
일반적 주장:
- 멀티프로세서에 더 많은 쓰레드를 올리자
- 블록에 더 많은 쓰레드를 올리자
왜냐면 이게 레이턴시를 숨기는 유일한 방법이니까!
하지만 아래 두 개념은 잘못되었음
- 멀티쓰레딩이 GPU에서 레이턴시를 숨기는 유일한 방법이다
- 공유메모리가 레지스터만큼 빠르다
레이턴시 숨김 (Hide latency) 란 레이턴시 동안 다른 연산을 수행하여 빠르게 작업을 마치는 것을 말한다.
- 더 적은 쓰레드로 산술 레이턴시를 숨겨보자
산술 레이턴시는 메모리 레이턴시보다 (I/O) 매우 작음. 대략 20사이클/400사이클.
아래와 같이 dependent한 연산은 앞의 연산이 끝나야 수행될 수 있다.

Thread-level parprallelism (TLP) 과 Instruction-leel parallelism (ILP):
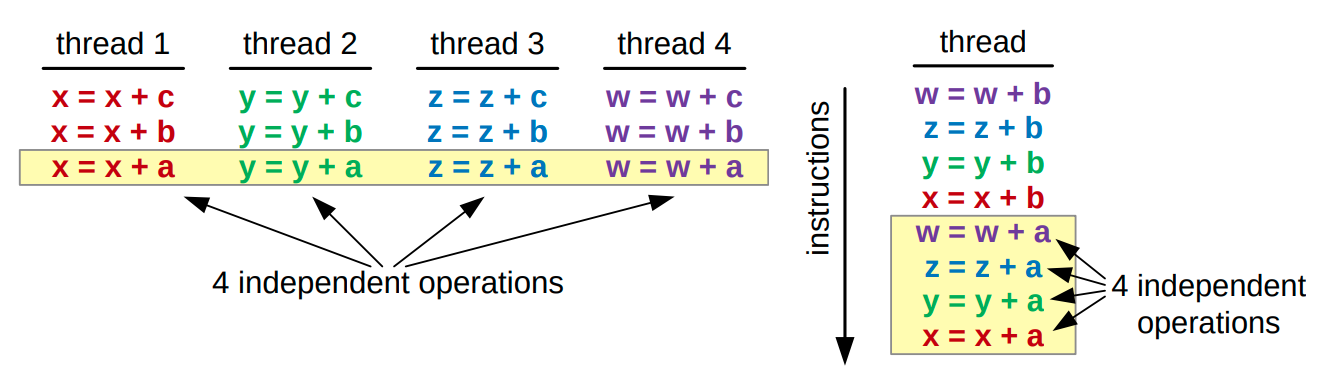
왼: TLP, 오: ILP
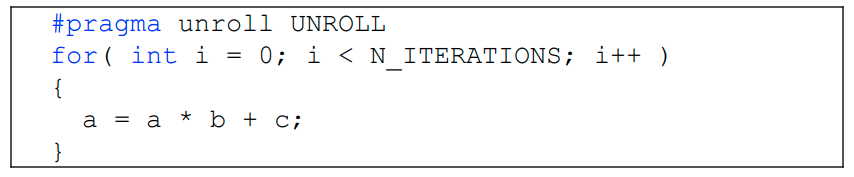
위 예시는 ILP 없이 TLP만을 사용했을 때. 한 스레드에서 처리하기에는 너무너무 가벼운 연산이라 사이클의 낭비임 (idle cycle).

이렇게 ILP=2 를 사용해주면
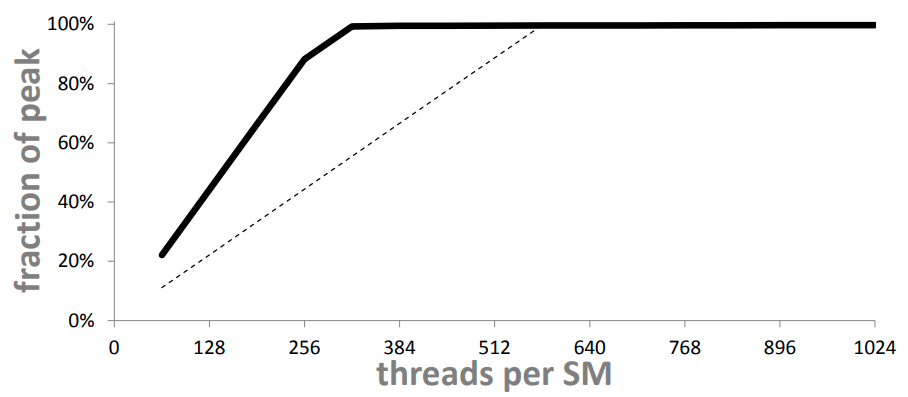
TLP만 쓸 때보다 (점선) 더 적은 쓰레드 개수로 100% 유틸라이즈 가능
ILP를 더 늘리면?
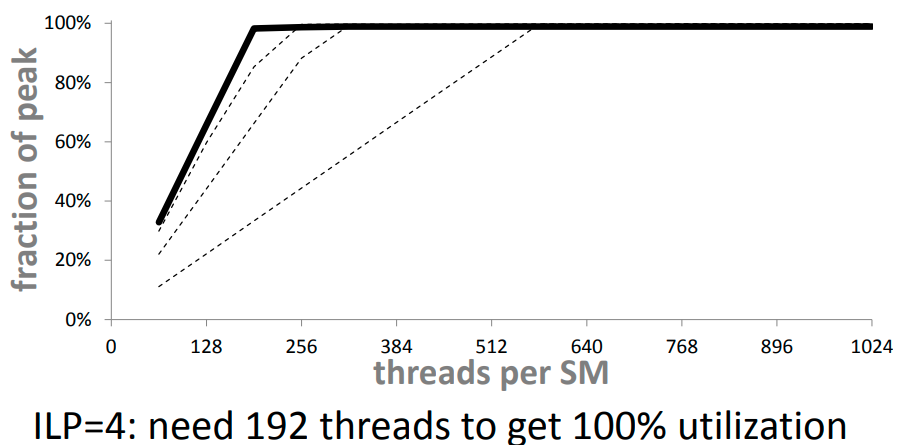
idle cycle인지 어떻게 알지.. 직접 계산하는건가
- 메모리 레이턴시를 숨겨보자
Needed parallelism = Latency x Throughput

음 일단 쓰레드별로 연산을 사이클에 꽉차게 쓰는게 좋다는거
Note, threads don’t stall on memory access
– Only on data dependency
Note, local arrays are allocated in registers if possible

이렇게 float을 카피하는 연산이 있을 때, 한 쓰레드에서 많은 float을 한번에 copy하면 
훨씬 유리함
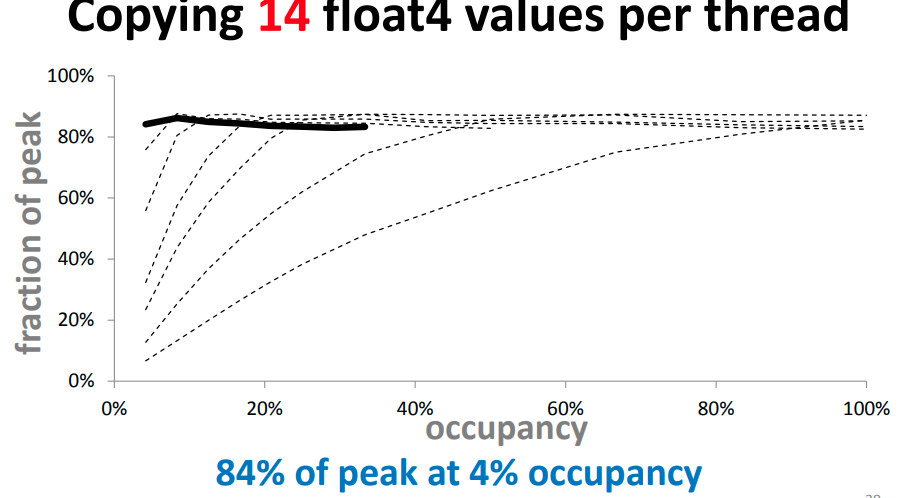
memory intensive kernel 을 만들자!
- 더 적은 쓰레드를 이용해 더 빠르게 돌리기
적은 쓰레드는 곧 각 쓰레드 별로 더 많은 레지스터가 할당됨을 의미.
공유메모리보다 훠어얼씬 빠름 (거의 6배 이상)
워프 내 쓰레드에서 공유메모리에 접근하는건 bank conflicts가 없는 한 거의 레지스터만큼 빠르다는건 잘못된 상식임.
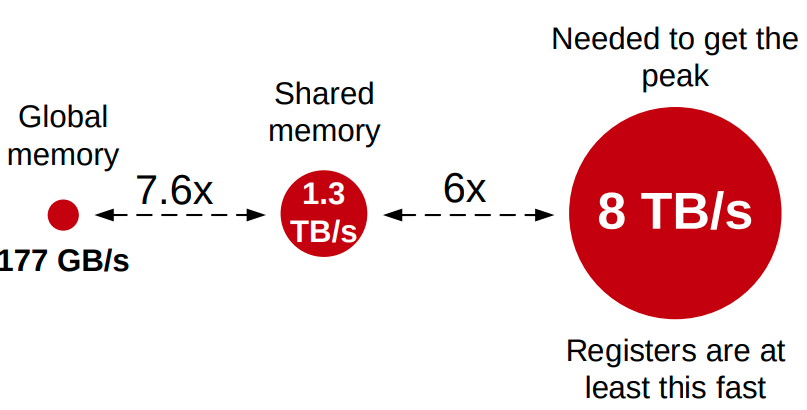
즉 레지스터 활용을 잘 해야 피크에 근접한 성능을 낼 수 있음.
근데 레지스터를 많이 할당하는건 쓰레드의 낮은 점유를 의미. 근데 괜찮음. 이게 더 빠름.
이는 개별 쓰레드에서 여러개의 아웃풋을 계산함으로써도 달성될 수 있다.
예를 들어
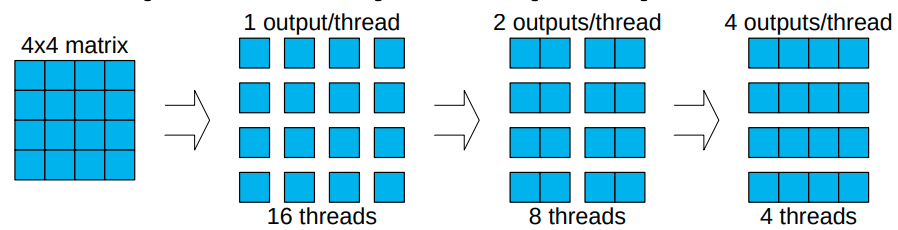
근데 이제 각 쓰레드에서 최대로 쓸 수 있는 레지스터 용량도 정해져있으니까 이건 참고하기
출처: https://www.nvidia.com/content/gtc-2010/pdfs/2238_gtc2010.pdf
