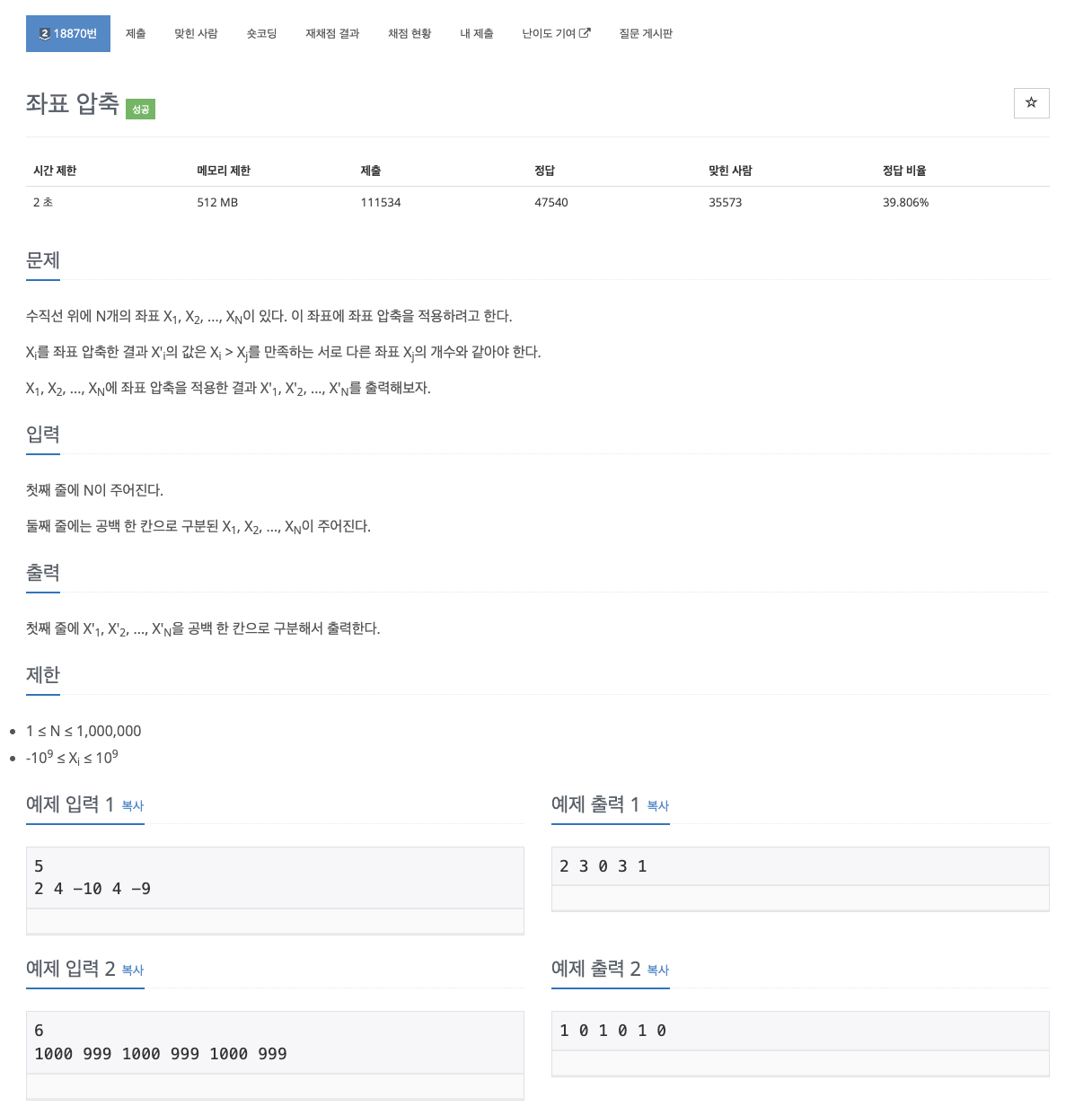
풀이1(이분탐색)
- 주어지는 좌표를 origin 배열에 저장한다.
- origin 배열에서 중복을 제거하고 오름차순으로 정렬한 새로운 배열 temp를 만든다.
- temp 배열에서 이분탐색을 통해 target의 인덱스를 반환한다.
- 중복을 제거하고 정렬하였기 때문에 반환되는 인덱스가 곧 압축된 결과가 된다.
코드1(이분탐색)
package BOJ;
import java.io.*;
import java.util.*;
public class sol18870 {
static int n;
static int[] origin;
static int[] temp;
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
n = Integer.parseInt(br.readLine());
origin = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < n; i++) {
origin[i] = Integer.parseInt(st.nextToken());
}
temp = Arrays.stream(origin)
.distinct()
.sorted()
.toArray();
for (int i : origin) {
int count = binarySearch(i, 0, temp.length);
sb.append(count).append(" ");
}
System.out.println(sb);
}
public static int binarySearch(int target, int left, int right) {
while (left <= right) {
int mid = (left + right) / 2;
if (temp[mid] == target) {
return mid;
} else if (temp[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
}
문제를 풀며..
기본적인 배열 사용법과 이분탐색을 사용하는 쉬운 문제였다.
- 배열의 중복제거나 stream 사용이 미숙하여 찾아보면서 풀이함
- 이분탐색 재귀로 구현하려다가 실패 후 반복문으로 구현
배열을 다루는 다양한 메소드들과 stream, 이분탐색 구현에 대해서 한 번 더 복습을 해야겠다.
풀이2(해시맵)
이분탐색을 사용할 필요도 없이 중복제거 및 정렬 후 temp의 각 요소 및 인덱스 값을 hashMap에 저장하고 origin에 대하여 반복문을 돌면서 hashMap에서 key에 대한 value를 출력해주면 된다.
 첫번째 풀이보다 코드가 간결하지만 hashMap에 추가적으로 저장하기 때문에 메모리 사용량이 더 많다. 미세하지만 시간도 조금 더 걸리는 것을 확인할 수 있다.
첫번째 풀이보다 코드가 간결하지만 hashMap에 추가적으로 저장하기 때문에 메모리 사용량이 더 많다. 미세하지만 시간도 조금 더 걸리는 것을 확인할 수 있다.
코드2(해시맵)
import java.io.*;
import java.util.*;
public class sol18870 {
static int n;
static int[] origin;
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
n = Integer.parseInt(br.readLine());
origin = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < n; i++) {
origin[i] = Integer.parseInt(st.nextToken());
}
int[] temp = Arrays.stream(origin)
.distinct()
.sorted()
.toArray();
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < temp.length; i++) {
map.put(temp[i], i);
}
for (int key : origin) {
sb.append(map.get(key)).append(" ");
}
System.out.println(sb);
}
}
like the water flowing