없어서 성공/실패 구분이 어려움
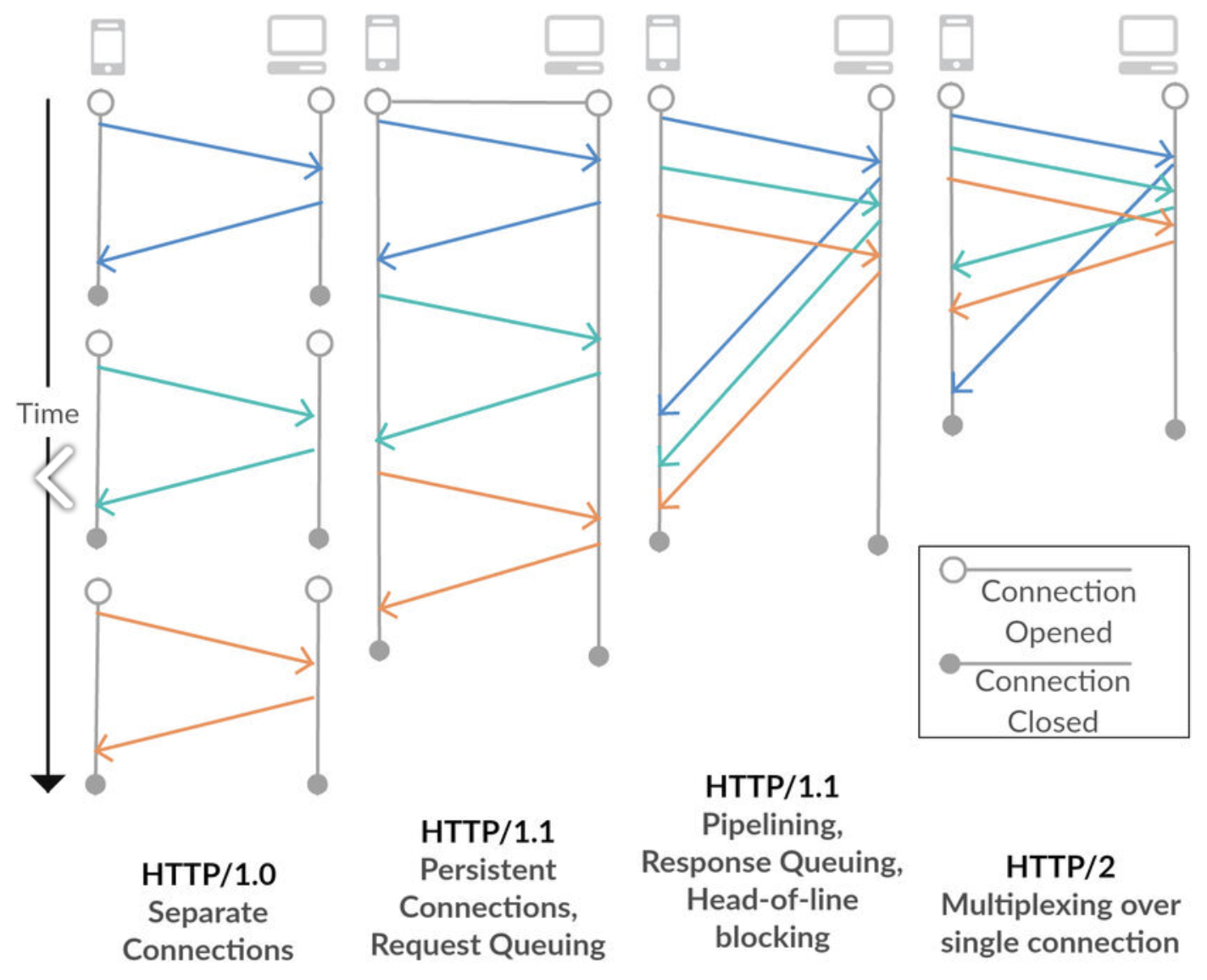
- HTTP/1.0 (1996)
- 메서드, 헤더, 상태 코드 추가
- 단기 커넥션 방식 → 요청 1개당 연결 1개 (성능 저하 발생) (= Overhead)
- 그래서인지 대량의 이미지나 파일이 있는 웹페이지에서 느리다!
- HTTP/1.1 (1997)
- 기본적으로 지속 연결(Persistent Connection) 지원 → 여러 요청을 하나의 TCP 연결에서 처리 가능
- 파이프라이닝(Pipelining) 지원 → 응답을 기다리지 않고 여러 요청을 연속 전송 가능 (하지만 Head-of-Line Blocking 문제로 잘 안 씀)
- 새로운 메서드 추가: PUT, DELETE, OPTIONS, TRACE
- Host 헤더 필수화 → 하나의 서버에서 여러 도메인 호스팅 가능(가상 호스팅)
- 캐싱 메커니즘 강화 (Cache-Control, ETag 등)
- 청크 전송(Chunked Transfer Encoding) → 응답 크기를 미리 알지 못해도 전송 가능
HTTP/1.1의 장점은 웹이 폭발적으로 성장할 수 있었던 기반이자,
지금도 전 세계 대부분의 서비스에서 사용한다는 점이다.
그래서 이런 지속적인 연결을 지원해서 주기적인 SSE나, 웹 소켓 설정할 때 HTTP 1.1로의 설정을 체크해줘야한다.
proxy_set_header Connection 'keep-alive';
proxy_http_version 1.1;- HTTP/2 (2015)
- 성능 개선 버전
- 바이너리 프레이밍 계층 → 전송 속도 향상
- 멀티플렉싱 지원 → 하나의 연결에서 여러 요청/응답 병렬 처리
- 헤더 압축 (HPACK)
- HTTP/3 (2019~)
- TCP 대신 UDP 기반 QUIC 프로토콜 사용
- 기존 TCP의 지연 문제(RTT)를 해결
- 점점 보급 확산 중
그래서 IP가 바뀌면 세션을 이어갈 수 있다(모바일에서 유리)
지연 시간이 줄어들어서 "실시간 서비스(스트리밍, 게임, 화상통화)에 적합
UDP 기반이라서 방화벽, 네트워크 장비에서 차단되는 경우가 아직은 존재한다(보안그룹에서 TCP만 ON해주었을 때 )
1-4. HTTP의 헤더 구조와 역할
HTTP 메시지는 크게 네 부분으로 나뉜다.
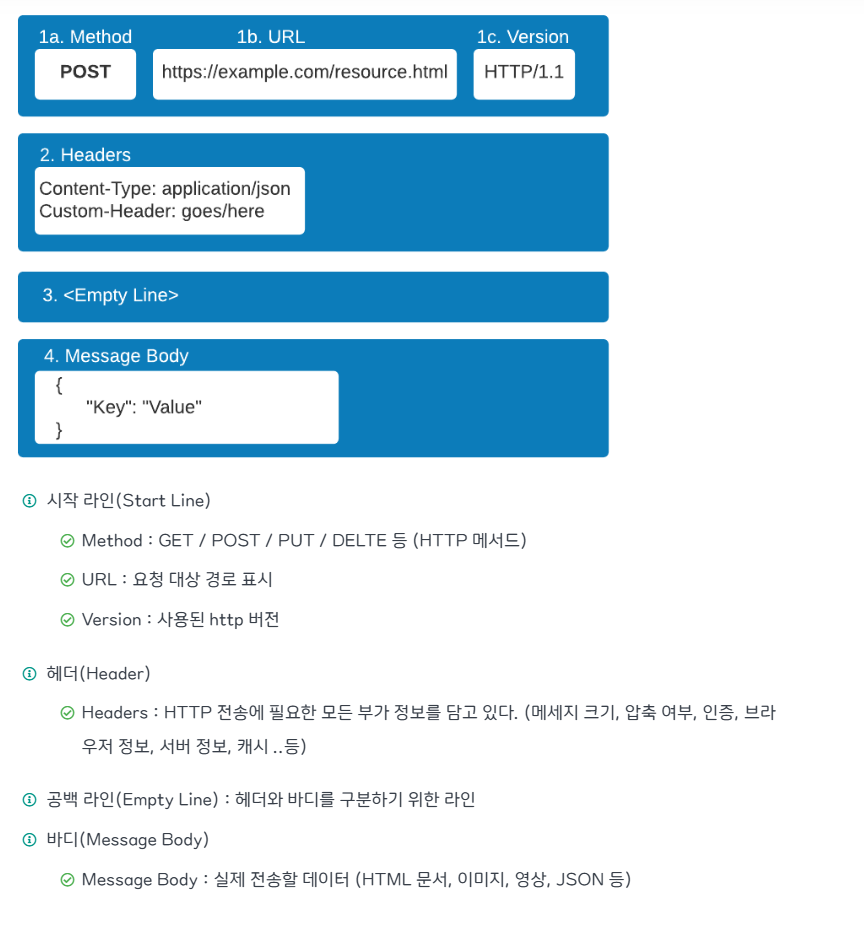
위와 같은 사진을 보면 크게 시작, 헤더, 그리고 공백, 메시지 로 나뉜다.
- 시작 라인(Start Line) : 요청이라면 메서드, 경로, 프로토콜 버전이 들어간다.
예: GET /index.html HTTP/1.1
응답이라면 프로토콜 버전과 상태 코드가 들어간다.
예: HTTP/1.1 200 OK
- 헤더(Header)
key:value 형태의 쌍으로 구성된다.
요청 헤더에는 브라우저 정보, 언어, 인증 토큰 등 클라이언트가 서버에 알려야 하는 정보가 담긴다.
응답 헤더에는 서버 정보, 콘텐츠 타입, 캐싱 관련 지시어 등이 담긴다.
- 공백 라인(Empty Line)
헤더와 본문을 구분하기 위해 반드시 필요하다.
단순히 보기 편하라고 넣는 게 아니라 HTTP 프로토콜 규약에 포함된 필수 요소다.
- 메시지 바디(Message Body)
실제 데이터가 담기는 부분이다.
HTML, JSON, 이미지, 파일 등 요청이나 응답의 본문 데이터가 여기에 들어간다.
다만 모든 요청에 바디가 포함되는 건 아니다. 예를 들어 GET 요청은 보통 바디를 포함하지 않는다.!
2. 인증/인가 방식
그렇다면 웹에서 인증 및 인가 방식은 당연히 신원 확인을 위해서 필요할 것이다.
특정 리소스에 접근을 하려고할 때,
인증의 과정이 분명히 필요할 것이고,
인가의 방식을 통하여 접근 권한이 있는지 없는지에 대한 확인이 필요할 것이다.
웹 서비스에서 "누가 로그인했는지"를 서버가 식별하는 건 굉장히 중요한 일이다.
이를 위해 쿠키 기반 인증, 세션 기반 인증, 토큰 기반 인증(JWT 등) 세 가지 방식이 주로 사용된다. 각각의 개념과 장단점을 살펴보자.
2-1. 쿠키 기반 인증
쿠키는 브라우저에 저장되는 작은 데이터 조각으로, Key-Value 형태를 가진다.
사용자가 특정 사이트에 접속하면 서버가 쿠키를 내려주고, 이후 브라우저는 모든 요청마다 해당 쿠키를 서버에 함께 보낸다.
쿠키의 특징
- 클라이언트가 서버에 접속한다.
- 서버가 응답 헤더의 Set-Cookie에 데이터를 담아 브라우저에 전달한다.
- 브라우저는 요청할 때마다 Cookie 헤더에 해당 값을 담아 서버로 보낸다.
- 서버는 쿠키 값을 확인하고 사용자를 식별하거나, 맞춤형 서비스를 제공한다.
장점
- 구현이 단순하고 오래전부터 널리 사용됨
- 브라우저에 자동 저장되므로 추가 작업이 필요 없음
단점
- 보안 취약: 요청마다 그대로 전송되므로 탈취·조작 위험 존재
- 저장 용량 제한: 보통 4KB 정도
- 브라우저별로 동작 차이가 있어 공유 어려움
- 쿠키가 커질수록 네트워크 부하 발생
https://www.flonidan.dk/cookie-information
2-2. 세션 기반 인증
이러한 쿠키의 보안적인 이슈 때문에, 세션은 비밀번호 등 클라이언트의 민감한 인증 정보를 브라우저가 아닌 서버 측에 저장하고 관리한다.
그렇게 등장한 것이 세션 방식이다.
쿠키의 보안 문제를 보완하기 위해 등장한 방식.
민감한 정보는 서버에 저장하고, 브라우저에는 단순히 세션 ID만 쿠키 형태로 남긴다.
즉, 서버가 상태를 유지(Stateful) 하면서 클라이언트를 식별한다.
세션 기반의 특징
- 사용자가 로그인하면 서버가 세션 객체를 생성한다.
- 세션 ID를 쿠키(JSESSIONID)에 담아 클라이언트에 전송한다.
- 브라우저는 이후 요청마다 해당 세션 ID 쿠키를 전송한다.
- 서버는 세션 저장소(메모리, 파일, DB 등)에서 세션 ID를 조회해 사용자 인증 상태를 확인한다.
- 로그아웃 시 서버에서 세션을 삭제한다.
장점
- 민감한 정보를 브라우저에 직접 저장하지 않는다! 그래서 보안상 비교적 안전하다
- 쿠키 조작으로 얻을 수 있는 정보가 제한적이다.
단점
- 서버 메모리/DB에 세션을 저장해야해서 서버 자원이 부담된다
- 사용자 수가 늘어나면 성능 저하 및 확장성 문제가 발생한다
- 서버를 여러 대 운영하다 보면 세션 동기화의 문제가 발생한다(DB 상의 문제라든가, 로드밸런싱이 굉장히 복잡해짐)
2-3. 토큰 기반 인증(JWT 등 )
이제 토큰 방식에 대하여 알아보자.
토큰 방식은 최근에 가장 많이 사용되는 방식이다.
로그인 시 서버가 토큰(JWT 등)을 발급하고, 클라이언트는 이를 저장했다가 요청마다 Authorization 헤더로 전달한다.
서버는 별도의 세션 저장 없이 토큰 자체를 검증해 사용자 상태를 확인한다.
즉, 서버가 상태를 유지하지 않음(Stateless) 이 특징이다.
토큰 방식의 특징
토큰 방식의 흐름을 알기 위해 예를 들어 JWT와 같은 외부 토큰을 사용한다고 가정해보자.
- 사용자가 로그인 → 서버가 JWT(Access Token, Refresh Token)를 발급한다.
- 클라이언트는 Access Token을 브라우저에 저장하고 요청마다 Authorization: Bearer 형태로 보낸다.
- 서버는 토큰을 검증하고 사용자 인증 상태를 판단한다.
- Access Token이 만료되면 Refresh Token을 이용해 재발급 받는다.
장점
- 서버에 세션 상태를 저장하지 않아서 수평 확장에 유리하다! (로드 밸런싱이 간편)
- 모바일 앱, 프론트 백 분리 구조나 RESTful API 환경에 최적화 되어있다.
- JSON 기반으로 다양한 정보를 담을 수 있다(UserID나 권한 등)
단점
- 토큰이 탈취되면 그대로 악용 가능
- 로그아웃 처리가 어려움. 블랙리스트 관리가 필요
- 토큰이 커질수록 요청 헤더가 무거워진다!
AccessToken vs RefreshToken
- Access Token
- 유효 기간이 짧다.
- 요청마다 Authorization 헤더에 담아 사용.
- 브라우저/앱에서 직접 접근 가능.
- Refresh Token
- 유효 기간이 길다.
- 보안 강화를 위해 쿠키(HTTP Only, Secure 설정)에 저장.
- Access Token 만료 시 새로운 토큰을 발급받는 용도로 사용.
public void removeRefreshTokenCookie(HttpServletResponse response, long memberId) {
Cookie refreshTokenCookie = new Cookie("refreshToken", null);
refreshTokenCookie.setHttpOnly(true);
refreshTokenCookie.setSecure(true);
refreshTokenCookie.setPath("/");
refreshTokenCookie.setMaxAge(0); // 즉시 만료
response.addCookie(refreshTokenCookie);
}정리
| 방식 | 서버 상태 관리 | 장점 | 단점 |
|---|---|---|---|
| 쿠키 | 클라이언트 저장 | 구현 간단, 자동 관리 | 보안 취약, 용량 제한 |
| 세션 | 서버에 저장 (Stateful) | 보안 강화, 쿠키보다 안전 | 서버 부하, 확장성 문제 |
| 토큰(JWT) | 서버 저장 없음 (Stateless) | 확장성 우수, API 환경 최적 | 토큰 탈취 위험, 로그아웃 처리 어려움 |
그러면 이제 웹 통신을 위한 API에 대한 개념을 알아보자.
3. 웹 API 설계
3-1. API란?
API란, Application Programming Interface의 약자로,
클라이언트와 서버 간 통신에 필요한 것으로 이해하면 된다.
그런데 이 Interface, 어디서 많이 보지 않았나?
인터페이스는 간단히 말해,
어려운 것은 감추고 보다 쉽게 상호작용 할 수 있도록 해주는 것들로,
API는 정확히 말하면 어플리케이션을 프로그래밍 할 때 보다 쉽게 할 수 있도록 해주는 규약이자 도구들이라고 생각하면 된다.
## 3-2. REST API
REST는 Representational State Transfer의 약자로,
HTTP 기반으로 하는 웹 서비스 아키텍처를 의미하고 HTTP 메소드와 자원을 이용해 서로 간의 통신을 주고 받는 방법이다.
- API Endpoint
REST API에서는 API Endpoint라는 개념이 존재하는데,
해당 API를 호출하기 위한 HTTP 메서드, 그리고 URL을 포함한다!
3-3. HTTP 메서드
- GET : 조회
- POST : 생성
- PUT : 갱신(전체)
- PATCH : 갱신(일부)
- DELETE : 삭제
위의 5개 메소드 중 POST는 새로운 자원의 생성도 있지만,
클라이언트가 특정 정보를 서버로 넘기고 그에 대한 처리를 요청 하는 것을
전부 POST로 처리 가능하다.
## 3-4. RESTful API Endpoint의 설계
이제 RESTful한 API의 설계를 위한 규칙을 알아보자.
RESTful한 API의 Endpoint는 아래의 규칙에 따라 설계가 가능.
- URI에 동사가 포함이 되어선 안된다.
- URI에서 단어의 구분이 필요한 경우 -(하이픈)을 이용한다.
- 자원은 기본적으로 복수형으로 표현한다.
- 단 하나의 자원을 명시적으로 표현을 하기 위해서는 /users/id와 같이 식별 값을 추가로 사용한다.
- 자원 간 연관 관계가 있을 경우 이를 URI에 표현한다.
그러면, 이런 RESTful API 규칙을 왜 지키는 것일까?
아까도 말했지만, REST API는 클라이언트와 서버 간의 통신을 위해 필요한 것들이다.
그렇다면 간단하다!
서로 소통을 잘 하기 위해서이다.
